博文
且读且议论(5):矩阵!矩阵!!矩阵!!!
|||
Loet Leydesdorff和Liwen Vaughan于2006年发表于Journal of the American Society for Information Science and Technology (JASIST)上的一篇文章,题目是Co-occurrence Matrices and their Applications in Information Science: Extending ACA to the Web Environment。
我觉得这是很多对共现分析感兴趣的人必须读一读的文章,所以让今年毕业的一位本科生(隋明爽同学)翻译了一下,并且在研究生抄读会上进行了讨论。这篇文章回答了很多人经常遇到的问题:到底向SPSS里输入什么矩阵?
惭愧的说,2006年的时候,我也指导了一位本科生想做这方面的研究,无奈才疏学浅,没有得到理想的答案,看了大师的文章,知道还是底子太薄了。
学生翻译的肯定有很多错误,我也认真滴帮着改了一下,说实话,战战兢兢,有些翻译穿凿附会,尤其是翻译到后面,竟然出现了“裁判员”的字样,惊觉这里可能有过一场论战,可别弄错了误伤了谁啊。
共现矩阵及其在信息学中的应用:将ACA扩展到网络环境
摘要:
共现矩阵,如同被引、共词、和共链矩阵,已经被广泛应用到信息学中。然而,其中的混乱和争议阻碍了数据正确的统计分析。在我们看来,问题的核心在于对各类不同矩阵的本质的理解。本文讨论了对称同被引矩阵和不对称引文矩阵的差异,并探讨了这两种矩阵各自适合于什么样的统计技术。我们认为,相似性度量(如Pearson相关系数和余弦系数)不应该应用到对称的同被引矩阵,但是可以应用到非对称的引文矩阵,以推导出其相似矩阵。本文将用例子说明这个论点。本研究也将共现矩阵应用万维网环境中,万维网中的数据属性及数据的获取方式都和传统的SCI数据库不同。本文利用了一组用谷歌搜索引擎收集的数据,分别用多元分析的传统方法和一种基于社会网络分析和图论分析的新型可视化软件Pajek进行分析。
简介:
共现矩阵,如同被引、共词、和共链矩阵,为我们描绘(映射)和理解核心文献集的结构提供了有用的数据。对这些共现数据有不同类型的分析方法,关于这些方法汇集了很多文献,构成了信息科学的一个重要领域。然而,对于这些矩阵的性质和适当的分析方法仍然存在着混乱。例如,从Ahlgren,Jarneving和Rousseau (2003,2004a 和 b),White (2003,2004),与Bensman(2004)之间关于Pearson相关系数和余弦系数在作者同被引分析(ACA)的讨论中就可见一斑。在我们看来,作者在ACA中所用的共现矩阵本身就是临近数据,在映射绘图之前不需要转换。我们建议应该尽可能使用非对称矩阵中,如果做可视化映射亦可以从这个矩阵推导出共现矩阵的属性。
由于共现矩阵将来可能广泛应用到网络的研究,如何处理和理解共现矩阵的问题已经上升到了一个新的层面。在这种情况下,人们常常可以不再检索构建共现矩阵所需的整个文档集,而是可以通过布尔逻辑检索直接构建矩阵。我们将讨论各种矩阵的性质和围绕他们的分析出现的问题,以期能够澄清一些混乱,从而促进信息学领域的进一步发展。我们的论证是方法论的,但是我们将使用基于ISI的信息学领域的ACA为例,此例曾在本期刊中作为讨论的课题(Ahlgren et al.,2003,2004a,2004b;White,2003,2004;Bensman,2004;Leydesdorff,2005)。下一步我们将把该数据集和分析扩展到网络环境中,以谷歌学术搜索引擎检索相同的学者群。
2.对称共现矩阵VS非对称引文矩阵
2.1对称共现矩阵
Small率先提出同被引分析(参见Marshakova,1973)。他构建同被引矩阵如图1所示。矩阵中的每个单元的数字是两篇文章被共同引用的次数。例如,文献1和文献2共同被引用10次,而文献1和文献3共同被引用20次。当时(70年代初)由于计算条件的约束,Small不得不用ISI数据作为列表而不是用共现矩阵。运用单连接聚类,Small可从该数据中提取到同被引图谱,而不用产生矩阵(Leydesdorff,1987)。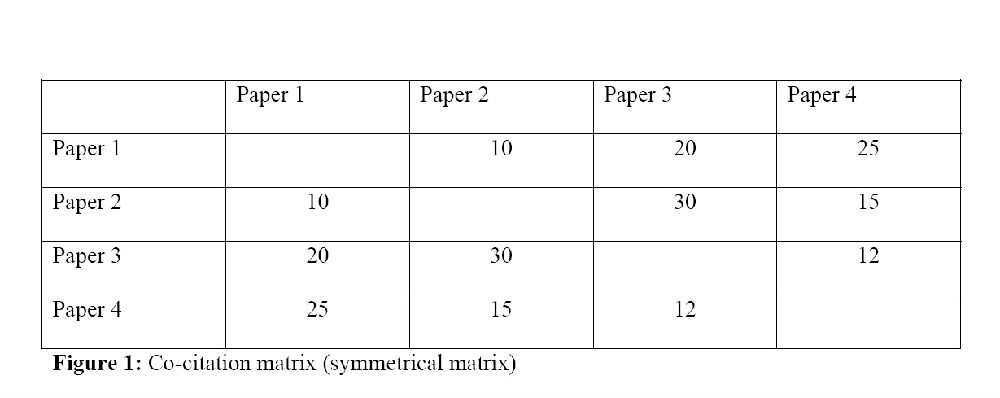
White 和 Griffith (1981)将同被引分析的概念引申为作者同被引分析(ACA),对该领域的发展有着突出贡献。他们运用第一作者,而不是文章,作为分析的单元;与同被引分析不同,他们把被引作者而不是被引文献作为分析单元。但是他们的矩阵本质上是一样的,如图一所示,除了用作者1,作者2等代替了文献1,文献2等。Small,White 和 Griffith都用了多维标度(MDS)和聚类分析来分析他们的数据。