博文
猫咪怎样启发了人工神经网络的诞生?  精选
精选
||
2012年是神经网络翻身的一年。一个具有划时代意义的模型AlexNet横空出世,在一个叫做ImageNet的图像识别竞赛中,以识别率远超第二名10.9个百分点的绝对优势,一举夺冠,引起了人工智能领域极大的轰动。辛顿三人的AlexNet成功的秘诀,是使用了“多层卷积人工神经网络”,这个短语中涉及的词汇,都可以靠“顾名思义”就大概明白了,唯有其中的“卷积”一词,说的是什么意思呢?今天我们就聊聊这个话题。
喵咪视觉的启发
故事得回到20世纪60年代初,哈佛大学两位神经生物学家休伯尔David Hubel和威泽尔Torsten Wiesel,作了一个有趣的猫咪实验,见图1。他们使用幻灯机向猫展示特定的模式,然后记录猫脑中各个神经元的电活动[1]。他们发现特定的模式刺激了猫咪大脑特定部位的活动。正因为他们在视觉信息处理方面的杰出贡献,荣获了1981年诺贝尔生理学或医学奖。
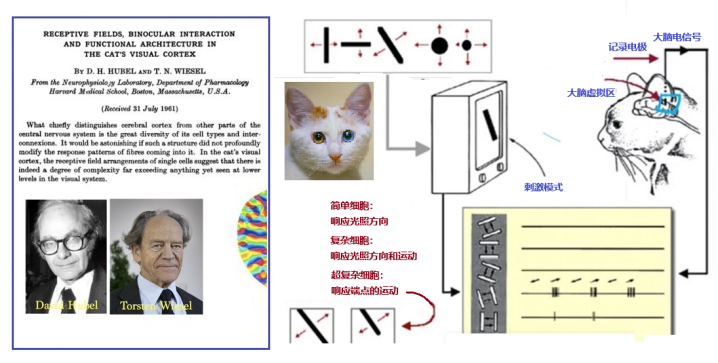
图1:1962年哈佛大学研究者对猫咪的神经生物实验
哈佛学者的实验证明,视觉特征在大脑皮层的反应是通过不同的细胞达成的。其中,简单细胞(Simple Cell)感知光照信息,复杂细胞(Complex Cell)感知运动信息。到了1980年前后,日本科学家福岛邦彦受猫咪生物实验的启发,模拟生物视觉系统并提出了一种层级化的多层人工神经网络,即“神经认知”系统,这是现今卷积神经网络的前身。在论文中,福岛邦彦提出了一个包含卷积层、池化层的神经网络结构。
福岛小时候家境贫寒,但好奇心让他对电子技术充满激情,后来他获得了京都大学的电气工程博士学位,1965年他加入了一个视觉和听觉信息处理研究小组,研究生物大脑。之后,福岛与神经生理学家和心理学家通力合作,组装人工神经网络。
1979年,「Neocognitron」神经认知系统问世了,灵感便来自于两种已知存在于生物初级视觉皮层的神经细胞:简单的「S」细胞,以及复杂的「C」细胞,它们后来分别演化成了现在神经网络中的卷积层和池化层,见图2[2]。
福岛老爷子今年已经88岁了,5年前他还发表了神经网络方面的研究论文。
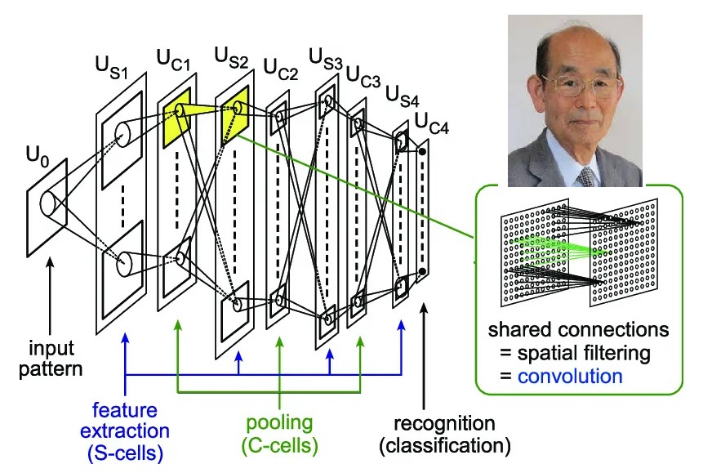
图2:福岛邦彦1980年的“神经认知”系统
