
需求一年多的发展下来,现在很多大语言模型都支持了更长的上下文,有的甚至可以处理数以百万计的输入输出。
为什么我们需要这么长的上下文呢?其实说白了,就是因为我们比较懒。有些资料非常长,其中大部分信息我们不关心。于是我们希望 AI 能帮我们把关注的两三点内容找出来,总结好,呈现在我们面前。这种感觉就像是点外卖一样——不用冒着严寒酷暑暴雨步入餐馆,在家里点两下手机,就能够吃到热气腾腾的饭菜。
有的小伙伴一听说「懒」字就忙不迭批评,这是不对的。「懒」是一种生存中的能量节省策略,不但有利于个体存活繁衍,也是如今眼花缭乱科技发明的核心驱动力之一。
就拿信息处理来说。我们之前一直念叨「信息过载」,是因为你摄取信息(例如看书、读论文)的速度,赶不上信息产生的速度。如果技术能够帮助我们高效获得信息,那就不仅是解决了「信息过载」的难题,甚至对社会的可持续良性发展,都功莫大焉。
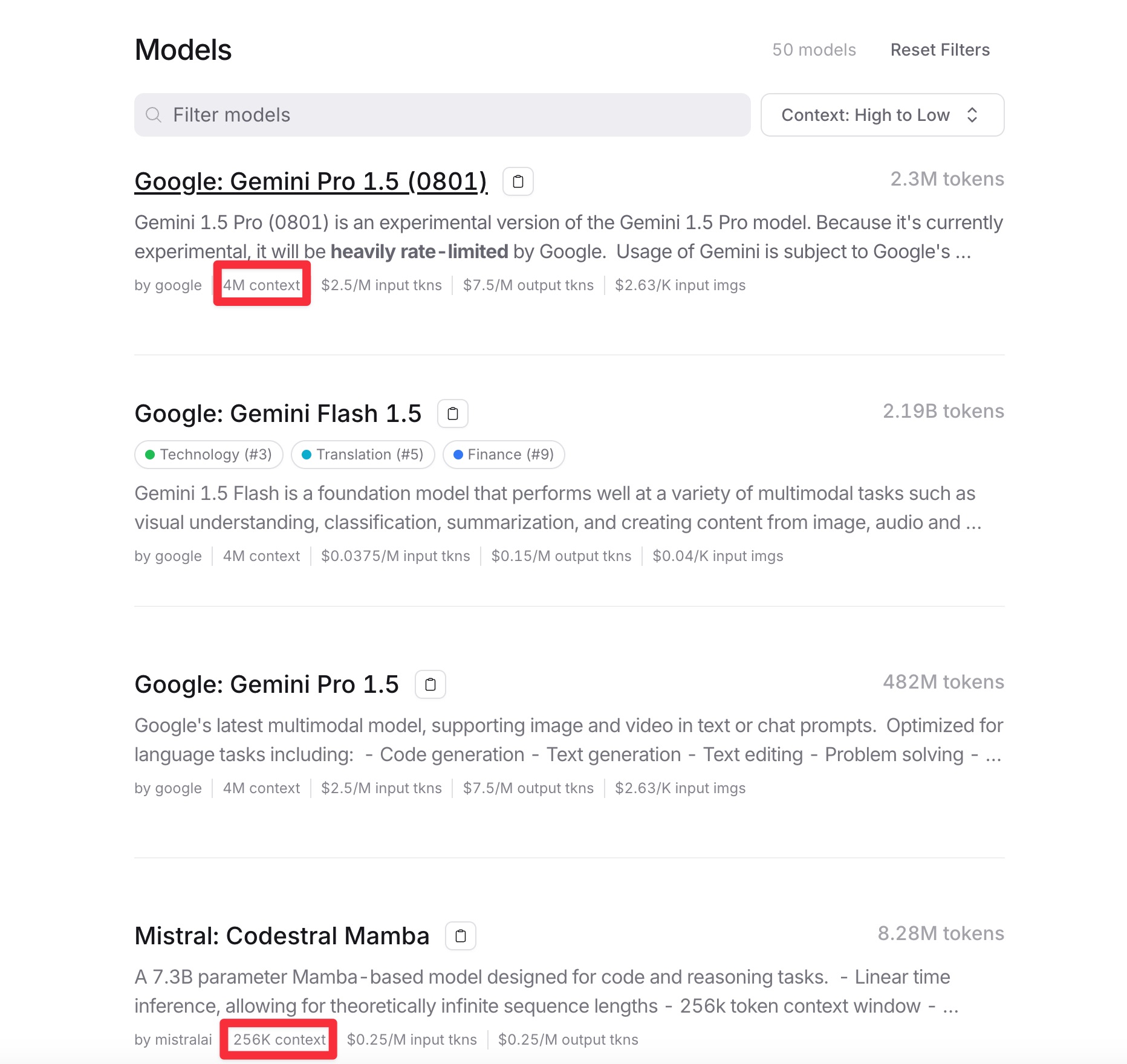
很多大语言模型都声称自己擅长 「大海捞针」。有的还会提供一些对比结果图,来证明自家模型在长上下文中找到用户感兴趣内容能力多么强悍。但是,这些汇报结果未必都是可信的。
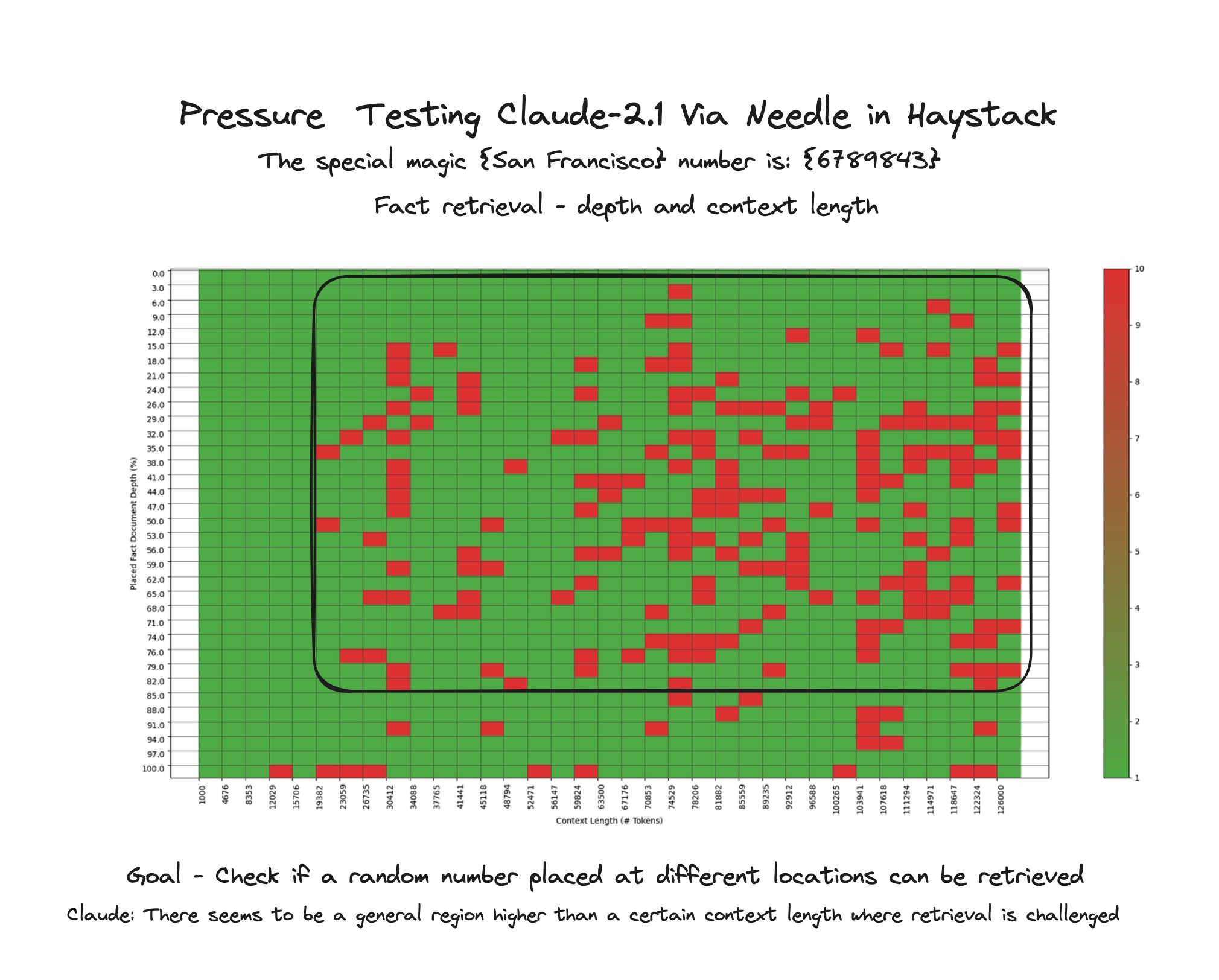
(图片来源:t.ly/Yk8oe)
面对众多产品,普通用户要想充分发挥长上下文的能力,该如何选择呢?如果选择不当,很可能钱花了,需求没有满足。而更可怕的是,大语言模型信誓旦旦传递给你的答案,可能是错的,而你又没能及时辨别,那结果就会很糟糕。