White 和 Griffith也运用了因子分析。不同之处在于,Small用Jaccrad指数进行了数据归一化(从ISI数据库获得的原始同被引数据),而White 和 Griffith对此运用了Pearson相关系数。Small和Sweeny (1985)开始使用余弦作为替代相似性度量指标(Salton & McGill,1983)。
图1形式的矩阵就是一种临近矩阵。如 Kruskal(1978年,第7页)所定义的:“所谓临近性是指表示两个对象是多么相似或者多么不同的数字,或者被感觉是,或者任何此类度量。”临近矩阵可以是相似性矩阵或不相似性矩阵(Cox 和Cox, 2001, 第九页)。同被引或合著者矩阵是相似性(非相异性)矩阵。单元格中的数字越大,两篇文章(或两个作者)之间越接近。相似矩阵可以输入到多维尺度软件直接生成一个地图,它显示了文献或作者的相对位置。映射绘图的原理是临近性越高(两个单位间越相似),这两篇文章或这两个作者在地图中的位置就越接近。
2.2非对称引文矩阵
另一种构建引用数据矩阵的方法是以图2所示的形式。以作者同被引为例,在此矩阵中,行是引用文献,列是被引文献。因此,文献A被文献1,4,5,引用,文献C被文献2和文献3引用。
此矩阵与图1所示矩阵十分不同。图1中的矩阵是一种对称矩阵:(1)行和列是相同的对象;(2)行列数相同。(3)矩阵中的数据关于对角线对称,所以一半的矩阵就足以涵盖所有数据。显然,图2中的矩阵不具备上述三个特点,而且该矩阵是非对称的。进一步讲,图2中的矩阵不是临近测量,所以该矩阵不能直接输入做MDS。然而,我们可以将这种属性矩阵转换为临近矩阵。“将不适用于MDS的非临近矩阵转换为临近矩阵最常用的方法就是计算一个表的行(或列)之间整体相似或不相似性的一些度量”。[...] 而推导出整体临近性度量的最常见方法是计算变量间的相关性或(欧几里得)平方距离(Kruskal,1978,第十页)。欧几里得距离矩阵可以认为是一种相异矩阵,而Pearson矩阵可以认为是相似矩阵。然而,Ahlgren等人(2003)认为,Pearson相关系数形式上不是一种相似性度量,而是对线性依赖性的一种度量。(见下一节的相似性与相异性矩阵的讨论)。
