博文
如何用 Llama 3 免费本地 AI 分析数据和可视化?  精选
精选
|
帮助你消除调用大模型 API 带来的数据安全烦恼。
 模型
模型今天我们来探讨一个有趣的话题 —— 如何使用 Llama 3 免费地进行数据分析和可视化。
Meta 团队在 2024 年 4 月发布了两款 Llama 3 新模型,一款是 8B,即 80 亿参数;另一款则是 70B,即 700 亿参数。关于 700 亿参数的模型,我之前已经为你撰写了一篇文章《如何免费用 Llama 3 70B 帮你做数据分析与可视化?》,如果你感兴趣,欢迎点击链接阅读。
咱们今天的讨论重点是较小款 80 亿参数的模型。相比之前的 Llama 2 的同规模模型,它的性能有了显著提升。我们今天将使用一个名为 Ollama 的工具在本地运行这款模型。下面我会向你展示相关的安装和设置方法。
安装首先,你需要 访问 Ollama 的官网。
在网站首页选择下载选项,请确保选择与你操作系统相匹配的版本。例如,我选择了适用于 mac 的版本。如果你使用的是 Windows 或 Linux,应选择相应的版本。

安装过程非常简单,基本上按照常规操作进行即可。在 macOS 上,下载的安装包解压后包含一个可执行文件,你只需将其拖到应用程序文件夹即可完成安装。安装后,你需要进行一些基本设置。
打开程序后,界面会提示你点击 next,然后点击 install,程序将帮助你安装所需的命令行工具。
安装完成后,程序会提供一个默认链接,你可以复制此链接来启动 Llama 2。

但是我们今天的目标是使用 Llama 3,因此我们返回网站首页,寻找关于 Llama 3 的信息。链接在这里。

当你进入模型页面时,页面上会提供详细信息,包括一个下拉框,让你查看各种选项。例如,Latest 标签实际上默认指的就是 8B 模型。
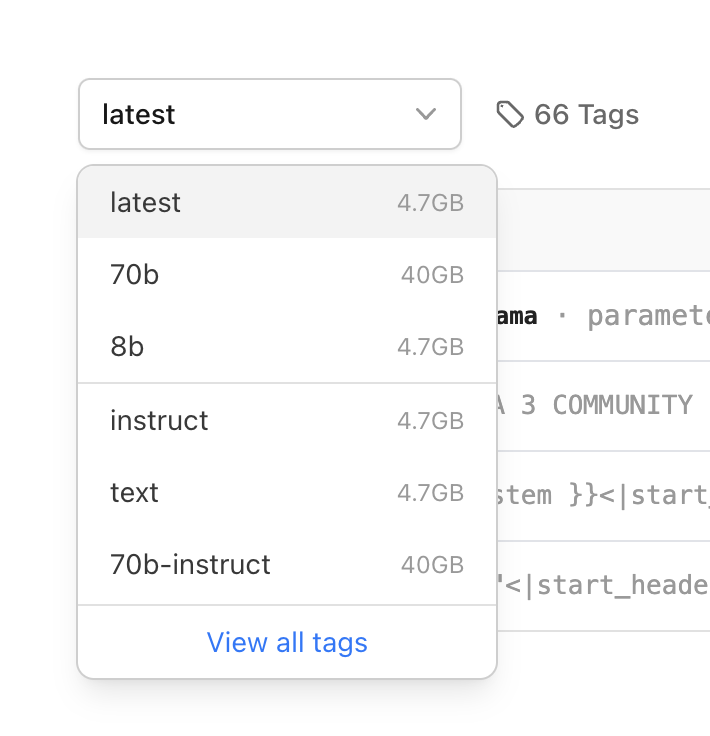
大多数人还是希望在本地运行这种较小的模型。因为 70B 模型虽然功能强大,但仅下载就需 40GB,同时你的机器还需要一定的显存才能运行它。相比之下,8B 模型只需要 4.7GB 的存储空间,占用的显存也只有大约 4GB。

