博文
大模型时代的软件工程:现状和展望
||


研究团队
张犬俊,房春荣,谢杨,张雅欣,虞圣呈,陈振宇:南京大学
孙伟松:南洋理工大学
杨耘:斯威本科技大学
研究意义
近年来,大语言模型(Large Language Models, LLMs)的迅猛发展极大推动了人工智能技术的演进,并在自然语言处理、计算机视觉和多模态理解等领域取得了显著成果。研究者逐步将 LLM 应用于软件工程(Software Engineering, SE)的各个阶段,包括代码生成、缺陷修复、测试生成与程序理解等,展现出显著的自动化与智能化潜力。尽管已有综述对深度学习和机器学习技术在软件工程中的应用进行了回顾,但多数聚焦于传统的 DL4SE 或 ML4SE 路线,内容往往局限于软工领域的特定子领域,难以全面反映当前LLM4SE的最新格局。目前,软工领域仍缺乏一项覆盖范围广、任务粒度细、数据规模大且系统性的研究,用以梳理 LLMs 的技术演进、模型架构、预训练目标与下游任务之间的映射关系,并深入识别其在软件工程全生命周期(需求、开发、测试、维护与管理)中的关键挑战与未来机遇。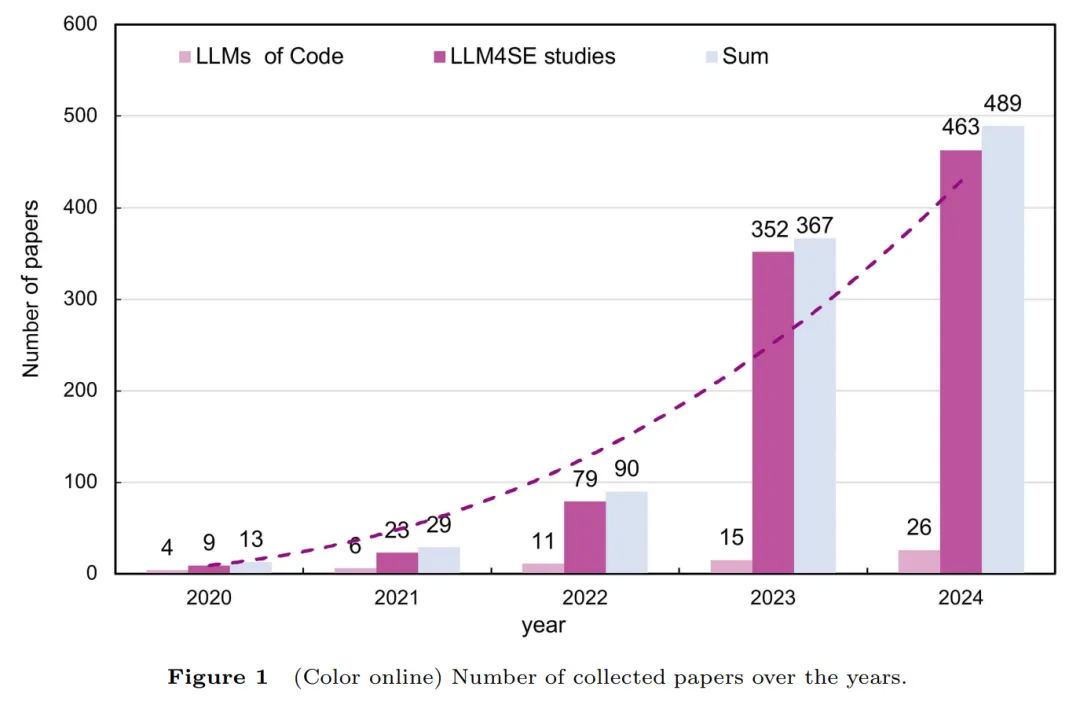
本文工作
为解决上述问题,本文系统调研了 2017–2024 年间软件工程与大模型交叉领域的 988 篇研究文献,其中包含 62 篇代码大模型论文与 926 篇LLM4SE 应用论文,全面刻画 LLM 在软件工程中的发展现状、方法谱系与前沿趋势。本文首次从“大模型—软工—融合”三重视角构建 LLM4SE 的系统综述框架,并据此开展分层分析与对比。
大模型视角。归纳总结了 62 个具有代表性的代码大模型,涵盖三大主流架构(Encoder-only、Decoder-only、Encoder-Decoder)、15 种预训练目标以及 16 类典型下游任务,并分析其开源可用性代码任务支持能力。
软工任务视角。围绕软件工程五大阶段(需求、开发、测试、维护、管理),系统梳理 926 篇研究中涉及的 112 种具体任务类型,涵盖需求建模、代码生成、缺陷检测、测试生成、程序修复、项目管理等,构建出 LLM 驱动的软件工程任务图谱。