我们着重谈Pearson相关系数,但类似的推理可应用于余弦作为相似性度量,或以欧几里德距离作为相异性度量(Ahlgren等人,2003年,第551)。Pearson的r值作为一种临近度量可能是负值,可通过(r+1)/2进行线性变换,转变为0和1之间的值来解决。通过将Pearson相关性应用到表2中的数据(列成对的相似性),然后用(r+1)/2进行转换,得到如表3所示的相似性矩阵。这种相似矩阵具有了表1中对称矩阵的所有三个属性,在表2中的数据中,我们可以看到文献A和B被文献集中相同的文献引用(文献1,4,5),在表3里它们的相似系数为1就表明了这种关系。相反,文献A和C被文献集中完全不同的论文引用,因此在表3里,它们之间的相似系数为0。
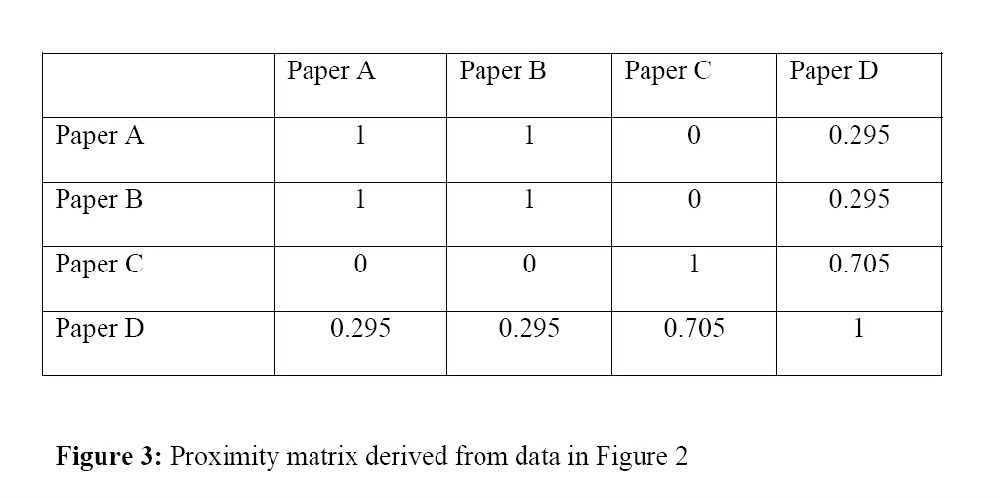
在非对称矩阵(图2)里,被引用的文章被当做是引用文献的属性,因为被引文献出现在引用文章的参考文献列表。文章A和文章D有三分之二的引用文献相同,所以它们之间的系数是0和1之间的,如0.295。
综上所述,在同被引分析可以用Pearson相关系处理非对称的引用矩阵,然而,将Pearson系数应用到对称性临近矩阵中是存在问题的。White(2003,第1251)指出,戴维森(1983)在其有关多维尺度的教科书首页上,提及到Pearson系数可以作为两种基本的临近度量方法之一。不过,在该书中,Pearson相关系数常用于构建那些没有做过临近度量的数据的临近矩阵。同被引矩阵本身就是一个临近矩阵,因此不必再运用相似性度量来构建临近矩阵。相反,这样做甚至可能扭曲数据,我们可以通过一个实例来说明。
2.3一个例子
例子中的数据(见表1)拷贝自SPSS(1993)。该表显示的是美国十大城市的飞行里程。这些距离数据是从二维地图中产生的,因此人们可以直接评估用这些数据重新构建的地图的质量。
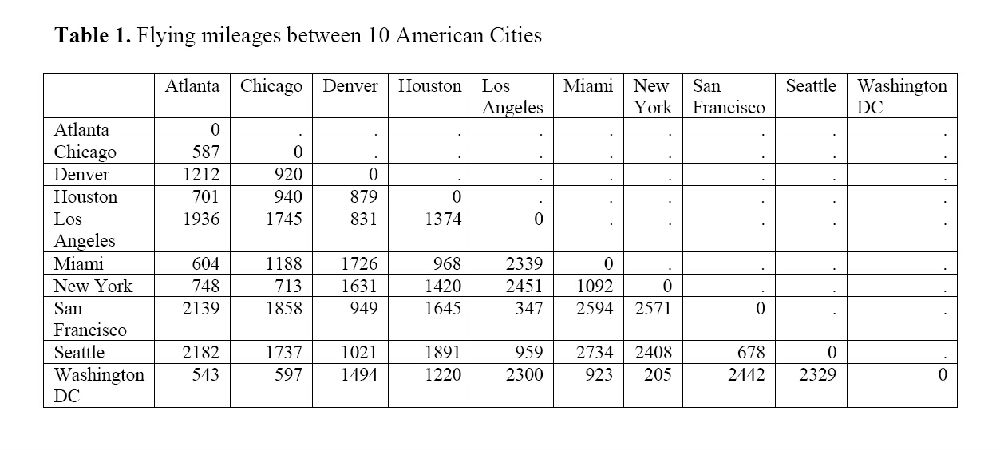
显然,这是一个对称的临近矩阵。数据表示的是相异性,数字越大,城市之间相隔越远,即它们在定位上就会有更多的不同。将矩阵输入到SPSS中,选择PROXSCAL作为MDS的一个选项,我们得到了图4,一个关于这些城市几近完美的相对位置绘图(这些位置是相对的,地图的东部和西部的扭转的。然而,由于位置的相对性,MDS的结果可通过自由旋转来解释)。
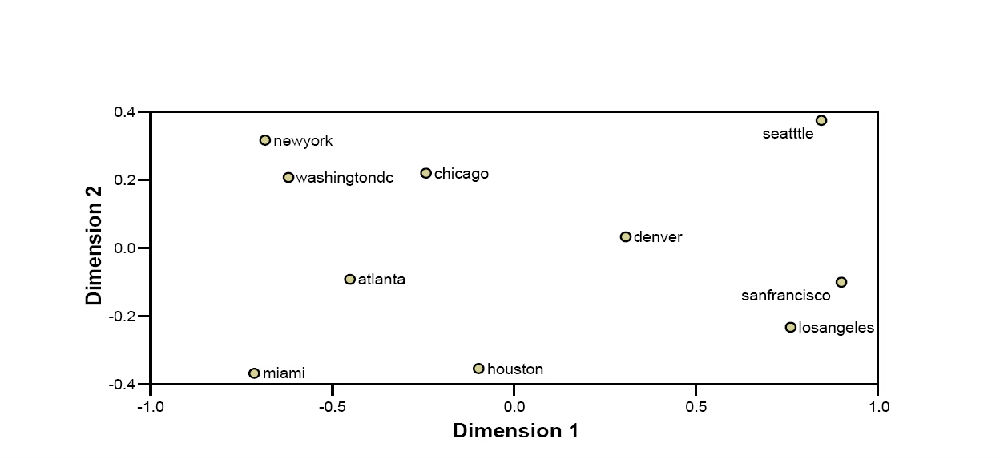