其实福岛邦彦40年前的认知系统已经具有了卷积神经网络的基本构型,但当时这个网络的神经元都是由人工设计而成,不会根据结果进行自动调整,学习能力不强等等。因此只能限制在识别少量简单数字的初级阶段。
来得早不如来得巧,卷积方法得以实用化是在1998年,法国计算机科学家杨立昆(Yann LeCun,1960-)将反向传播应用到卷积神经网络的训练之后。
杨立昆于生于法国巴黎附近,1983年在巴黎电子工程师高等学校获得了工程师学位,1987年在巴黎第六大学获得计算机科学博士学位,随后到多伦多大学在杰弗里·辛顿的指导下完成了博士后工作,与辛顿同为2018年图灵奖得主。

图3:杨立昆
1986年,正在攻读博士学位的杨立昆放下了另一个研究工作,开始专注研究反向传播。出于从休伯尔、威泽尔和福岛邦彦工作中获得的灵感,以及对哺乳动物视觉皮层研究的迷恋,他设想了一个多层网络架构,能够将简单细胞和复杂细胞的交替以及反向传播训练结合在一起。他认为这种类型的网络非常适合用于图像识别[3]。
1988年,杨立昆加入新泽西州的贝尔实验室。在此,他开发了包括卷积神经网络在内的多个机器学习方法[4]。并且真正实现了卷积神经网络,贝尔实验室将其命名为LeNet,就如他的姓LeCun一样,这是卷积网络的第一个名字。
人眼如何识别物体?
图像识别一直是人工智能研究中的热点,这是有原因的。本来人类的知识就来自于对世界的观察,从人眼开始,延伸到望远镜显微镜等等各种观测工具。我们伟大的科学,就是建立在许多许多观测资料的基础之上。
计算机要模仿人的功能和思想,也包括了人眼识别的过程,而眼睛是非常复杂精致的器官,加上与大脑神经的联系及反馈,形成的生物视觉机制,是数百万年间持续进化的高级产物,人类尚未完全弄明白,当然也不是那么容易仿效的。
人眼到底是如何工作的?你可能认为这很简单,人眼是一个光学系统,物体的反射光通过晶状体折射成像于视网膜上。再由视觉神经感知传给大脑。这样人就看到了物体。人工智能开始时就是企图如此来模拟视觉:接受器件将整个图像通过扫描成为像素,送到神经网络进行识别,如图4a。
然而,人眼识别似乎不是那么简单,那么,人眼是如何识别各种模式的?说得更具体一点,人眼如何识别一个手写的字母x?
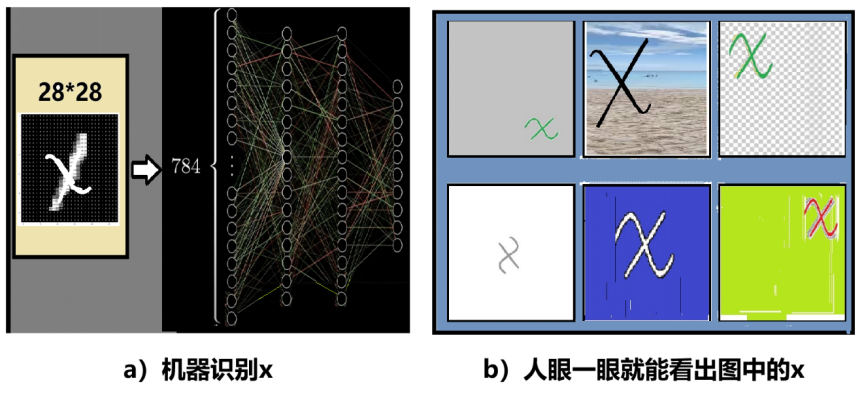
图4:机器识别和人眼识别
从我们的经验知道,人眼“一眼就能”看出图1b中的每个小图中都有个x,无论这个x放在哪个位置?是大还是小?是红还是蓝?有没有背景图?
