博文
递归最小二乘循环神经网络
|
引用本文
赵杰, 张春元, 刘超, 周辉, 欧宜贵, 宋淇. 递归最小二乘循环神经网络. 自动化学报, 2022, 48(8): 2050−2061 doi: 10.16383/j.aas.c190847
Zhao Jie, Zhang Chun-Yuan, Liu Chao, Zhou Hui, Ou Yi-Gui, Song Qi. Recurrent neural networks with recursive least squares. Acta Automatica Sinica, 2022, 48(8): 2050−2061 doi: 10.16383/j.aas.c190847
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c190847
关键词
深度学习,循环神经网络,递归最小二乘,迷你批学习,优化算法
摘要
针对循环神经网络(Recurrent neural networks, RNNs)一阶优化算法学习效率不高和二阶优化算法时空开销过大, 提出一种新的迷你批递归最小二乘优化算法. 所提算法采用非激活线性输出误差替代传统的激活输出误差反向传播, 并结合加权线性最小二乘目标函数关于隐藏层线性输出的等效梯度, 逐层导出RNNs参数的迷你批递归最小二乘解. 相较随机梯度下降算法, 所提算法只在RNNs的隐藏层和输出层分别增加了一个协方差矩阵, 其时间复杂度和空间复杂度仅为随机梯度下降算法的3倍左右. 此外, 本文还就所提算法的遗忘因子自适应问题和过拟合问题分别给出一种解决办法. 仿真结果表明, 无论是对序列数据的分类问题还是预测问题, 所提算法的收敛速度要优于现有主流一阶优化算法, 而且在超参数的设置上具有较好的鲁棒性.
文章导读
循环神经网络(Recurrent neural networks, RNNs)作为一种有效的深度学习模型, 引入了数据在时序上的短期记忆依赖. 近年来, RNNs在语言模型[1]、机器翻译[2]、语音识别[3]等序列任务中均有不俗的表现. 但是相比前馈神经网络而言, 也正因为其短期记忆依赖, RNNs的参数训练更为困难[4-5]. 如何高效训练RNNs, 即RNNs的优化, 是RNNs能否得以有效利用的关键问题之一. 目前主流的RNNs优化算法主要有一阶梯度下降算法、自适应学习率算法和二阶梯度下降算法等几种类型.
最典型的一阶梯度下降算法是随机梯度下降(Stochastic gradient descent, SGD)[6], 广泛应用于优化RNNs. SGD基于小批量数据的平均梯度对参数进行优化. 因为SGD的梯度下降大小和方向完全依赖当前批次数据, 容易陷入局部极小点, 故而学习效率较低, 更新不稳定. 为此, 研究者在SGD的基础上引入了速度的概念来加速学习过程, 这种算法称为基于动量的SGD算法[7], 简称为Momen-tum. 在此基础上, Sutskever等[8]提出了一种Nesterov动量算法. 与Momentum的区别体现在梯度计算上. 一阶梯度下降算法的超参数通常是预先固定设置的, 一个不好的设置可能会导致模型训练速度低下, 甚至完全无法训练. 针对SGD的问题, 研究者提出了一系列学习率可自适应调整的一阶梯度下降算法, 简称自适应学习率算法. Duchi等[9]提出的AdaGrad算法采用累加平方梯度对学习率进行动态调整, 在凸优化问题中表现较好, 但在深度神经网络中会导致学习率减小过快. Tieleman等[10]提出的RMSProp算法与Zeiler[11]提出的AdaDelta算法在思路上类似, 都是使用指数衰减平均来减少太久远梯度的影响, 解决了AdaGrad学习率减少过快的问题. Kingma等[12]提出的Adam算法则将RMSProp与动量思想相结合, 综合考虑梯度的一阶矩和二阶矩估计计算学习率, 在大部分实验中比AdaDelta等算法表现更为优异, 然而Keskar等[13]发现Adam最终收敛效果比SGD差, Reddi等[14]也指出Adam在某些情况下不收敛.
基于二阶梯度下降的算法采用目标函数的二阶梯度信息对参数优化. 最广泛使用的是牛顿法, 其基于二阶泰勒级数展开来最小化目标函数, 收敛速度比一阶梯度算法快很多, 但是每次迭代都需要计算Hessian矩阵以及该矩阵的逆, 计算复杂度非常高. 近年来研究人员提出了一些近似算法以降低计算成本. Hessian-Free算法[15]通过直接计算Hessian矩阵和向量的乘积来降低其计算复杂度, 但是该算法每次更新参数需要进行上百次线性共轭梯度迭代. AdaQN[16]在每个迭代周期中要求一个两层循环递归, 因此计算量依然较大. K-FAC算法(Kronecker-factored approximate curvature)[17]通过在线构造Fisher信息矩阵的可逆近似来计算二阶梯度. 此外, 还有BFGS算法[18]以及其衍生算法(例如L-BFGS算法[19-20]等), 它们都通过避免计算Hessian矩阵的逆来降低计算复杂度. 相对于一阶优化算法来说, 二阶优化算法计算量依然过大, 因此不适合处理规模过大的数据集, 并且所求得的高精度解对模型的泛化能力提升有限, 甚至有时会影响泛化, 因此二阶梯度优化算法目前还难以广泛用于训练RNNs.