这篇文章中,我选择了一些国内外主流模型进行对比。面对同样的长文档和问题,它们给出的结果究竟是怎样的。
测试论及「长上下文」,我们给大语言模型提供的资料,就应该足够长。一篇论文显得过于简短,咱们还是给它一本书好了。
本来我想找一本学术著作的。考虑到本文的读者未必来自于学术界,所以还是换一本大众读物。最终选择的样例是《股票作手回忆录》。这本书是由杰西·利弗莫尔口述、埃德温·勒菲弗执笔的经典投资自传,记录了利弗莫尔在股票市场的经历和洞见。

我之前读这本书都是纸质版。这次为了进行大语言模型的测试,我特地到亚马逊购买了它的电子版。

之后,我利用 Calibre 把电子档转换成了 txt 文档。具体转换的方式 请参考这篇文章。
文档有了,下面咱们找个问题来问。在我第一次读《股票作手回忆录》时,「老火鸡」这个人就给我留下了非常深刻的印象。

在真如翻译的那个版本中,'position'(头寸)被翻译成了「部位」。这导致了一些读者理解上的困惑,比如「失去我的部位」这样的表述。
「老火鸡」这个老人家具有非凡的定力,给了作者很强的启发,让利弗莫尔更新了自己的交易原则。这个案例也让读者感受到了在波涛汹涌的股市当中,如何才能够尽量地避免损失。
我决定就老火鸡的股市操作策略给大语言模型提出问题。这是个我熟悉的案例,所以验证模型给出的答案轻而易举。
模型怎么选呢?