在 M 系列芯片的 Mac 上,内存和显存是统一分配的,所以我这里就不详细区分了。如果你使用的是其他类型的系统,你可能需要区分显存和内存。
在我的机器上,由于只有十几 GB 的内存,所以我认为选择 8B 模型更实际。使用方法是复制界面右侧的命令,然后在终端命令行中执行它。
 执行
执行打开终端,输入:
ollama run llama3系统会自动帮你下载相关的文件。

稍等片刻文件下载完成后,系统会帮你删除所有不需要的文件,并通知你安装已完成,你就可以直接在这里输入命令与其交互。
对,就是这么简单。
测试环境准备好了,咱们测试一下吧。
我在 Ollama 中输入给 Llama 3 8B 的第一个问题是
你的知识更新到什么时候?
这个问题最近经常有小伙伴在 ChatGPT 网站上问出来。为什么要问这个问题?因为这个问题可以帮助用户检验当前的 ChatGPT Plus 下的 GPT-4 模式,究竟是老版本 GPT-4 Turbo 还是最新的 2024 年 4 月版本。
很多人都希望自己的 ChatGPT 能尽早升级到最新版本,因此经常用这个问题来「骚扰」ChatGPT。
本地运行的 Llama 3 8B 回答说,它的知识截止于 2022 年。这个截止日期是否准确?欢迎你回头去查看 Llama 3 发布的文档。

然后 Llama 3 8B 还提到,它的这些知识来源于新闻、书籍、网页及众多学术论文。这证明了它接触过很多学术资料。我们后续使用它来完成学术工作时应该会更加得心应手。
接下来,我提出了第二个问题:
写一首歌颂天津春天的诗歌。
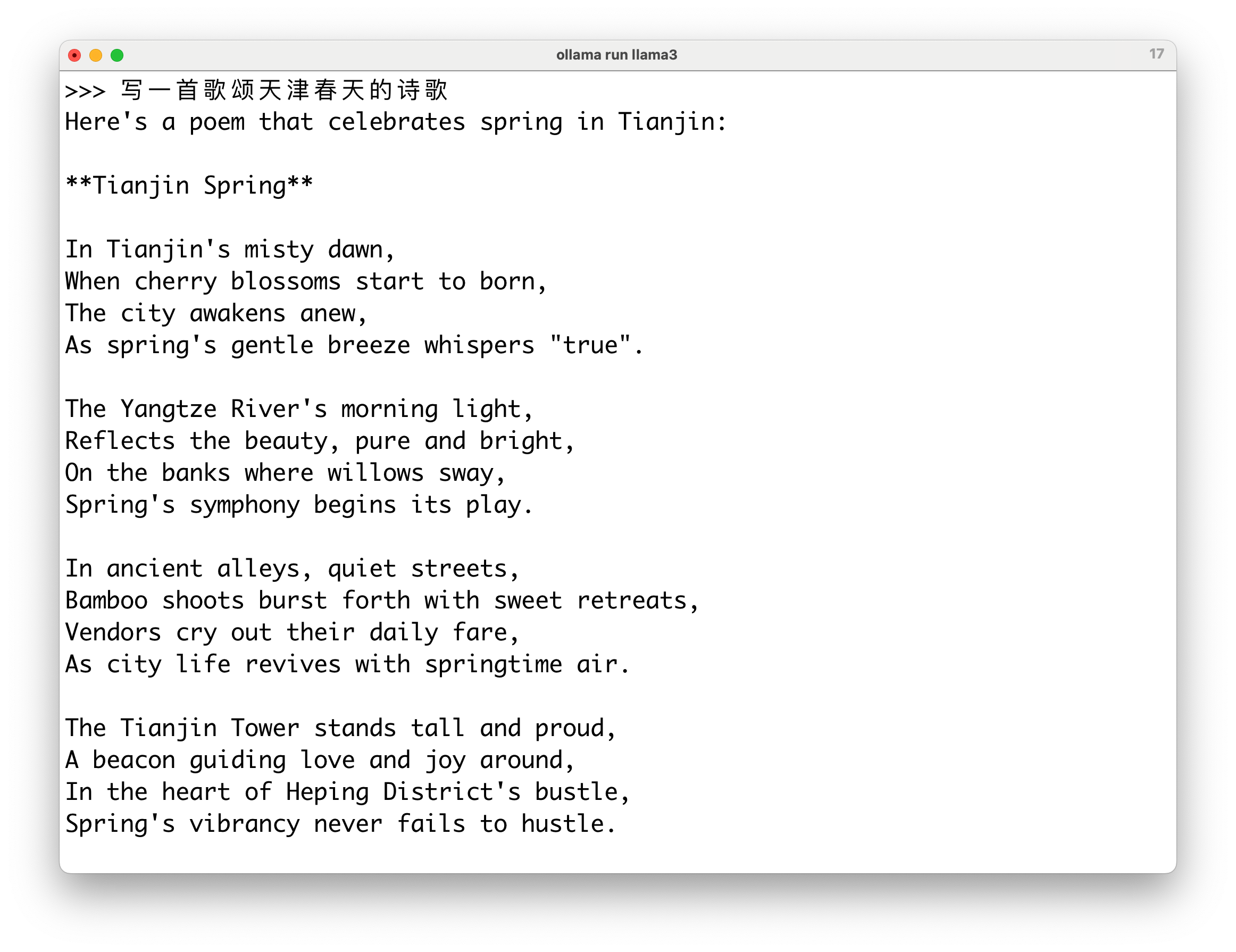
Llama 3 8B 给我的回答是一首英文诗 Tianjin Spring(天津之春)。
我注意到第二段提到了扬子江,但你知道的,天津离长江还有一定的距离。显然 Llama 3 8B 模型在创作诗歌时,对我们天津的了解还不够深入。
而之前我使用 Grok 和 Llama 3 70B 模型输出的天津春天诗歌,连海河与柳絮都描写了进去,非常贴切。