图4:使用原始距离矩阵绘制的十大美国城市MDS地图(PROXSCAL)(归一化的原始应力为0.0001。
如果将表1中的数据转换为Pearson系数,再用这个新矩阵绘制MDS,得到的这十个城市地图则十分扭曲,且其归一化原始应力非常高(0.11341)。
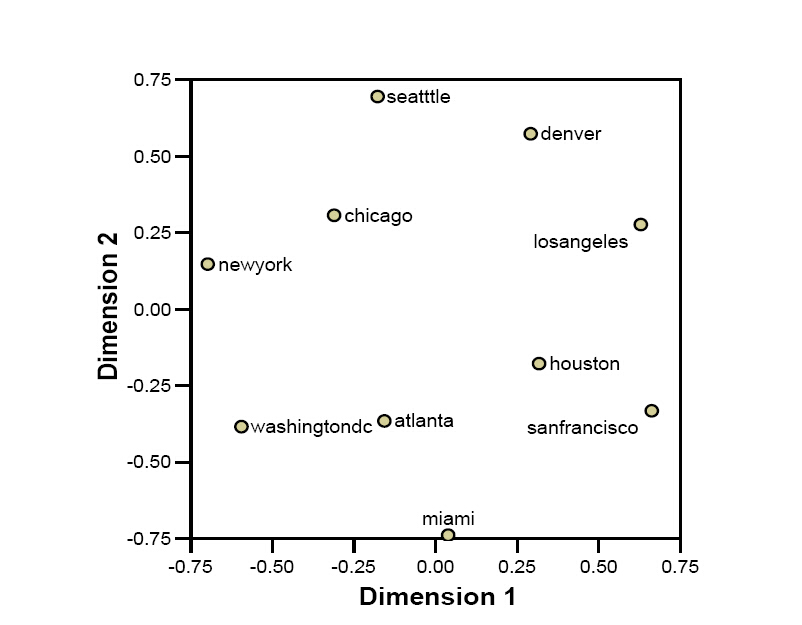
图5:使用Pearson相关矩阵绘制的十大美国城市MDS地图(PROXSCAL)(归一化的原始应力为0.11341)
显然,图5相对于图4并没有改善(应力变得非常高)。通过使用Pearson相关系数代替城市间的距离,地图被扭曲了。例如,洛杉矶相比于旧金山更靠近西雅图,而纽约相比对华盛顿特区更靠近于芝加哥。Pearson相关系数依据均值将数据进行标准化,而被当做变量的共现模式(用Pearson系数加以表示)在某些情况下与网络中临近性是不同的。
与可明确绘图映射的二维地理数据不同于,知识结构的测定(如通过合著作者或同被引数据的测定)通常是多维度的。多维尺度分析(或因子分析)搜索空间中的n维数据在低维上的投影。MDS使用应力测量作为适用性指标,但这只是一种探索性指标。
最终,分析人员还要在定性层面上理解所表达的知识结构的表现形式。换句话说,用合著者数据来多维表达知识结构可以很好,但是这种表达不能很容易的投影到二维或三维结构上。因子分析可以让我们在更高的维度、精确的数字(算法的)上研究数据缩减的质量,因此可能有助于理解几何可视化投影的质量。
3.相似性VS相异性度量
如上所述,有两种类型的临近度量:相似性和不相似性。显然,这二者是相反的,所以
在MDS中应区别对待它们。在最新的SPSS版本中,MDS有两个选项:ALSCAL和PROXSCAL。ALSCAL设定输入的是相异矩阵,而PROSCAL允许指定临近度量时相似性还是相异性。毫无疑问,同被引是一种相似性度量(两篇文章或两个作者同被引次数越多,二者之间就越相似)。所以应使用PROSCAL的相似性选项。如果人们弄反了这两种类型的相似性度量,该映射绘图的结果将是错误的。例如,表1中的美国城市间的行程里数提供了一种相异性测量,如果我们在MDS中将其指定为相似性度量,其结果将是一个非常扭曲的地图(由于空间限制生成的地图此处略去)。