从模型能力上来讲,现在 LMSys 排名在前几个的包括 Anthropic Claude 3.5 Sonnet, OpenAI GPT-4o 以及 Google Gemini 1.5 Pro。它们在各种自然语言处理任务中表现出色。
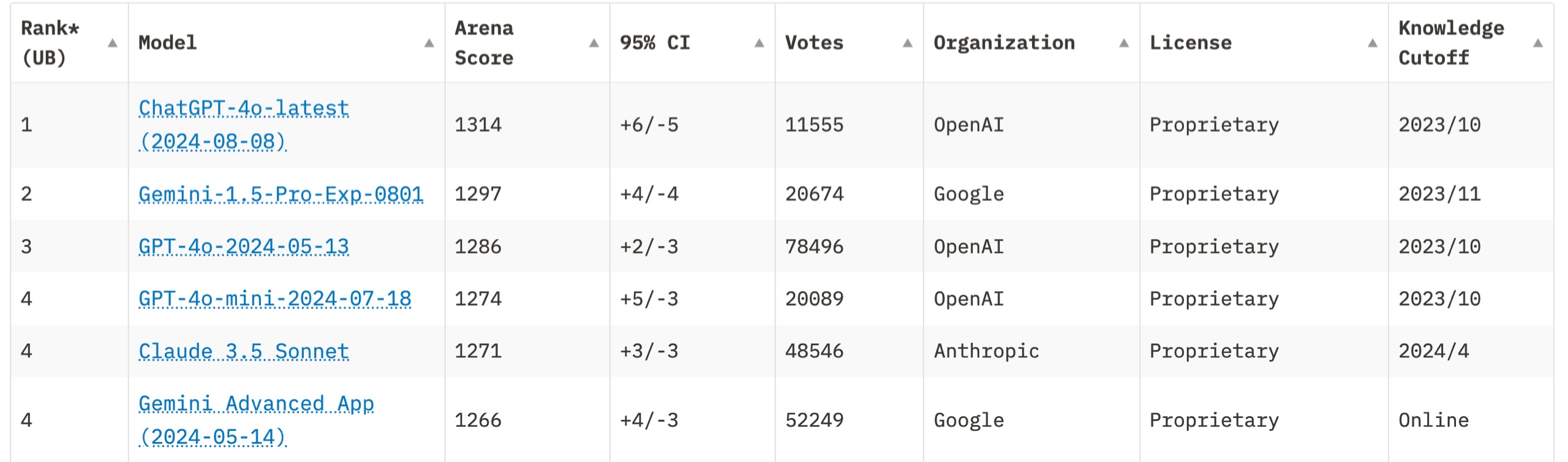
但同时,咱们不能忽略了物美价廉的国产模型。所以我根据近期的口碑感知,把腾讯元宝和 Kimi 也纳入了评测范围。下面咱们一一测试对比。
对比腾讯元宝最近我身边很多小伙伴都对元宝的长文总结能力赞不绝口,于是我首先测试了一下它。
我给出的问题是:
老火鸡如何在股市操作?对你的每一条回答,都要给出原文及其所在位置作为支撑
元宝阅读文档后,很快给出了答案。
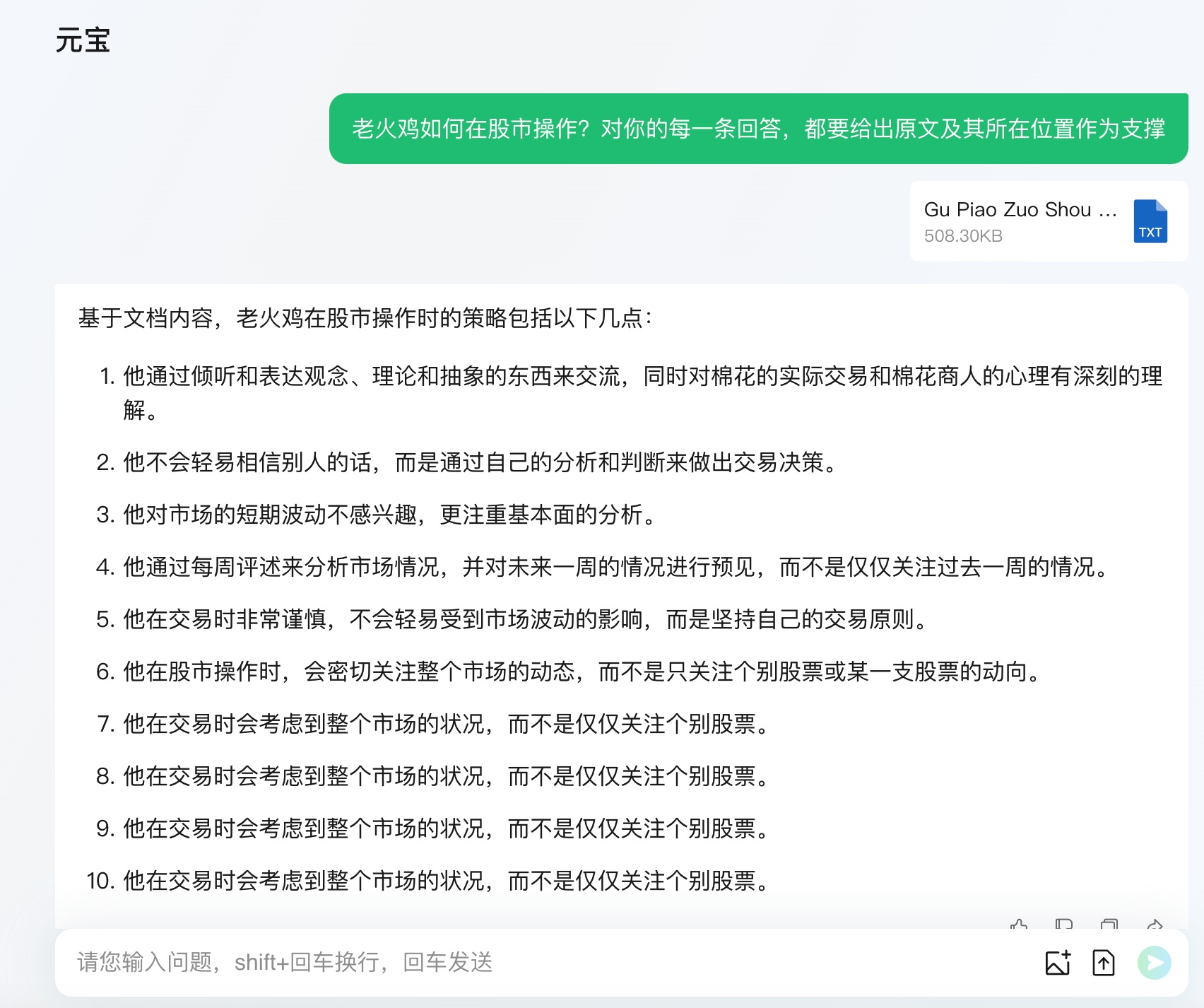
我一眼看过去,便觉得「大失所望」。因为这里答案的 7-10 条,显然是产生了幻觉。