科学家们希望机器也能尽量做到这点,于是有人便搬出了“卷积”这个法宝。
卷积是个啥?
实际上,卷积概念的出现大大早于神经网络,如图4上方的数学表达式所示:它是一种从两个函数f(r’)和h(r-r’)相乘再对r’积分得到另一个函数g(r)的运算。
尽管名字不同,但与卷积类似的运算最早是于1754年出现在达朗贝尔的数学推导中,继而又被其他数学家使用过。不过,这个术语的正式登场是在1902年。
之后,在通信工程中,卷积用以描述信号和系统的关系。对于任意的输入f(t),线性系统的输出g(t)表示为脉冲响应函数h(t)与输入的卷积。例如,歌手使用麦克风演出时,通过麦克风听到的歌声,与麦克风之前的声波是有所不同的,因为麦克风对输入信号有延迟和衰减的作用。如果将麦克风近似为一个线性系统,用函数h(t)来表示它对信号的作用,那么,麦克风的输出g(t)就是输入的f(t)与h(t)的卷积。另一个有趣的事实是,如果送进麦克风的输入是狄拉克d-函数的话,麦克风的输出便正好是它的脉冲响应函数h(t)。
仔细观测卷积的积分表达式,会发现积分号中h函数积分变量r’的符号为负。如果r是时间t的话,那就是说,h函数被“卷”(对时间翻转)到过去的数值,再与当前的f值相乘,最后再将这些乘积值叠加(积分)起来,便得到了卷积。这点在麦克风的例子中很容易理解,因为麦克风每个时刻的输出,不仅与当前的输入有关,还与过去的输入有关。

图5:卷积
总结上面一段话,可以更简要地理解卷积:卷积是函数f对权重函数h的权重叠加。
数学的美妙之处在于抽象,抽象后的概念可以应用于其它不同的场合。比如卷积,可以被用于连续函数(如信号和系统),也可以被用于离散的情况(如概率和统计);卷积的积分变量可以是时间,也可以是空间,还可以是多维空间,例如将它用于AI的图像识别中,便是卷积在离散的多维空间中的应用。
卷积层和卷积计算
现在让我们想想,当给计算机一个包括"X"的图案,它怎么才能找到这个“X”呢?一个可能的办法就是:让计算机存储一张标准的“X”图案,然后将这个标准图放到输入图的各个部分去比对,如果某部分与标准图一致,则判定找到了一个"X"图案。更进一步,这个标准图最好还有缩小放大转动等功能。
以上提到过,人眼“一眼就能”看出图中某个模式。其实这个“一眼就能”有个数学模型,就是d-函数。如果将d-函数用于卷积中,因为它只在某一个孤立点有值,所以它能够将f函数该点的值“抽取”出来。
如图6所示,标准图(图中的卷积核)就像一双眼睛,它的3x3窗口在7x7的输入数据上滑动,就像眼睛在图上望来望去,将符合标准的部分抽取出来。这个比对抽取的过程,就由卷积操作来完成。具体计算过程:卷积是将窗口扫描到的3x3矩阵元数值,与卷积核的3x3矩阵元数值逐一相乘再全部加起来,将得到的结果写到与窗口中心对应的1x1位置中。最后得到的(更大的,图中是7x7的)输出矩阵,就是卷积的结果。
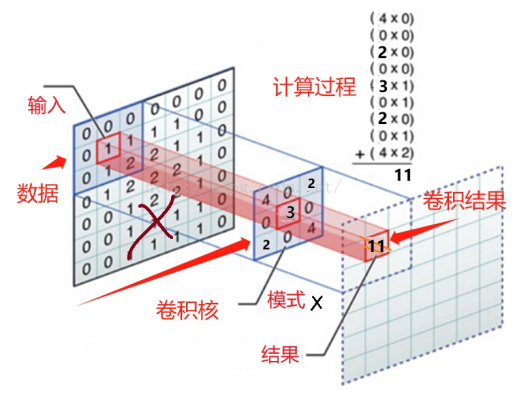
图6:神经网络识别x时的卷积计算