除了上面介绍的几种类型优化算法之外, 也有不少研究者尝试将递归最小二乘算法(Recursive least squares, RLS)应用于训练各种神经网络. RLS是一种自适应滤波算法, 具有非常快的收敛速度. Azimi-Sadjadi等[21]提出了一种RLS算法, 对多层感知机进行训练. 谭永红[22]将神经网络层分为线性输入层与非线性激活层, 对非线性激活层的反传误差进行近似, 并使用RLS算法对线性输入层的参数矩阵进行求解来加快模型收敛. Xu等[23]成功将RLS算法应用于多层RNNs. 上述算法需要为每个神经元存储一个协方差矩阵, 时空开销很大. Peter等[24]提出了一种扩展卡尔曼滤波优化算法, 对RNNs进行训练. 该算法将RNNs表示为被噪声破坏的平稳过程, 然后对网络的状态矩阵进行求解. 该算法不足之处是需要计算雅可比矩阵来达到线性化的目的, 时空开销也很大. Jaeger[25]通过将非线性系统近似为线性系统, 实现了回声状态网络参数的RLS求解, 但该算法仅限于求解回声状态网络的输出层参数, 并不适用于一般的RNNs训练优化.
针对以上问题, 本文提出了一种新的基于RLS优化的RNN算法(简称RLS-RNN). 本文主要贡献如下: 1) 在RLS-RNN的输出层参数更新推导中, 借鉴SGD中平均梯度的计算思想, 提出了一种适于迷你批样本训练的RLS更新方法, 显著减少了RNNs的实际训练时间, 使得所提算法可处理较大规模数据集. 2) 在RLS-RNN的隐藏层参数更新推导中, 提出了一种等效梯度思想, 以获得该层参数的最小二乘解, 同时使得RNNs仅要求输出层激活函数存在反函数即可采用RLS进行训练, 对隐藏层的激活函数则无此要求. 3) 相较以前的RLS优化算法, RLS-RNN只需在隐藏层和输出层而非为这两层的每一个神经元分别设置一个协方差矩阵, 使得其时间和空间复杂度仅约SGD算法的3倍. 4) 对RLS-RNN的遗忘因子自适应和过拟合预防问题进行了简要讨论, 分别给出了一种解决办法.
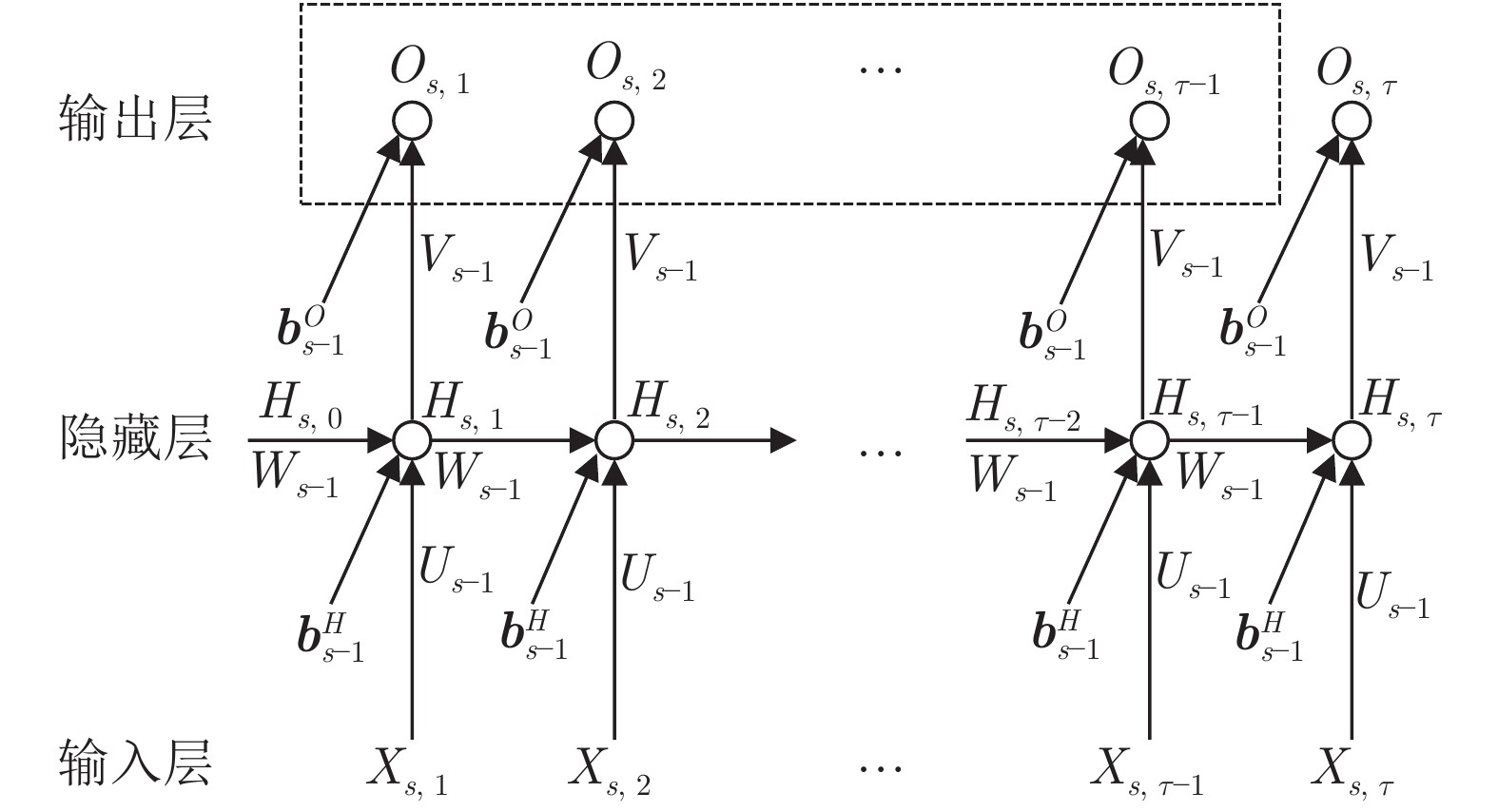
图 1 RNN模型结构
