博文
【论文推荐】基于双经验回放池TD3算法的PID参数优化
||
编辑荐语
本期将给大家分享“基于双经验回放池TD3算法的PID参数优化(PID parameter optimization based on TD3 algorithm of double replay buffer)”. 如您对本期相关内容有好的理解与建议, 欢迎评论区留言.
本文针对工业中广泛应用的PID控制器参数整定依赖人工经验、传统优化方法需精确模型且易发散的瓶颈问题, 创新性地提出了一种基于双经验回放池TD3(DRB-TD3)的深度强化学习参数自整定框架. 该方法将PID参数优化问题建模为序列决策过程, 通过智能体与环境的交互试错, 实现了不依赖被控对象精确模型的数据驱动式优化. 针对经典TD3算法在训练前期探索效率低、Critic网络更新不稳定易导致控制曲线发散的问题, 本文设计了双经验回放池机制, 依据时序差分误差(TD-error)动态划分并采样样本, 优先利用对网络更新贡献更大的样本, 显著提升了训练初期收敛速度与稳定性, 有效避免了控制过程发散. 在二阶系统与一阶时滞系统上的仿真对比表明, 所提方法整定出的PID参数在控制性能上优于粒子群优化(PSO)算法, 为PID控制器的高效、稳定、自动化整定提供了具有强实用性的强化学习新途径.
论文介绍
基于双经验回放池TD3算法的PID参数优化
PID parameter optimization based on TD3 algorithm of double replay buffer
钟皓俊, 王振雷†
机构: 华东理工大学 能源化工过程智能制造教育部重点实验室
引用: 钟皓俊, 王振雷. 基于双经验回放池TD3算法的PID参数优化. 控制理论与应用, 2026, 43(1): 139 – 148
DOI: 10.7641/CTA.2024.30730
全文链接:
http://jcta.alljournals.ac.cn/cta_cn/ch/reader/view_abstract.aspx?file_no=CCTA230730&flag=1
摘要
PID控制器在工业控制领域应用广泛, 其参数的选择过度依赖于人工经验, 效率低且过程繁琐. 近年来, 深度强化学习因其具有对复杂环境自学习的能力, 在很多领域取得了成功应用. 本文提出一种基于双经验回放池双延迟深度确定性策略梯度(TD3)算法的PID参数优化方法, 利用深度强化学习的方法, 自主优化PID控制器的参数. 在整个优化过程中, 将控制问题视为序列决策过程, 通过设计智能体的状态、动作空间以及网络结构, 将PID参数的优化过程转化为强化学习策略网络权重的更新过程. 同时, 针对TD3算法训练前期探索效率低的问题, 在TD3算法的基础上, 增加双经验回放池机制, 提升了算法训练前期的效率. 最后, 在二阶系统和一阶加纯时滞系统上进行仿真验证, 并与基于粒子群优化(PSO)算法优化PID参数的方法进行对比, 实验结果表明, 所提算法优化得到的PID参数在控制器上体现的控制性能要优于PSO算法.
引言
在工业控制中, PID控制器一直是应用最广、也是最为成熟的控制器[1]. 尽管在控制领域, 各类新式的控制器层出不穷, 但PID控制器仍然凭借其稳定性好、结构简单等优点[2], 占据着工业控制器的主导地位. PID控制系统的控制性能直接取决于比例系数(KP)、积分系数(KI)以及微分系数(KD)这3个参数, 因此, 如何整定这3个参数是PID控制器设计和应用的一个核心问题.
常规的PID工程整定方法需要依赖人工经验, 获得的PID参数往往无法取得满意的控制性能, 还需要人工在线调整. 近年来, 群智能优化算法, 如遗传算法(genetic algorithm, GA)、粒 子 群 算 法(particle swarm optimization, PSO)等, 在PID参数优化中得到了成功的应用[3–6], 但基于智能优化算法的PID整定方法依赖被控对象的准确模型, 而在实际生产中, 过程的准确模型难以获得, 这也限制了该方法的实际应用. 因此, 研究不依赖过程对象模型, 并减少对人工经验依赖的PID参数优化方法具有重要意义.
随着人工智能技术的发展, 以深度学习、强化学习为代表的机器学习方法在许多工业领域得到了成功应用[7–10]. 2015年, Mnih等人[11]提出了结合强化学习和深度学习的DQN算法. 该算法在雅达利游戏上取得了与人类玩家相当的水平, 这一开创性的工作推动了深度强化学习的发展, 同时也是当前主流深度强化学习算法, 例如近端策略优化算法(proximal policy optimization, PPO[12]、深度确定性策略梯度算法 (deep deterministic policy gradient, DDPG)[13]、双延迟深度确定性策略梯度算法(twin delayed deep deterministic policy gradient, TD3)[14]的基础. 强化学习利用智能体与环境进行交互, 通过奖励机制来引导智能体的策略朝着奖励最大化的方向前进. 这种奖励机制与控制理论中的反馈机制十分相似, 而且深度强化学习具有自学习的能力, 无需依赖过程模型, 能够在与环境的交互中自主学得环境特征并做出决策.
近年来, 不少研究人员在流程工业控制中引入深度强化学习, 设计的强化学习控制器取得了良好的控制效果[15–17]. 但是, 由于神经网络的不可解释性, 使得强化学习控制器只在一些仿真环境中进行了验证. 另一方面, 由于实际工业过程中绝大部分控制回路都使用PID控制器, 而由人工调整PID参数的过程与深度强化学习智能体与环境“试错”交互来学习最优策略的过程极为相似, 这也为PID控制器参数优化提供了新的解决方案.