在SPSS的早期版本中,只有ALSCAL选项是可用的(只有相异性度量)。在这种情况下,同被引矩阵在输入SPSS之前,应该被转化为相异矩阵。 Kruskal和 Wish(1978,p.77)明确指出“如果临近值是相似性度量,那就必须把它们“上下颠倒”为相异性度量,如形成的相异性度量=(常数-相似性度量),其中的常数应审慎选择。”如果相似性度量在0,1之间(如上面的例子,运用Pearson系数获图3所示矩阵的临近矩阵),常数可用1,即相异性=(1-相似性)。我们对该公式进行了广泛测试,发现经从相似性到相异性之间正确转换之后的相异性度量,和直接运用相似性度量所得的映射地图,总是相同的。
MDS广泛使用的一种形式是不对称属性矩阵,如图2所示。MDS是当时因子分析、聚类分析等多元分析分析中的一种主要的可视化技术。在这种情况下,该数据被当做相异性变量分析,因此ALSCAL和PROXSCAL都可以使用。欧式距离是默认的相异性度量。对于输入的非临近度量的数据,PROSCAL可以构建临近矩阵。因为我们在以下各节中研究这两种不同类型的矩阵,我们整个研究中将使用PROSCAL。请注意,一种可视化技术如MDS是数据的二维或三维表示,而例如因子分析,加入了旋转数据的可能性以得到一个对于该几何代表性结构的更高维度和定量的理解(Schiffman等人,1981)。
4.作者同被引的一个实例
让我们回到在本杂志上几个前面所讨论的作者同被引分析的例子(Ahlgren等,2003;白,2003年; Bensman,2004; Leydesdorff,2005),并相当详细的讨论不使用对称的共现矩阵,而是文献-引文的非对称矩阵的效果。
Ahlgren等人(2003:554)从WOS上下载发表在《科学计量学》的430篇文章书目数据,以及在1996-2000年期间发表在《美国学会杂志信息科学与技术》(JASIST)483篇文中的书目数据。根据913篇文献的参考文献中,他们构建了信息检索领域和文献计量学领域各12位作者的共现矩阵。他们的论文提供了这些作者的共现矩阵和Pearson相关表。
我们重复了他们进行过的分析,以获得原始的(非对称)的数据矩阵。运用相同的检索策略我们于2004年12月18日,检索到469篇《科学计量学》的文章和494篇JSSIST的文章。由于ISI有时会在后来把对以前发表的文献陆续加入数据库,论文数稍微高一点与该实际是一致的。因此,我们忽视了这些差异。
4.1描述性统计
从检索到的(469+494=)963文献中,902篇包含了21813篇引文,其中279篇对所研究的24位作者中的两位以上的作者至少有一次同引。