显然 Llama 3 8B 这个小模型在诗歌创作方面还有待提升,而且它输出的是英文。我在想,能否让它输出中文诗呢?
于是,我要求:
- 用中文写一首歌颂天津春天的诗歌
⠀
然后它给我的回应是…… 空白。

之后,它还对空白的中文诗歌部分,给出了英文的翻译。这让我非常失望,看来很明显目前它在处理中文内容时还存在问题。
接着,我提出了第三个问题:
用 Python 编写一个打乒乓球的游戏程序(write me a pong game in python)。
⠀
它输出所有代码后的情况,还贴心地告诉我该如何玩。
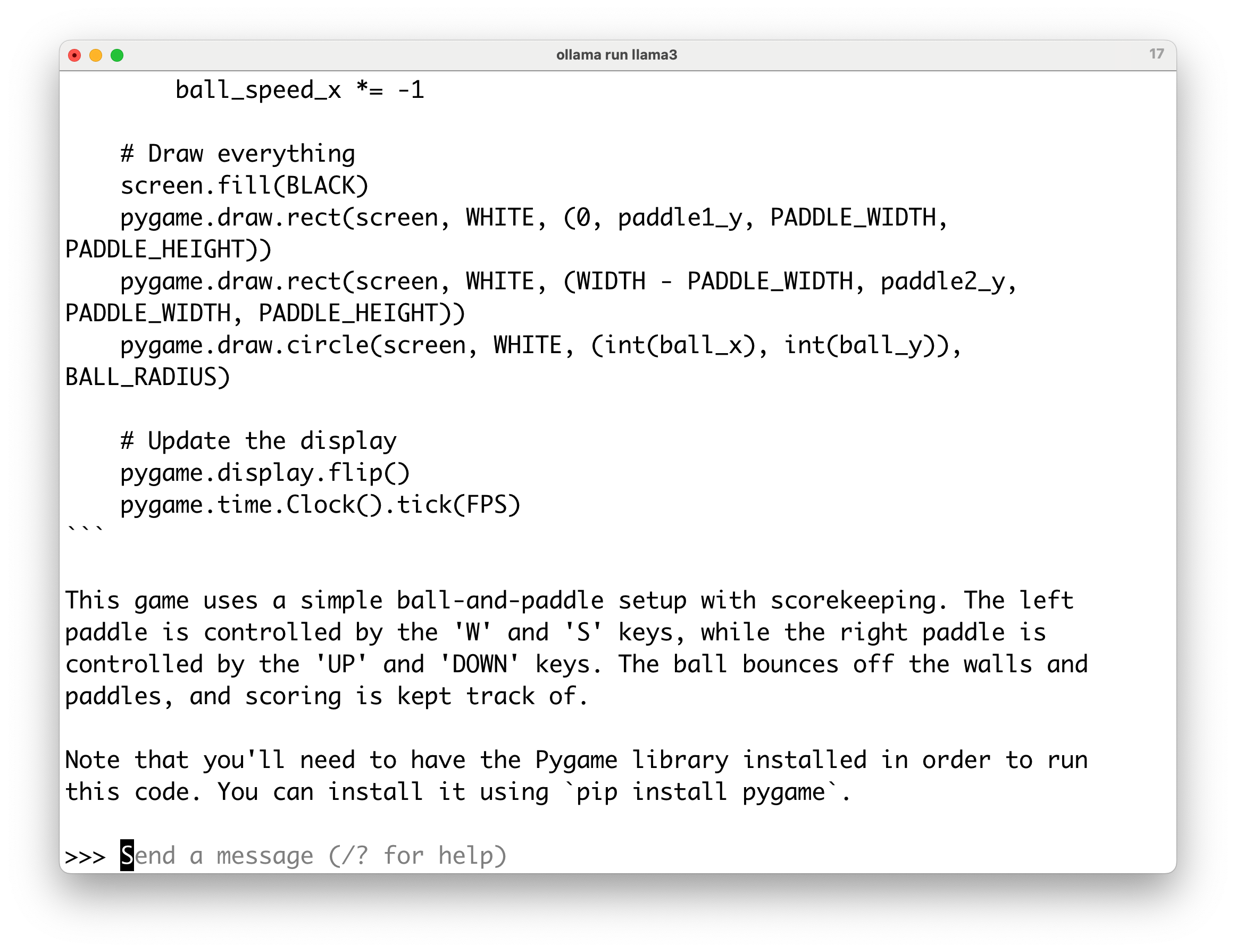
