博文
抽样偏差与算法偏差
|
抽样是调查研究工作中普遍采用的一种经济有效的方法。抽样的目的是以较小的代价分析总体,因此一个基本的要求就是要保证所抽取的样本对于总体而言具有充分的代表性,可以看作是从总体中完全随机抽取得到的。如果样本某些维度的特征和总体存在明显偏差,对总体的分析和估计就不再可信,我们称这种问题为抽样偏差。譬如如果总体样本中男性和女性各占50%左右,但是抽样得到的样本中男性占比高达70%,那么就存在明显的抽样偏差,基于该抽样的分析也是不可信的。又比如想通过分析微博的语言来看整个中国的情绪状况和幸福水平,就可能出现表示偏差,因为微博用户全体或随机抽样会对年轻人“表示过度”而对老年人“表示不足”。
这个问题看起来应该很容易避免,但事实上是统计分析中最为常见也极难避免的一个问题。抽样偏差导致的最严重“调查灾难”来自于1936年《文学文摘》对美国总统大选的民调分析。从1916年到1932年,《文学文摘》毫无疑问是美国大选民调的第一高地——该杂志连续五届准确预测了美国总统大选的结果。1936年富兰克林·迪拉诺·罗斯福与艾尔弗雷德·兰登共同竞选美国总统。《文学文摘》杂志根据大约240万人参加的一次民意测验预测,兰登会以57%对43%的优势获胜。这个抽样的规模非常大,所以尽管在民调之前,绝大多数观察家认为罗斯福将毫不费力的获胜,但基于如此大规模抽样的民调结果依然让选举变得扑朔迷离。然而,实际的竞选结果是罗斯福以62%对38%的一边倒优势赢得了1936年的选举,连任总统——这与《文学文摘》的预测南辕北辙。在如此大的样本规模下给出如此离谱的预测,根源就是抽样偏差。事实上,《文学文摘》杂志邮寄了一千万份问卷,收到了大约240万份回复。《文学文摘》的调查对象很多都是从电话簿、汽车车主的登记资料中选取的,而在经济大萧条时期,电话和汽车并不像现在这样普遍,拥有汽车和住宅电话的人大多都是富人,而富人普遍都支持共和党的候选人兰登。正是因为抽样的偏差,导致了完全错误的预测。
有一些抽样偏差隐藏更深,是藏在某些算法和模型所使用的数据中。例如很长一段时期人脸识别对于白种人和男性的准确性要高于有有色人种和女性,后来才发现这是因为主流的人脸识别算法大多都会用ImageNet数据集里面的图片作为样本,而这个图片中女性和有色人种的样本是不足的——这显然不是ImageNet造成的,而是反映了更深层次的社会问题。特别地,ImageNet来自中国和印度的照片只占1%和2%,这和中印两个超级人口大国的真实人数相比,抽样偏差就比较明显,事实上也带来了对中国和印度图片识别算法准确度的下降[1]。
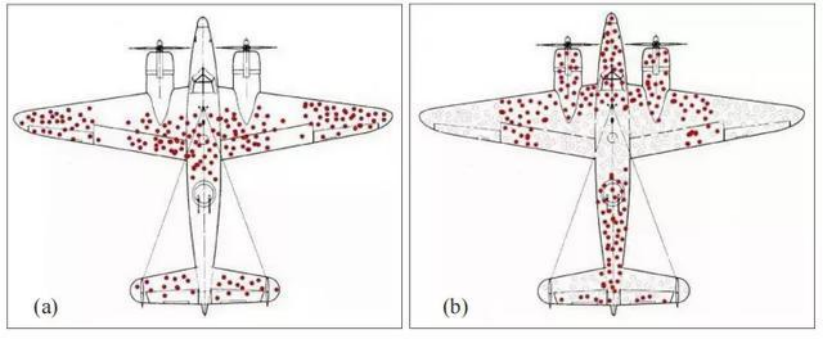
图1:飞机上的弹孔分布。(a) 空战中飞回来的飞机(幸存飞机)的弹孔分布;(b) 逆向推理得到的最可能导致飞机被摧毁的弹孔分布。
除了抽样带来的偏差外,还可能因为使用的模型、计算方法或统计分析方法(为了方便,后统称为算法)存在偏差,而导致错误的结论。在第二次世界大战期间,英国和德国在空战中都损失了不少重型轰炸机。当时英国国防部一个棘手的难题就是在轰炸机哪些部位装上更厚的装甲,从而提升本方飞机的防御能力。由于装甲很厚,会大幅度增加飞机重量,因此不可能将飞机包裹在装甲中。研究人员必须做出选择,在飞机最危险的地方加上装甲。