相较于智能优化方法, 深度强化学习在PID参数优化中具有以下两个方面的优势: 第一, 启发式的智能优化方法依赖对象的精确模型, 而在工业过程中, 往往只能获得对象的近似模型, 这使得该类方法无法取得最优效果. 而由于深度强化学习是一种无模型的学习方法, 尽管在实际实现时也需要进行对象模型的辨识, 但其对模型精确度的依赖并没有智能优化方法那么高; 第二, 智能优化方法对初始种群的选择十分敏感, 在优化初期得到的PID参数造成的控制效果都是发散的, 使得该方法在理论上都无法进行在线优化. 而强化学习方法则能在奖励函数的引导下, 通过有限次的迭代进行逐步寻优. 因此, 近年来, 一些研究人员将深度强化学习引入到优化PID控制器参数的问题中. Shuprajhaa等人[18]将改进的PPO算法与PID控制器相结合, 智能体通过每一步改变PID控制器的参数来实现控制. Tufenkci等人[19]利用确定性策略梯度算法整定电机的PI参数, 并在Simulink环境中验证了其可行性. Liang等人[20]基于TD3算法提出了PID参数自整定算法, 并在两轮直立车进行了验证. Chowdhury等人[21]将TD3算法与软演员–评论家(soft actor-critic, SAC)算法相结合, 提出了一种自适应PID控制方法.
但是, 以DDPG, TD3为代表的确定性策略梯度算法是off-policy的深度强化学习算法, 其训练时需要随机从经验回放池中采样样本来训练Critic网络, 无法充分利用对网络更新作用更大的样本, 易造成Critic网络更新不稳定, 导致算法前期的优化效果不佳. 而体现在PID参数优化上的结果就是控制器的控制作用发散. 对于控制过程而言, 控制作用发散无论是在真实对象还是仿真对象上都是绝对不允许的. 对于强化学习而言, 在交互过程中控制作用发散意味着会获得大量的无效样本, 这些样本会减缓智能体的学习, 甚至破坏神经网络的训练. 因此, 需要改进深度强化学习算法来提升前期的优化性能.
为了提升强化学习的学习效率, 国内外研究人员针对经验回放机制进行了改进. Schaul等人[22]提出了优先经验回放机制, 在网络更新时根据优先级进行采样. 该机制虽然能够提升效率, 但是却引入了极大的计算开销. Zhang等人[23]提出了一种基于情节经验回放的强化学习方法, 根据每个情节(Episode)的累计奖励来对样本进行分类, 进而实现网络更新. Fan等人[24]在DDPG算法的基础上提出了基于多重指数移动平均评估的DDPG算法, 该算法根据设定的阈值分别从两个经验回放池采样不同数据, 但阈值的选择依赖经验. 由此可见, 通过改进经验回放机制来采样更多有利于神经网络更新的样本, 能够有效提升深度强化学习训练的效率.
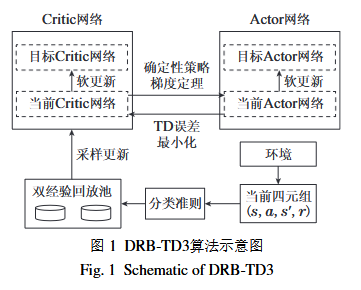
针对上述问题, 本文引入分类经验回放机制, 提出了基于双经验回放池TD3算法(TD3 with double replay buffer, DRB-TD3)的PID参数优化方法. 与文献[18]和文献[20]获得的自适应PID控制策略(控制器参数在每一个控制步都会变化)不同, 本文方法能够直接获得整定好的PID参数, 应用范围更加广泛. 此外, 与文献[19]相比, 本文进一步引入了双经验回放池, 提升了神经网络的训练效率. 在加快奖励函数收敛的同时能够有效避免控制曲线的发散. 本文的具体工作如下: 首先使用TD3算法训练Critic(评价)网络和Actor(策略)网络, Actor网络输出直接用来控制被控对象; 针对Critic网络训练前期效率低的问题, 引入双经验回放池: 将样本分为两部分, 从TD误差更大的样本池中采样更多数据. 在训练时通过动态维护TD误差的均值, 提升Critic网络的拟合效率, 使得PID参数在线优化时更为稳定. 最后以二阶和一阶加纯时滞系统为仿真对象, 并与PSO算法优化PID参数的方法进行对比, 验证了所提方法的可行性, 且所提方法要优于PSO算法.
结论
本文提出了一种基于双经验回放池TD3算法的PID参数优化方法. 在TD3算法的基础上, 增加了双经验回放池机制, 采样更新时选择更多有利于策略网络参数更新的样本进行策略迭代, 提升了算法在PID参数前期学习时的效率, 有效避免了学习过程中系统输出的发散. 最后, 通过实验验证了所提算法的可行性与有效性. 未来的工作考虑将深度强化学习方法进一步应用于时变对象的PID在线整定.
作者简介
钟皓俊 硕士研究生, 目前研究方向为强化学习与智能控制;
王振雷 教授, 博士生导师, 目前研究方向为智能优化与控制策略.
https://blog.sciencenet.cn/blog-3633987-1526578.html
上一篇:【论文推荐】基于轮询协议的可再生能源微网分布式块滚动时域估计
下一篇:《控制理论与应用》和“Control Theory and Technology”期刊2025年度优秀论文评选通知