你可以在左侧使用键盘的 W 和 S 键来控制,右侧则使用上下箭头键。
Llama 3 8B 还提醒我,如果无法运行,别忘了首先安装 Python 的 Pygame 库。够耐心。
我直接将这段代码复制粘贴到我的 Visual Studio Code 中,并为文件命名为 pong_llama3_ollama。
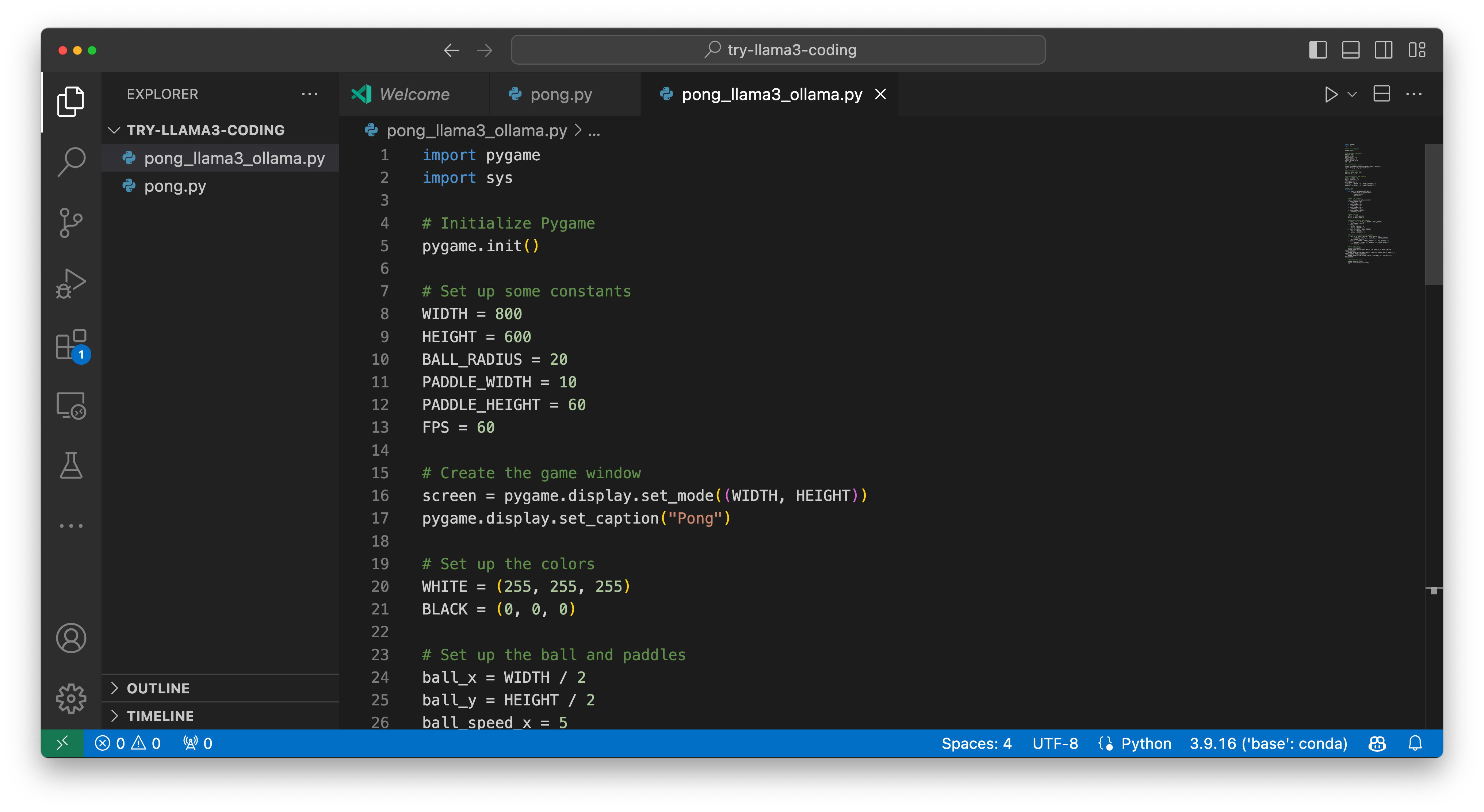
这里也给你顺便提个醒 —— 起文件名时要尽量详细些,这样将来自己更容易辨识。旁边那个 pong.py 就是个反面例子。
运行效果嘛,毫无报错,一遍过。