这还不算最糟糕的。回头看过去,元宝答案的第一条也是错误的。因为老火鸡实际操作的,是股票,而不是棉花。

2、3、5、6 不能算错。但是这样的准确率和我的要求还有相当大的差距。
另外,我在提示词里面说得很明白「每一条回答,都要给出原文及其所在位置作为支撑」。我希望的,是 AI 能够引用原文,证明它的论点,这样也有助于用户验证答案的准确性。
我怕是自己的问题没有说清楚,于是干脆把提示词说得更加明确一些:
老火鸡如何在股市操作?对你的每一条回答,都要给出原文具体内容的引用及其所在位置作为支撑
这里我加上了「原文具体内容的引用」。可惜,效果不彰。

你看这个结果,完全没有达到预期效果。AI 根本没有提供任何原文引用来支持它的回答。
更让我哭笑不得的是,尽管提示词发生了变化,元宝给出的回答却和之前完全一样,就连前面答案的错误,页延续到新的回答中。
这,莫非是使用了传说中最新的提示词缓存技术(Prompt caching)?😂

既然提到了 Claude,那咱们干脆就测试一下 Claude 好了。
ClaudeClaude 的测试最为简单 —— 我把文本上传上去后,它直接报错。Claude 说上传的文档超出上下文长度,根本不让执行 😂
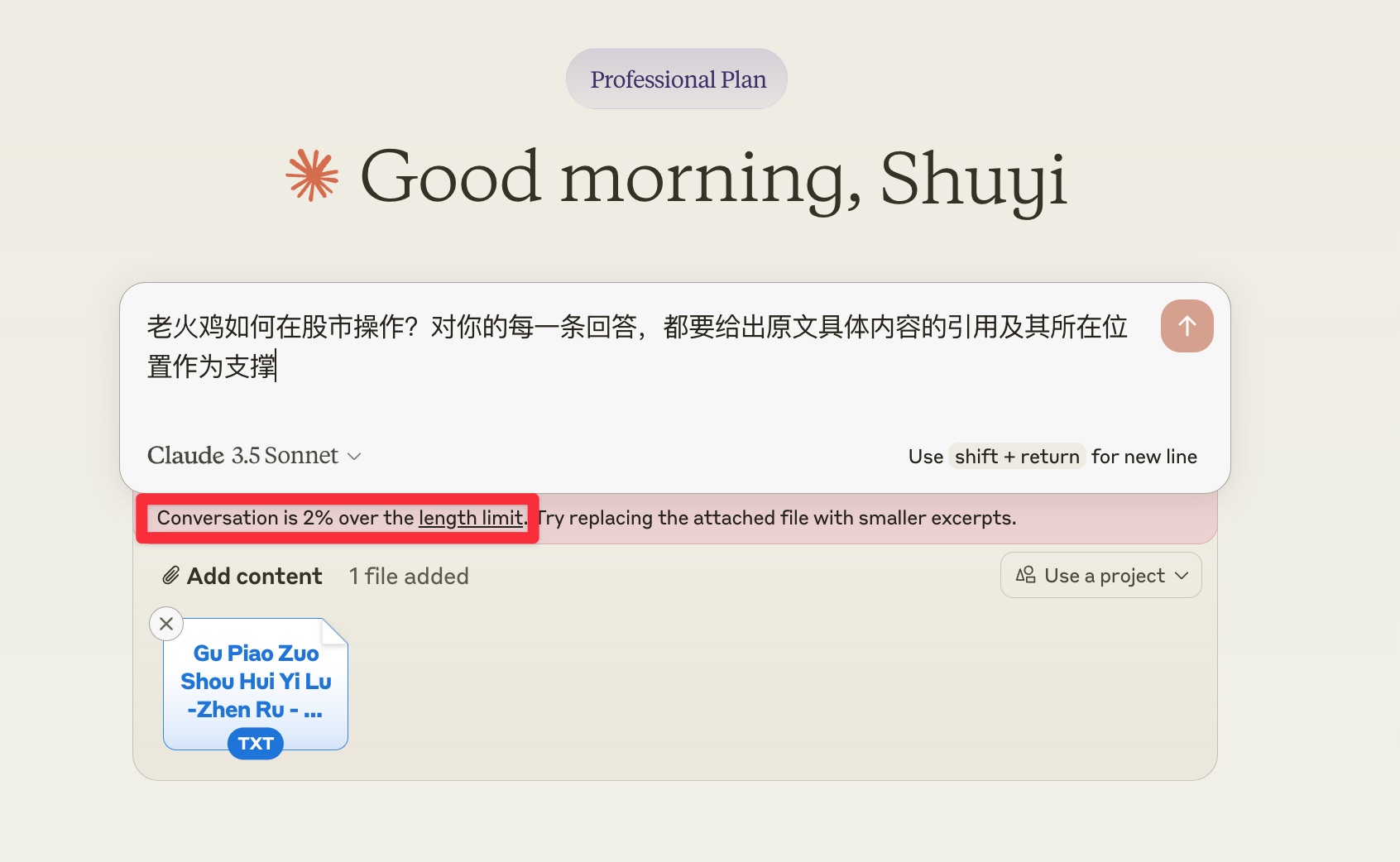
好吧,我直接宣布测试失败。
ChatGPT我在 ChatGPT 官方 App 上传了文本之后,默认用 GPT-4o 来提问。
这次我直接使用了刚刚改进后的提示词,希望得到更准确和详细的回答:
老火鸡如何在股市操作?对你的每一条回答,都要给出原文具体内容的引用及其所在位置作为支撑
这是 GPT-4o 给出的答案:
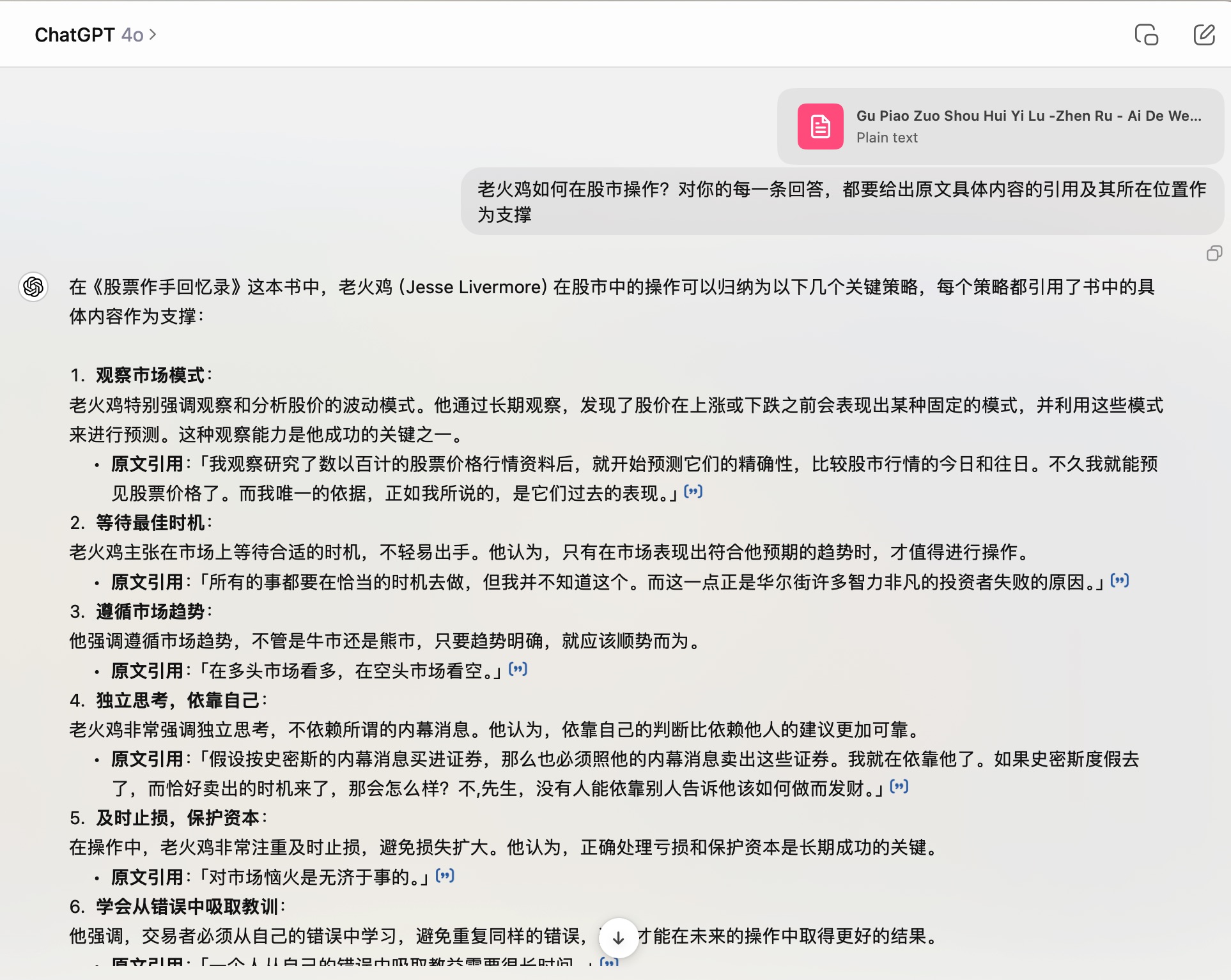
你看,在这里 ChatGPT 确实引用了原文的内容,并且给出了具体的位置(链接形式)。这说明 ChatGPT 的指令理解和遵从要更好。