也可以说,卷积核的作用,类似于代表某个模式的d-函数,它能把这个模式从原图中“抽样提取”出来。用前面描述卷积数学公式的语言来说,图6左边的输入矩阵,是f函数;卷积核是h函数;最右边的输出,是卷积计算的结果g函数。卷积核(图中的3x3矩阵)的矩阵元,是权重系数。卷积核的权重系数,与连接层与层之间的权重系数一样,也可以通过学习和训练过程进行优化。此外,还要用适当的激活函数达到非线性化的目的。
卷积的作用是“抽取”,抽取什么呢?在图像识别中,通俗地说就是抽取事物的轮廓。
池化层及卷积神经网络
让我们回头再想想人眼识物的更多特点。当我们从轮廓知道了那是一只猫之后,我们发现一个有趣又有用的事实:即使将图像缩小很多,我们仍然能够判定“那是一只猫”。这说明储存的轮廓图像有许多冗余的信息。
我们不需要太多冗余信息,因为它们浪费了计算机的储存空间。并且,有时信息多了是画蛇添足,反而增加判断的错误率。所以,我们将图6所示的卷积层的计算结果,送入一个叫“池化”的网络层。池化的作用便是对特征图进行降采样,降低信息的冗余,从而减小网络的模型参数量和计算成本,减少过拟合的风险,也对输入图像中的特征位置变化,诸如变形、扭曲、平移等等视觉模式漂移,更不敏感。
以上解释是针对一个卷积层加一个池化层识别一个简单模式而言。实际上,对输入的大量彩色复杂图片,需要识别的模式非常多,因此必须考虑许多复杂的因素,上面描述的特征提取器不是“手动”设计的,而是通过学习自动生成的。做到自动化,是使用反向传播训练的多层网络的魅力所在。不过,基本思想与上面所说是一致的:多个卷积层加非线性再加上池化层,足以识别出从简单模式(拐角、边缘等)到复杂对象(人脸、椅子、汽车等)的各类图像内容,见图7。
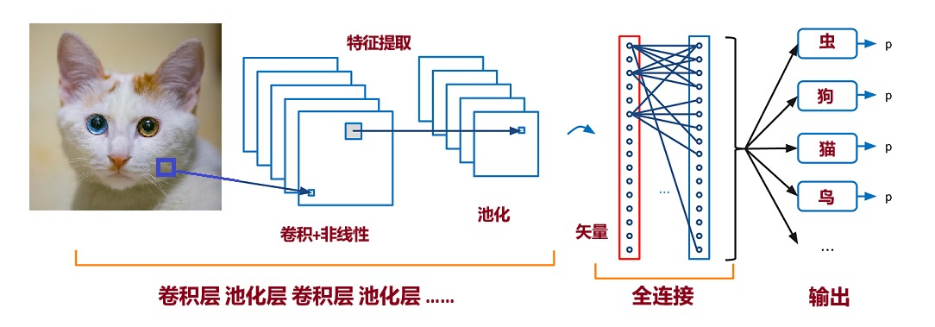
图7:卷积神经网络整体示意图
卷积加池化中的计算,看起来是乘法叠加,它们的总作用是提取重要信息并降维。为了更好地理解这两层神经网络的作用,我们也可以与声音信号的傅立叶分析相比较。一般的声音信号(如一段音乐)在时间域中是颇为复杂的曲线,需要每个时刻的大量数据来表示。如果经过傅立叶变换到频率域后,便只要少量的几个频谱,基频和几个泛音的数据就可以表示了。例如最简单的,某个单一频率的声波,在时间域是一连串的强度随时间变换的正弦函数值,而在傅立叶变换后的频率域,只是一个d-函数。也就是说,傅立叶变换能够有效地提取和存储声音信号中的主要成分,并且降低描述数据的维数。卷积运算在神经网络中也有类似的作用:一是抽象重要成分,抛弃冗余的信息,二是降低数据矩阵的维数,以节约计算时间和存储空间。不过当卷积神经网络应用于图像识别时,提取的是图像的空间变化信息,不是时间频谱。
卷积神经网络为大众熟知的最广泛应用是人脸识别技术,我们在手机照片中经常看到。比如,如图8所示,一张“人脸” 可以看做简单模式的层级叠加,第一个隐藏层学习到的是人脸上的轮廓纹理(边缘特征),第二个隐藏层学习到的是由边缘构成的眼睛鼻子之类的“形状”,第三个隐藏层学习到的是由“形状”组成的人脸“图案”,每一层抽取的目标越来越抽象,在最后的输出中通过特征来对事物进行识别(是或不是)。