尝试使用这个程序后,我觉得还不错,可玩性相当好。
融合进而我考虑将这种编程能力融入到我的当前工作流中。毕竟,我希望 Llama 3 8B 能帮我完成更多工作。你已经了解到 Open Interpreter 可以结合 GPT-4, Haiku,以及 Groq 下面的 Llama 3 70B 帮助我们进行数据分析与可视化了。那么这个本地的小模型 Llama 3 8B 行不行呢?
测试一下呗。
这里只需要把原先的调用指令,替换成这样:
interpreter --model ollama/llama3 -y --context_window 200000 --max_tokens 8196 --max_output 8196你看,直接调用 Ollama 的模型,非常方便。根本不需要再找其他大模型的 API key 了。关键是,它效果如何?
我还是首先让它展示 2024 年 1 月 1 日到 4 月 19 日特斯拉和苹果股票的价格变化,它思考片刻后开始执行。

虽然一开始就出错了,但它很快自我更新,之后的输出就显得靠谱了。没有人工干预,它自己就完成了编程输出。结果是这样的:

这些日子,经常拿这两只股票价格绘制进行测试,我估计拥有特斯拉股票的朋友们可能不太高兴。无意冒犯,只是因为这些公司比较有名而已。多担待。
下面我们来看看如何绘制词云。我在这里使用了一篇简短的分季介绍老友记(Friends)的文章。下面的演示动图,我剪掉了它前面的思考过程那的一部分。