在279篇引用文献集中,没有只包含一篇引文只引用一个作者的引用记录。因此,可认为该数据集是很好高被引作者集。图6显示同时引用本研究中多达10位作者的文献数。
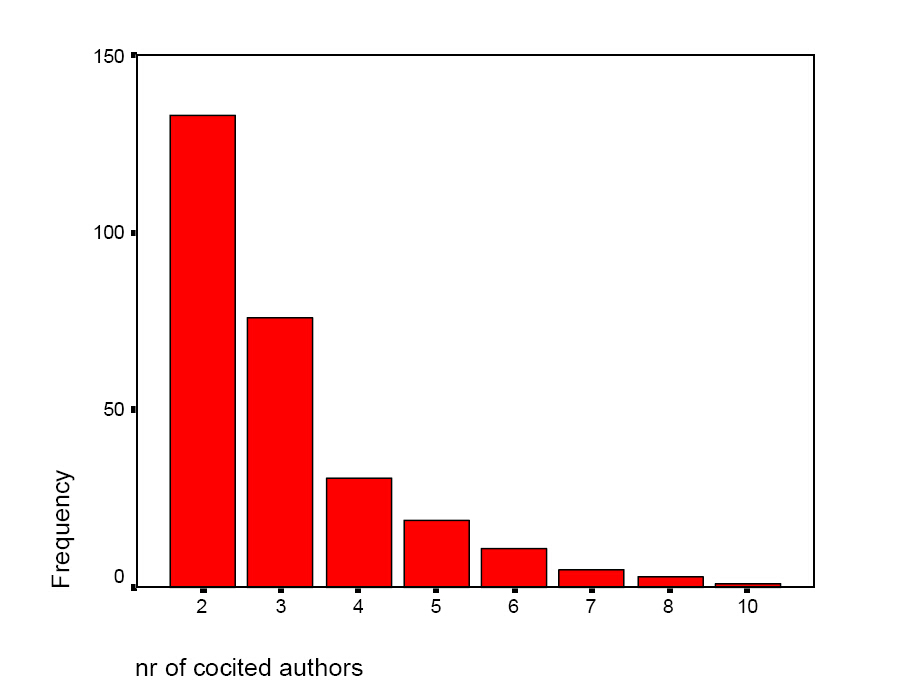
图7显示了这些引用文献集的作者总被引次数。注意,科学计量作者平均引证率为44.6(±14.8),而信息检索作者平均引证率较低——26.1(±6.5)。引用率是具有领域特异性的。

下面我们从描述性统计转移到数据的分析。
4.2非对称矩阵的数据分析
可以将该数据导入到SPSS,对非对称矩阵进行各种形式的多变量分析。例如,人们可以使用Pearson相关矩阵。表2提供了24位作者的Pearson矩阵。这些Pearson相关性与Ahlgren等作者提出的有很大的不同,因为他们将Pearson应用到对称同被引矩阵。例如,Van Raan 和 Schubert 在后面的表9中的同被引模式的相关系数为0.74,而我们发现他们的引用模式之间是负相关的(r=-0.131,P<0.05)。从对称的共被引矩阵导出的Pearson相关系数都很高且显著,因为这个矩阵是对称的,所以所有的值和关系都出现了两次。
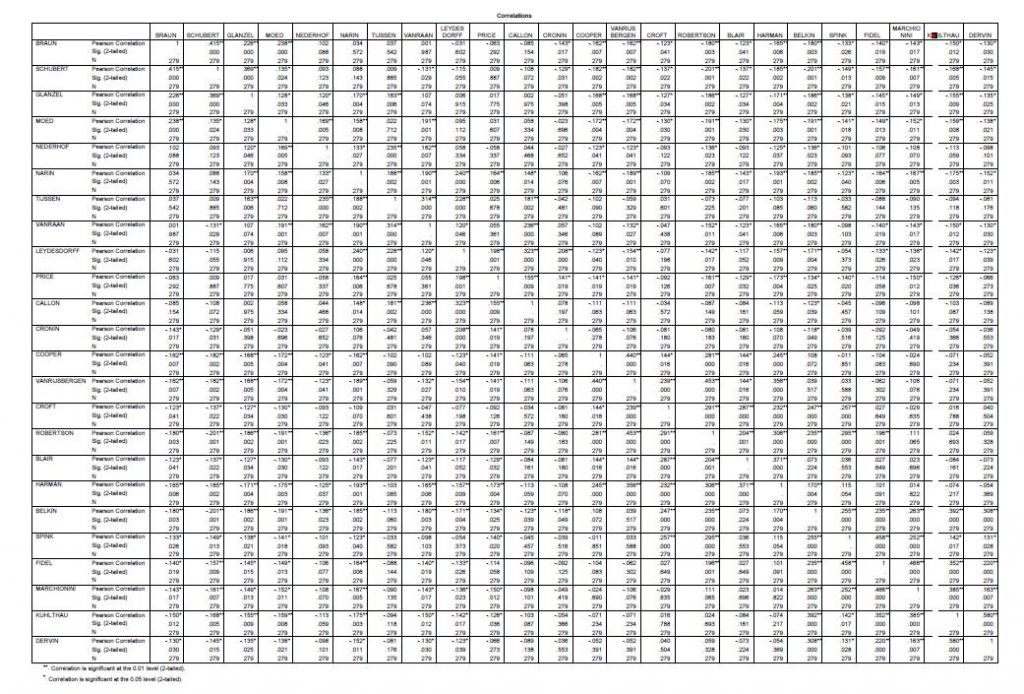
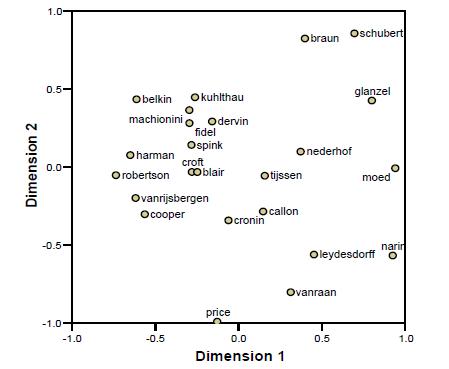
图8所示,输入非对称矩阵进行MDS的PROXSCAL结果。可视化分析显示,信息检索作者沿单一(几乎水平)轴分布,而科学计量学作者沿垂直轴分布,且信息检索作者比科学计量学作者更有条理。矩阵的因子分析证实了这一观察,使得能够用定量解释来揭示图象。
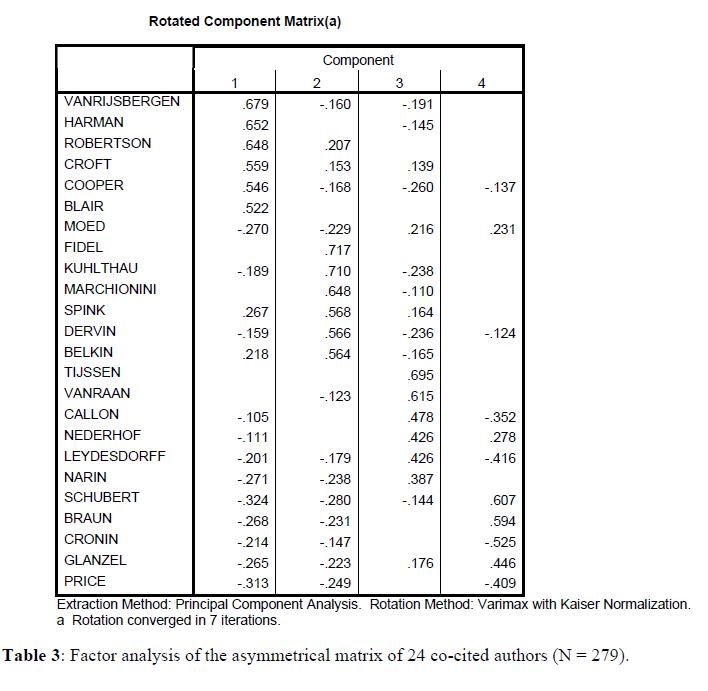
选择4个因子能使我们理解两组作者之间的关系和每个组内的精确结构(表3)。前两个因子的因子载荷专门表示信息检索作者。这两个因子解释了矩阵中26.8%的公共方差,这两个高载荷因子对于科学计量学作者只有14.2%。这意味着,信息检索作者之间的同被引比科学计量学作者之间的更紧密:即他们的同被引模式比科学计量学作者的更高度相关。因子1和2的分野以及因子3和4之间的分野显现了不同的性质。Braun,Schubert和Glänzel 是一个单独的组;他们同被引主要是因为他们的共同地址(直到最近)在布达佩斯,且他们合著了很多文章。 Cronin作为一个被引作者,其位置特殊,且与Derek de Solla Price高度相关 。他和Price的引用模式不与上述4个因子的任何一个相关。