二者融合视角。探讨大模型与软件工程融合的关键挑战与实践路径,包括评测基准构建、模型可靠性与安全性、领域微调策略、压缩与蒸馏等,总结典型技术路线、共性难点与可复用经验。
此外,本文建立并持续维护开放知识库AwesomeLLM4SE(https://github.com/iSEngLab/AwesomeLLM4SE),用于追踪最新研究进展并支持开源社区协作,推动 LLM4SE 研究的系统化与可持续发展。
实验结果
通过对近千篇研究工作的三维视角分析,本文系统揭示了大模型在软件工程领域的总体格局与未来趋势。总体来看,LLM 正推动软件工程从“自动化”迈向“智能化”,实现从“以语言驱动代码”到“以代码塑造模型”的跃迁。一方面,模型体系与任务生态不断完善;另一方面,可信性与工程化仍是下一阶段的核心突破口。其主要发现如下:
模型体系日趋完善,代码语料融入训练。
大模型已从早期的 Encoder-only、Encoder-decoder架构演进至以 Decoder-only 模型为主的多样化体系,显著增强了代码生成与理解能力。与此同时,使模型从“能理解代码”迈向“能学习编程、能进行代码推理”。随着预训练数据中代码比例的显著提升,模型的知识边界从自然语言扩展至程序语言空间,形成了自然语言与源代码双模态共训的体系结构,为软件工程任务奠定了新的语义基础。此外,超过 80% 的模型实现或权重已公开,极大促进了社区协作与开放科学的持续发展。
应用生态全面渗透,任务分布仍显失衡。
大模型正广泛融入软件工程全生命周期的五大阶段,形成覆盖百余种任务的全景式智能任务图谱。其中,开发与测试阶段最为活跃,占研究总量的 70% 以上,重点集中于代码生成、自动补全、测试生成与缺陷修复等主流任务;而需求建模、设计分析与项目管理等环节的研究仍相对薄弱,亟需在语义建模、需求理解与智能协作方面持续突破。这一趋势表明,LLM 正逐步从“辅助开发工具”向“智能协作主体”演进,但其应用深度在不同任务间仍存在明显不均衡,未来具有广阔的探索空间。
融合发展迅速推进,可信可控仍是瓶颈。