在RNNs优化训练中, 现有一阶优化算法学习速度较慢, 而二阶优化算法和以前的RLS类型优化算法时空复杂度又过高. 为此, 本文提出了一种新的RLS优化算法. 该算法吸收了深度学习中广为应用的迷你批训练学习模式, 在推导过程中我们将研究重点放置在隐藏层和输出层的非激活线性输出上, 通过等价梯度替换, 最终得到各层权重参数的递归最小二乘解. 所提算法只需在RNNs的隐藏层和输出层各添加一个协方差矩阵, 解决了长期以来RLS优化算法应用时需要为隐藏层和输出层的每一神经元设置一个协方差矩阵的问题, 极大地降低了时空复杂度, 使得RLS可以适用于较大规模的RNNs训练. 在此基础上, 采用遗忘因子自适应调整和正则化技术对所提算法作了改进, 进一步提高了所提算法的性能. 4组仿真实验表明, 所提算法在收敛性能、稳定性以及超参数选取的鲁棒性等方面均要明显优于主流一阶优化算法, 能够有效加快RNNs模型的训练速度, 降低超参数的选择难度. 此外, 在实验过程中我们还发现所提算法可缓解梯度消失导致RNNs无法训练的问题. 如何将本算法扩展到RNNs以外的其他深度学习网络以及如何进一步降低所提算法的时空复杂度将是我们下一步工作的重点.
作者简介
赵杰
海南大学计算机科学与技术学院硕士研究生. 主要研究方向为深度学习和强化学习.E-mail: zhaojie@lonelyme.cn
张春元
海南大学计算机科学与技术学院副教授. 2016年获得电子科技大学计算机软件与理论博士学位. 主要研究方向为深度学习与强化学习. 本文通信作者.E-mail: zcy7566@126.com
刘超
海南大学计算机科学与技术学院硕士研究生. 主要研究方向为深度学习与强化学习.E-mail: lcdyx0618@126.com
周辉
海南大学计算机科学与技术学院副教授. 2008年获得中国科学院软件研究所博士学位. 主要研究方向为自然语言处理, 人工智能写作与数据可视化.E-mail: zhouhui@hainanu.edu.cn
欧宜贵
海南大学理学院教授. 2003年获得中国科学技术大学博士学位. 主要研究方向为最优化算法.E-mail: ouyigui@126.com
宋淇
海南大学计算机科学与技术学院硕士研究生. 主要研究方向为深度学习与强化学习.E-mail: songqihnu@163.com
https://blog.sciencenet.cn/blog-3291369-1350446.html
上一篇:基于信息熵的关键链缓冲区设置方法
下一篇:基于预训练表示模型的英语词语简化方法