军方希望通过统计方法找出为轰炸机加装装甲的有效方法。军方组织了大量人力调查那些执行完轰炸任务返航的轰炸机,对其中弹部位及中弹数量做详细记录。如图1(a)所示,研究人员注意到,许多重型轰炸机踉踉跄跄返回基地时,机身上千疮百孔简直像瑞士奶酪,机身部位中弹几乎是发动机部位的两倍,飞机机翼的中弹数量甚至比机身更多。于是,研究人员提议,在弹孔最密集的地方加上装甲,以提高轰炸机的生存能力。
有意思的是,当时英国盟军美国军方的一位统计学家,哥伦比亚大学教授亚伯拉罕·瓦尔德,认为这是大错特错的决定。他向高层军官解释说,正确的做法恰恰相反,应该是为那些没有弹孔或弹孔不多的部位增设装甲。初听起来费解,但却充满了数学家的智慧。因为这些采样数据,均包含了那些中弹后又返航却幸存下来的飞机中弹的特征。统计中发动机中弹的弹孔少,并不是因为发动机被命中的机会少,而是因为这种情况下,飞机基本不可能返航。实际上,高炮向那一片天空喷射炮弹时,从概率学考虑,轰炸机各部位受损是均衡分布的,而被击落的飞机残骸并没有被统计在内。按照瓦尔德的分析,已经坠毁的飞机弹孔分布应该更接近图1(b),而非图1(a)。
从这个著名的“幸存者偏差”的例子可以看出,即便得到有价值的数据,如果采用的算法(方法)不正确,也会得到完全错误的结果。
算法偏差还可能来源于设计算法的时候对于可能影响结果的各种因素考虑不足。2001年起,英国开始开展全国范围内刺猬数量的调查。由于在野外直接统计刺猬数量非常困难,从2002年起,调查人员想到了一个聪明的办法,就是在此为迁移的季节,也就是6月到8月开展调查,而调查的方法就是观察在柏油路上有多少被车辆压死的刺猬尸体。这背后的逻辑非常显然,如果刺猬种群数量足够大,那么不幸被压死的刺猬也应该多,反之亦然。所以只需要观察被车辆压死的刺猬数目的变化,就可以估计野生刺猬种群的大小变化。遗憾的是,这个调查结果展示的变化趋势和野生动物学家在栖息地考察得到的结果很不一致。实际上,这个聪明的办法漏洞百出,因为刺猬完全有可能在多次迁徙中学会如何躲避车辆,从而导致被压死的刺猬占比逐年减低;也有可能车辆越来越多,从而导致被压死的刺猬占比逐年升高。这种忽略了很多对结果有影响的因素变化后想当然的理想化计算方法,往往都会导致荒谬的结果。又比如联合国艾滋病规划署(UNAIDS)曾用艾滋病患病人数来评估艾滋病肆虐的程度,却忘了艾滋病医疗水平的快速提升让患者能够存活更长时间,所以患病人数的增长很快,因此这个增加的患病人数不一定是坏事。后来,UNAIDS发现了这个问题,改为用每年新增患病人数来评价艾滋病传播的厉害程度。
我们在开展调查研究并应用统计分析的方法和工具的时候,一定要反复检查是否存在样本偏差和算法偏差。
参考文献:
[1] S. Shankar, Y. Halpern, E. Breck, J. Atwood, J. Wilson, D. Sculley, No classification without representation: Assessing geodiversity issues in open data sets for the developing world, arXiv: 1711.08536.
https://blog.sciencenet.cn/blog-3075-1409357.html
上一篇:大数据医疗应用综述[Appl. Sci.专栏第二十一篇发表论文]
下一篇:高校社会评价受所在城市社会经济因素影响很大