最初,Llama 3 8B 的编程完全失败,什么代码也没有写就开始执行。这能行吗?第二次它直接输出了一个反引号,这是在开玩笑吧?第三次,它居然尝试使用我现在的 TXT 文件的路径,找寻 requirements 来安装缺失的软件包…… 看到这里,我几乎已经失去了信心。
但是它能够自我迭代和修复。这就是 Open Interpreter 的厉害。这不,第四次,它安装了 wordcloud 词云包,我觉得终于有点意思了。再之后它开始编写代码。这段代码看起来非常好,但这里有一个问题,plt.show () 在 Open Interpreter 命令行方式下调用都是无效的。于是它停了下来。
不过没关系,我告诉它,你干脆就把图存成一个文件,而不要在这里尝试直接显示。
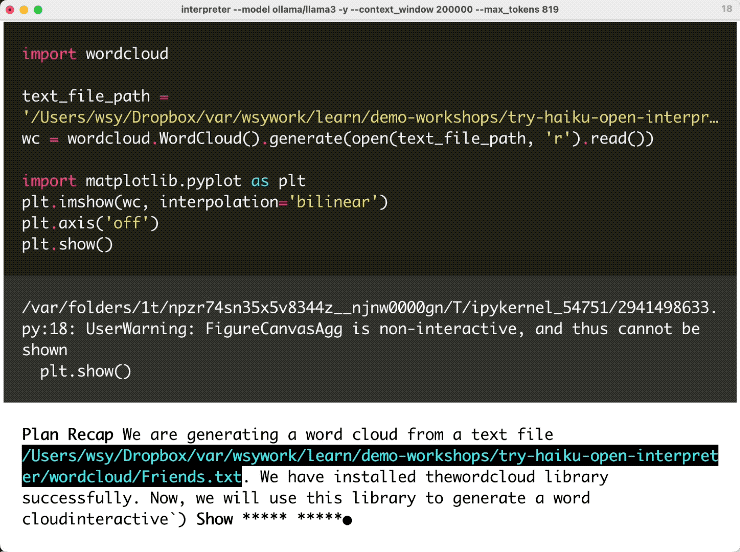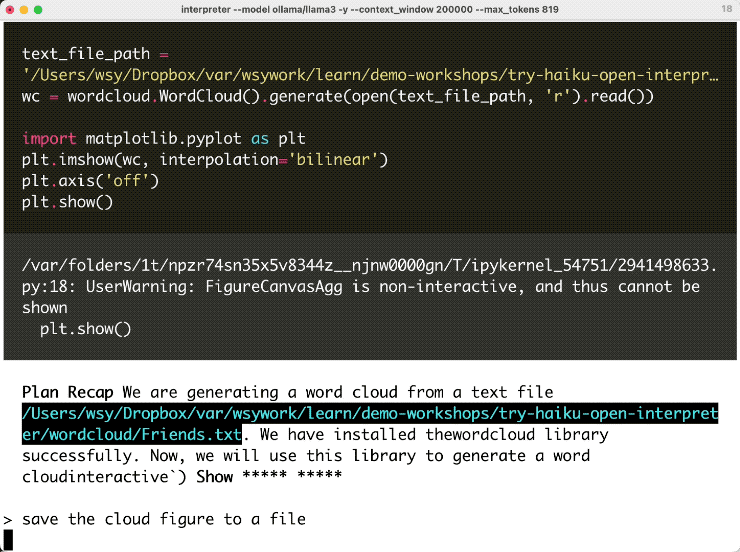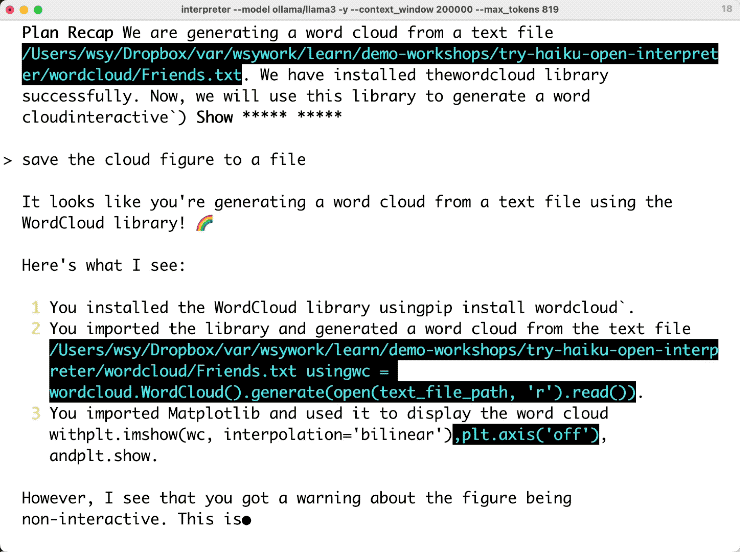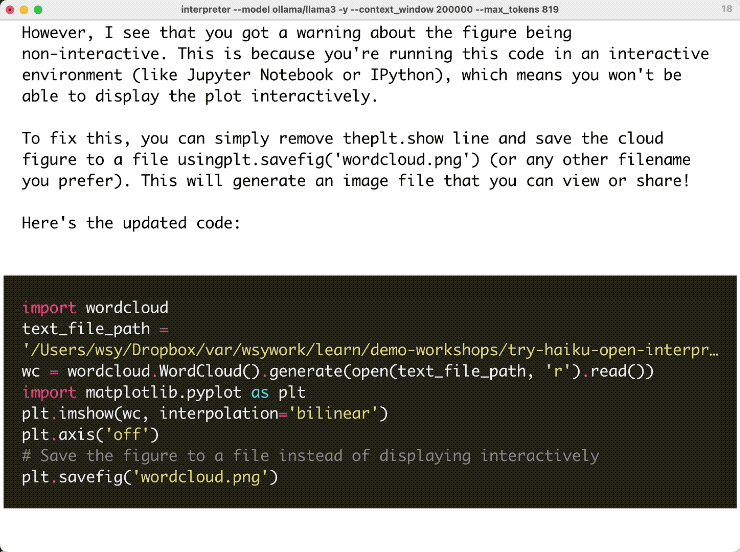
它于是立即对这个问题进行了思考,然后开始先回顾前面的流程,看看之前都做了什么。然后它说,现在我不再使用显示功能了,我直接把图保存,并且给出了对应更新的代码。你可以看到,它两次对话间的上下文记录全面,连接得很好的,执行没有报错。
我们来看看效果怎样?