尽管大模型已在多个任务中展现卓越的代码生成与理解能力,但在真实工程场景中仍面临性能稳定性、幻觉输出、安全漏洞及评测体系缺失等挑战。当前研究正从性能优化转向可信性、安全性与工程化融合方向,重点探索统一评测基准、领域微调策略、知识蒸馏与模型压缩等技术路径,并尝试引入检索增强、人机协作和多智能体框架,提升模型的可解释性与可约束性。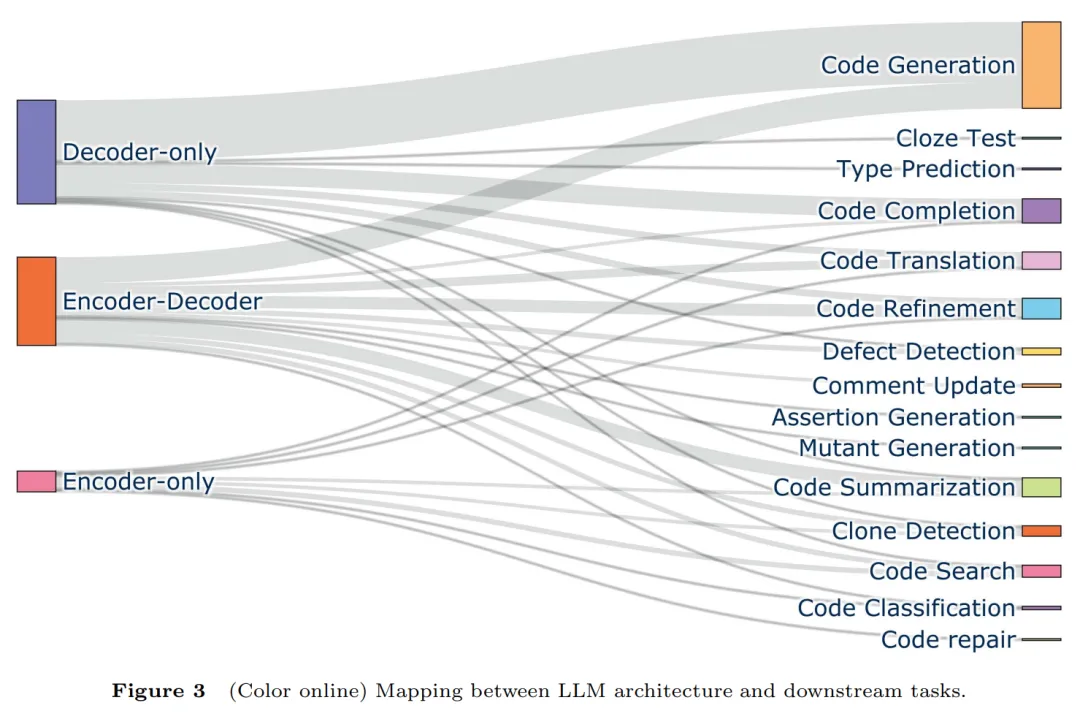
未来研究
高效可部署的大模型优化。当前大模型参数规模不断扩大,性能虽提升显著,但训练与推理成本高昂,限制了其在资源受限环境中的应用。未来应聚焦于模型剪枝、量化与知识蒸馏等技术,以在保持性能的同时降低计算与存储开销,并探索分布式推理与轻量化部署方案。
面向任务的领域专用模型构建。现有LLMs多为通用模型,缺乏对软件工程领域特性的适配。应引入领域专家知识、任务特定数据与混合预训练目标,构建针对特定任务(的高效领域模型,提高模型在特定场景下的精准性与可靠性。
构建高质量与可复现的评测基准。评测数据的噪声与泄漏问题依然存在,缺乏统一、客观且能真实反映软件工程任务复杂度的评测集。未来应注重构建开放、可扩展的基准体系,促进模型性能的公平比较与可复现研究。
加强模型安全与鲁棒性研究。大模型在软件生成中易受对抗攻击或后门攻击,可能生成存在安全漏洞的代码。未来研究需探索攻击检测、输出约束与防御机制,确保模型在实际工程环境中的安全性与稳定性。
支撑开源社区智能生态演化。开源社区不仅为大模型提供了海量、高质量的训练数据和真实应用场景,也因大模型的引入而迎来开发范式的深刻变革。未来研究可进一步探索 大模型与开源生态的深度融合,从任务分配、PR审查,到代码评审与 Issue 管理,推动人机协作模式的高效耦合与持续优化。构建人—机—物共演化的智能开源生态,推动软件工程迈向开放、自治与持续创新的新范式。
相关阅读
SCIS专题 | 工业智能系统及软件专刊(第二十七届中国科协年会学术论文)
先进计算与新兴软件专题 | 面向海量数据的高效流水化检索增强生成系统

https://blog.sciencenet.cn/blog-528739-1530682.html
上一篇:植被绿化下的功能退化:中国保护区的“量质失衡”折射全球保护成效困境
下一篇:封面映新知,四月精彩尽在此间