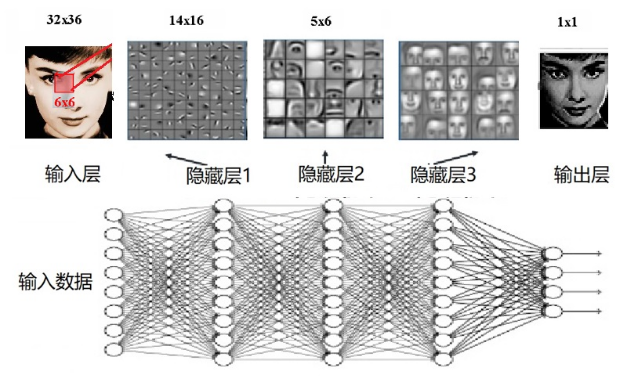
图8:每一层的分类能力越来越“抽象”
神经网络虽然源于对大脑的模拟,但后来的发展则更大程度上被数学理论及统计方法所指导,正如飞机这一交通工具的发展过程,源于对鸟儿飞翔的模仿,但现代飞机的结构却与鸟类身体构造风马牛不相及。
参考文献:
[1]Receptive fields, binocular interaction and functional architecture in the cat's visual cortex., D. H. Hubel and T. N. Wiesel, The Journal of Physiology(1962)
https://www.aminer.cn/archive/receptive-fields-binocular-interaction-and-functional-architecture-in-the-cat-s-visual-cortex/55a5761e612c6b12ab1cc946
[2]Fukushima, K. (1980) Neocognitron: A Self-Organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position. Biological Cybernetics, 36, 193-202.
https://doi.org/10.1007/BF00344251
[3]科学之路: 人、机器与未来 当机器思考时,人类会怎样?,作者: [法] 杨立昆,出版社: 中信出版集团,2021-8-1。
[4]Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard and L. D. Jackel: Backpropagation Applied to Handwritten Zip Code Recognition, Neural Computation, 1(4):541–551, Winter 1989.
(本文首发于微信公众号“知识分子”)
https://blog.sciencenet.cn/blog-677221-1439883.html
上一篇:量子纠缠:“鬼魅般的超距作用”|量子计算群英会(七)
下一篇:“费马数”-猜想

全部作者的精选博文
- • 都江堰科普
- • 费马大定理-最后一步
- • 费马大定理-铺平道路
- • 费马大定理-模性定理
- • 费马大定理-椭圆函数
- • 费马大定理-椭圆曲线和“群”
全部作者的其他最新博文
- • 都江堰科普
- • 费马大定理-最后一步
- • 费马大定理-铺平道路
- • 费马大定理-模性定理
- • 费马大定理-椭圆函数
- • 费马大定理-椭圆曲线和“群”