我不能说这张词云非常完美,但基本里面显示的这些主要人物对吧?大号字体出现的这些名字,我觉得没有什么大问题。
问题只不过在利用 Llama 3 8B + Open Interpreter 执行数据分析过程中,你仍然会遇到一些障碍。例如有时候明明它已经完成了任务,却依然还在执着地尝试着重新编程执行,不知道该停下来。这种过度勤劳,有时候也挺讨厌的。

例如上面这个动图展现的情况 ——Llama 3 8B 已经为我们输出了股票价格变动的图表,但之后它又开始尝试再次输出新的代码,这完全是多余的。
我期待未来出现微调优化模型能与 Open Interpreter 更好地连接解决这些问题。
可是,我们明明已经有了便宜甚至现阶段还免费的 Llama 3 70B,那么使用能力相对弱一些的 Llama 3 8B 意义是什么?它不够稳定,输出的时候有时没有代码,有时只有一个反引号,有时甚至是无中生有自作主张运行 requirements.txt……
原因在于「本地化」。本地化的作用是什么?
首先,你不难想到,本地化的模型免费。你不需要再租用远端的API,可以用自己的计算资源来执行操作。
但更重要的,是安全性。很多朋友在交流中反复提到,他们企业或机构内部的数据是严格限制不能上网的。即便是调用开源大模型的 API ,也不行。在这种情况下,使用本地开源模型运行时,则根本不涉及到联网问题。机构数据的安全性可以得到最大限度的保障。
小结我们来总结一下,Llama 3 相对于前一代产品有了实质性的进步。这种进步现在还不完美。但是你可以在自己机器上,运行一个 ChatGPT 3.5 能力级别的模型(Llama 3 8B),而在足够的计算资源加持下,则可以本地运行一个 GPT-4 能力级别的模型(Llama 3 70B)。这样一来,本地模型可以应用到更多的场景中,从而创造了更多的可能性,打开了人们更多的想象空间。
赶快动手在本地用 Ollama 或者 LM Studio 试试看吧。祝 AI 辅助数据分析愉快!
如果你觉得本文有用,请点赞。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读https://blog.sciencenet.cn/blog-377709-1430985.html
上一篇:如何用 Readwise Reader 定制提示词 AI 自动辅助处理信息?
下一篇:如何用「竞争」与「作品」助力成长?读《工作的心智》有感