但是,ChatGPT 回答的结果几乎全是错的,因为他其实是把作者的思考用「老火鸡」来进行了替换。这种张冠李戴,也太明显了。
为了避免单一模型版本的影响,我又选择了 GPT-4 模型,问了同样的问题。
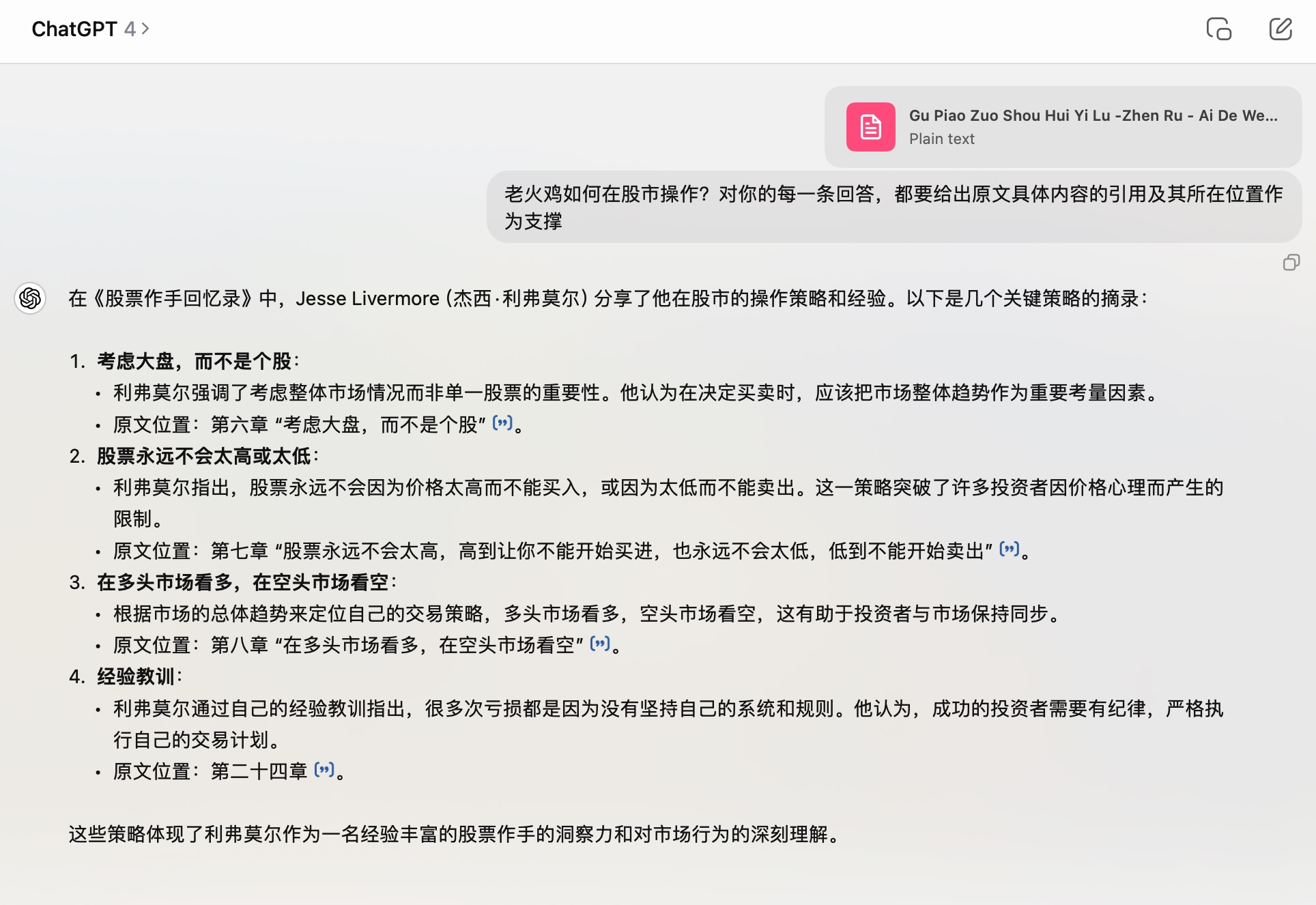
这次你会发现答案很有意思 ——GPT-4 连「老火鸡」这个称谓都不提及了,干脆讲「利弗莫尔」都说过什么。
相对于 GPT-4O,你认为它消除了幻觉了吗?我觉得它确实消除了幻觉。但是对于我的提示词,它压根儿没有遵从。
所以很不幸,ChapGPT 在这一次测试当中也是失败的。
Gemini 1.5 ProLMSys Leader Board 排名前三的模型,只剩下了 Google 的 Gemini 了。
我打开 AI Studio ,选择了 Gemini 1.5 Pro 20240801 版本,提出的问题还是一样的:
老火鸡如何在股市操作?对你的每一条回答,都要给出原文具体内容的引用及其所在位置作为支撑
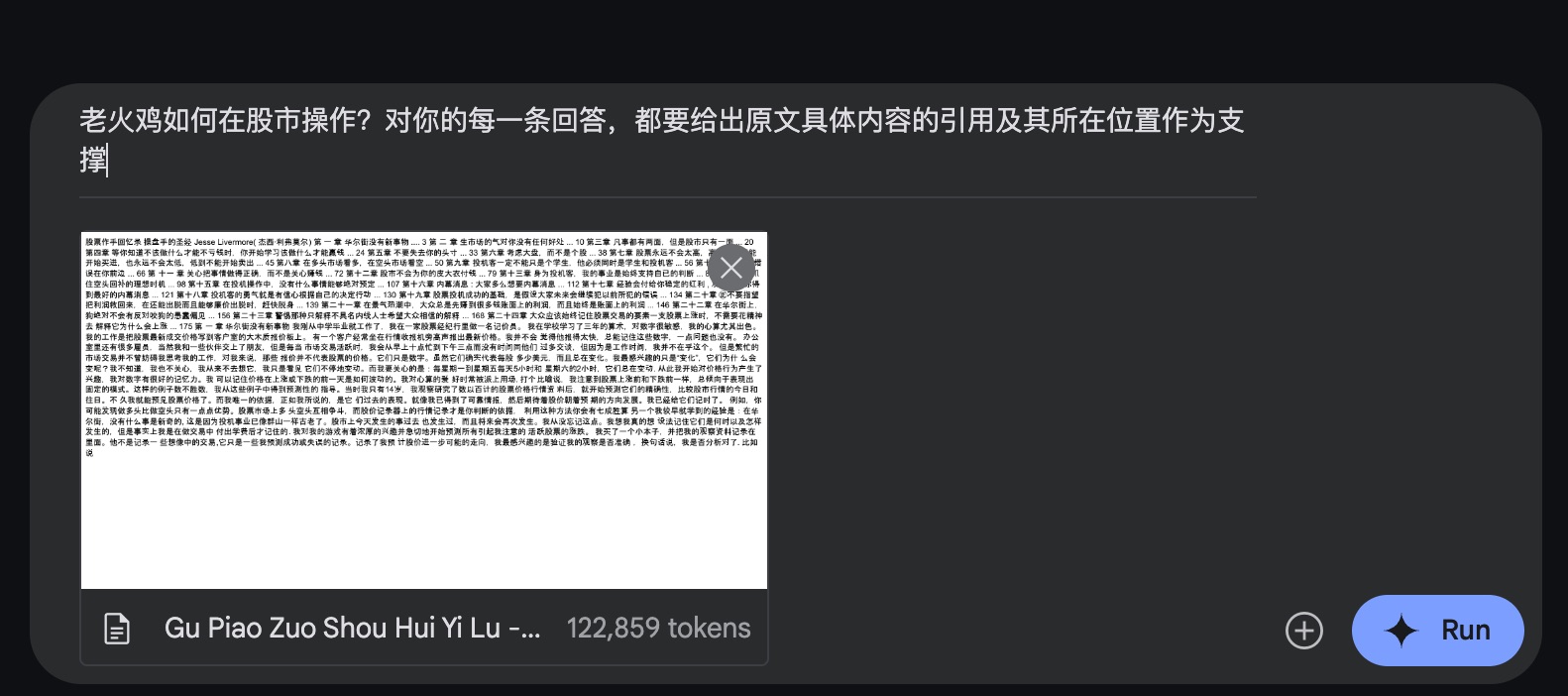
这是 Gemini 1.5 Pro 给出的结果,着实让我眼前一亮。
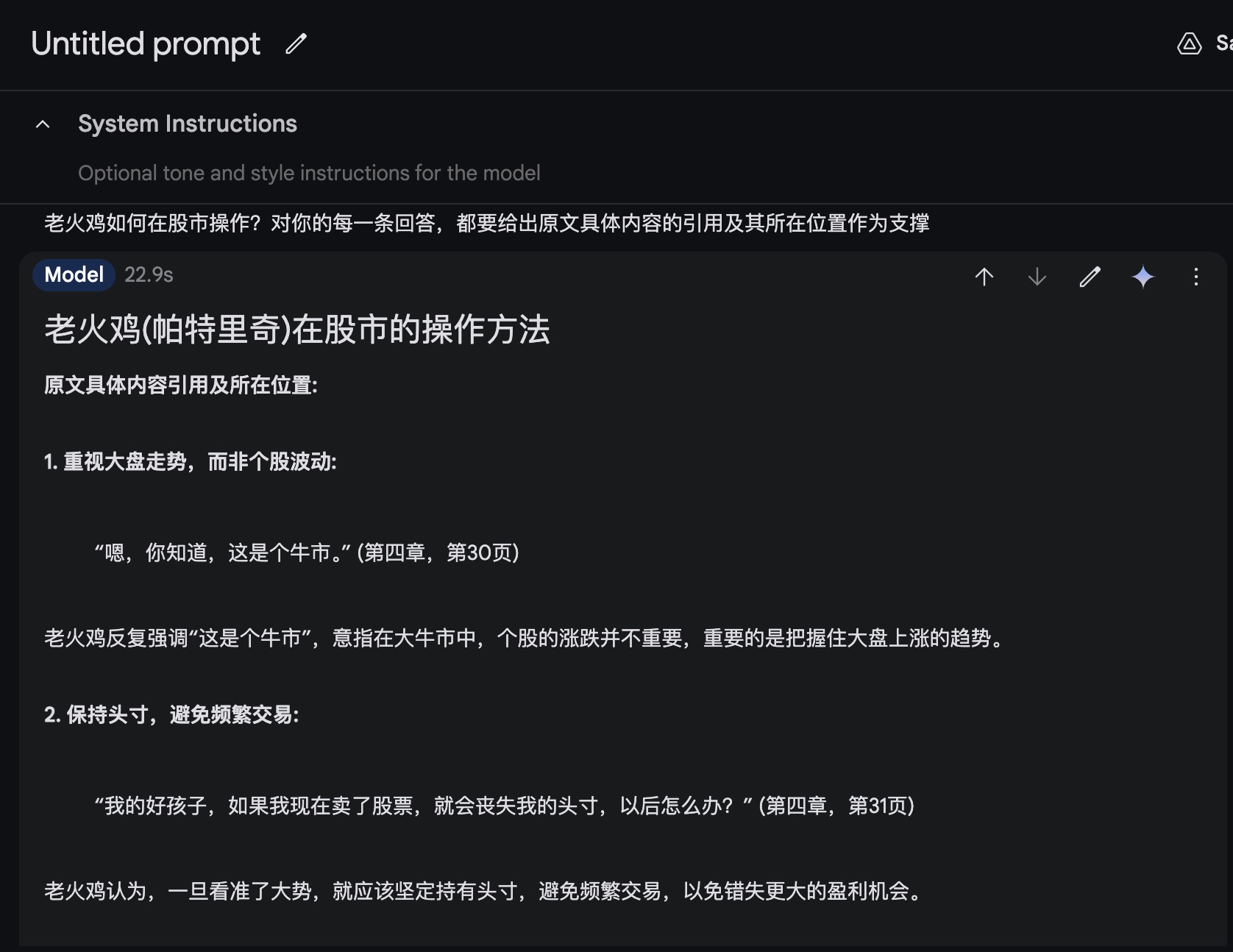
这里 Gemini 说出了一个关键点,就是「老火鸡」看重的是市场的整体,而非个股。然后还强调了投寸的重要性。
这还没完,下面还有 Gemini 继续的回答:
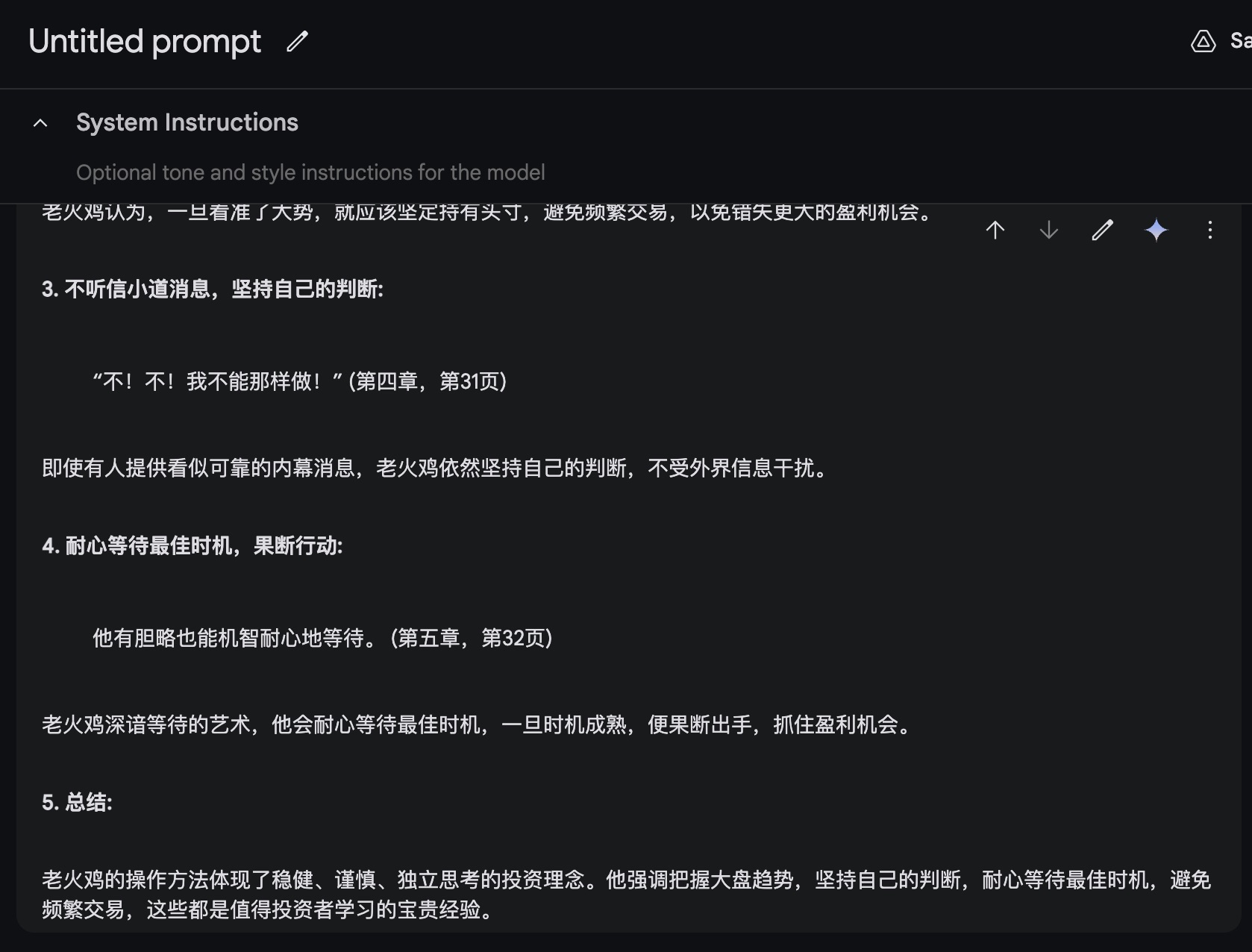
你看 Gemini 还总结出了老火鸡坚持自己的看法,不听信小道消息,耐心等待最佳时机、果断行动等。这些确实都和书中内容一致。
整体的总结里,我没有看到任何的幻觉,Gemini 很好完成了任务。
Kimi 不过,这是不是就意味着我们必须要使用 Gemini 这样的国外模型来进行长文总结提问任务呢?
当然不是。
我把目光又转回了国内的模型。我之前给你介绍过 Kimi,下面咱们也来看看 Kimi 表现如何。我上传了文档,问题和之前一致。
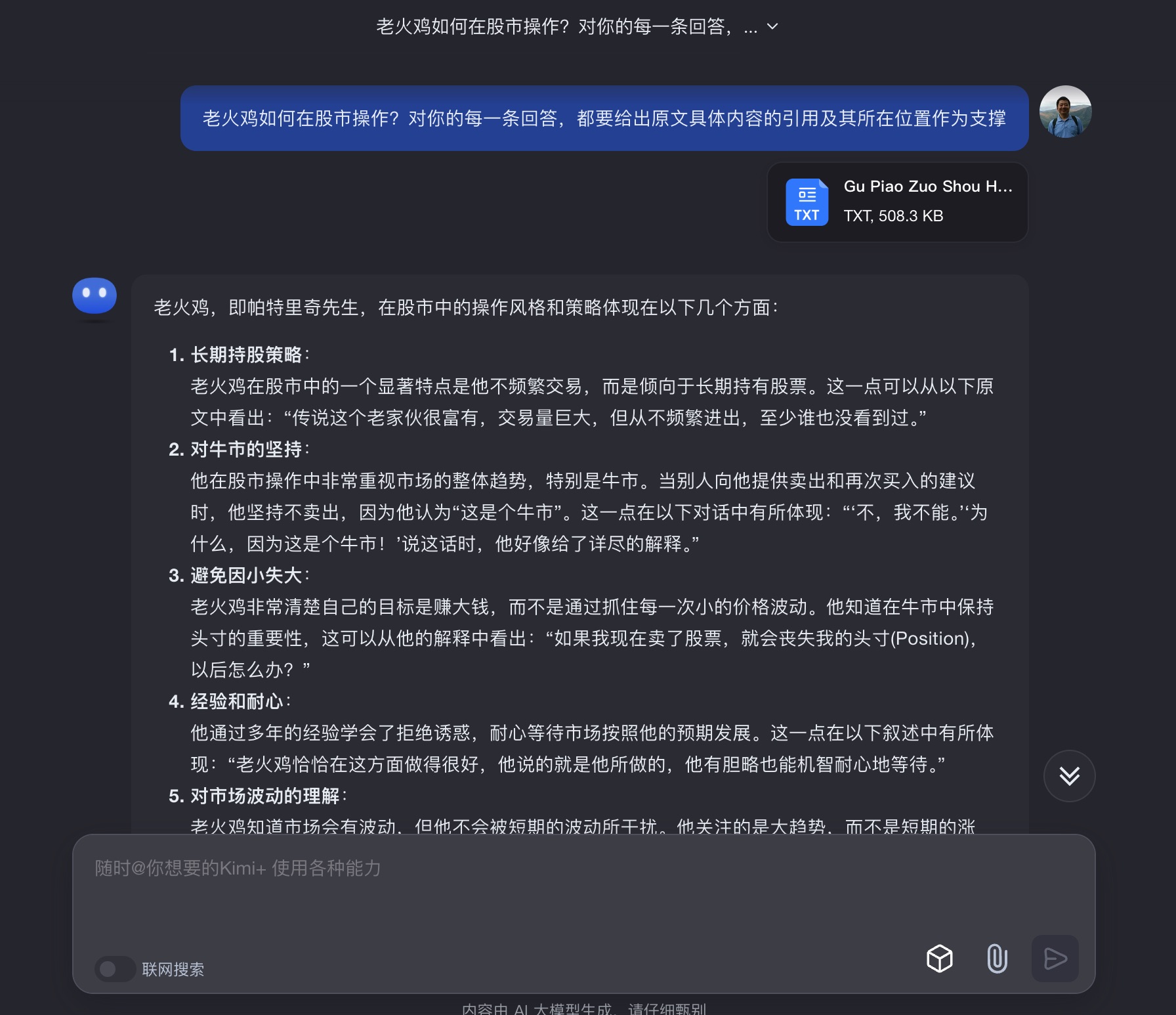
这里 Kimi 首先对人物正名 ——「老火鸡,即帕特里奇先生」。很好嘛。
之后,它总结出了老火鸡的操作风格与策略。包括长期持股策略、对牛市的坚持、避免因小失大、耐心和经验,以及对市场波动的理解。
相当于 Gemini 1.5 Pro,Kimi 没有能够具体指出这些引用原文来自于文档具体章节,这是值得改进的地方。但是 Kimi 能够把原文正确查找和列举出来,也可以帮助用户进行方便验证,同时也尽可能避免了幻觉的产生。
Kimi 的测试结果,通过。
小结小结一下,根据我们的对比测试,目前在长文档中「大海捞针」获得我们关心的答案,并且有效用原文来支撑,Gemini 1.5 Pro 和 Kimi 完成的效果最好。
我们毕竟只测试了五款模型,难免会有疏漏。而且模型的能力都是一直在改进的。我测试的时候模型不好用,不代表你读到这篇文章时,问题依然存在。
所以欢迎你用类似的长文档和问题,尝试一下不同模型的回答效果。如果你找到了更好的模型,或者有独特的发现,欢迎把结果写在留言区分享给大家,我们一起交流讨论。
祝长文档信息快速获取愉快!
如果你觉得本文有用,请点赞。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读
https://blog.sciencenet.cn/blog-377709-1447200.html
上一篇:
GraphRAG + GPT-4o mini 低成本构建 AI 图谱知识库下一篇:
如何用 AI 辅助快速生成概念示意图?