根据定义,构建Pearson相关矩阵是因子分析的第一步。如果我们在PROXSCAL中输入表2中提供的Pearson相关矩阵作为相似性测量,我们得到图9。

虽然这张图片让我们能同样的观察到数据分为两个组(左侧的信息检索科学家和右侧的计量学家),但是其图片信息量少了很多,且应力更显著变差。因为统计中假设其正态分布,Pearson相关矩阵比原始数据矩阵信息量更少。这样,由于我们把归一化数据输入到MDS中,所以得到一个扭曲的图像。
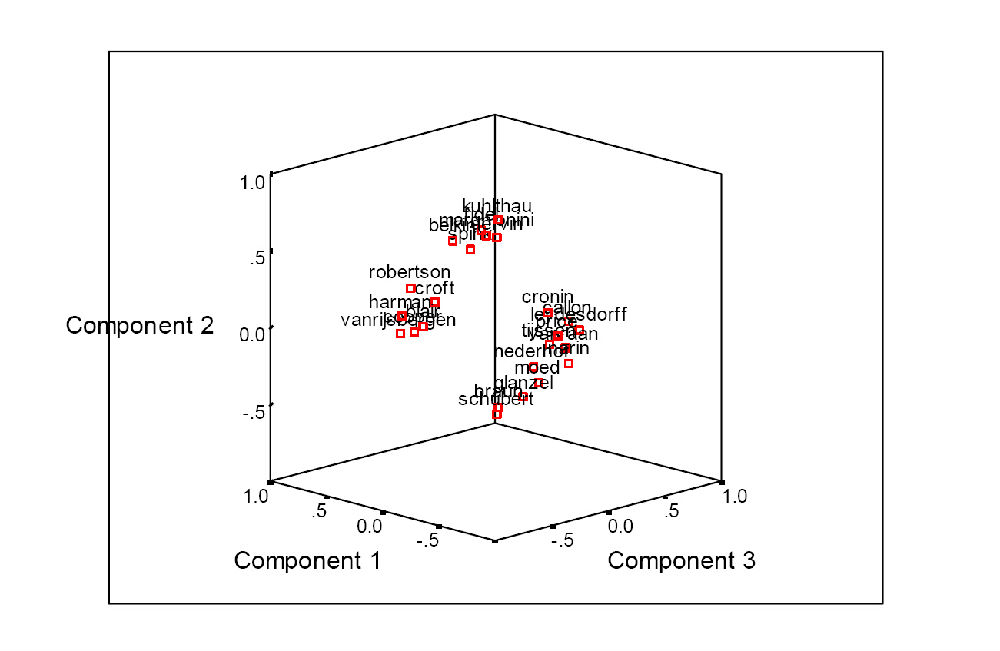
而因子分析通过旋转矩阵使我们能够获取其基础结构,而不必考虑是否服从正态分布的假设(Kim & Mueller, 1978)。此外,因子分析可使我们在参照矩阵的特征向量对Pearson相关矩阵优化后,绘制出散点图。在三维空间中的相应表示说明了两组之间的主要区分和每个组内的精细结构。
4.3同被引矩阵
如果把同被引矩阵到直接输入PROXSCAL也可以中获得相似的结果(图11)。然而,人们必须把同被引数据当做定序数据,以减少内应力,也就是提高拟合。Ahlgren等 (2003, at p. 558)提出应该将这些数据作为定序数据( Siegel & Castellan, 1988, at p. 225)。两组分界很清晰,每个组都有一个与上述因子分析讨论的区别相关的内在维度。

当我们将相同的技术运用到基于同被引矩阵的Pearson相关矩阵作为输入——如ACA的一般实践——我们得到图12:

Pearson相关矩阵不是定序数据,因此不能用其他测量标度来减少应力。尽管在图12中有部分原始结构得以展现,这种数据的表示还是比原始矩阵含有的信息量要小,应力则又一次相对较高。仍然可以识别部分结构的原因是数据集的特殊性和不寻常性:这两组作者差别十分明显,几乎没有重叠之处 (Ahlgren et al., 2003, at p. 555).。
总结起来看:使用Pearson相关的对称共现矩阵歪曲了共现数据中所含的信息。如果该数据结构是健壮的,如两组研究人员的数据集分界清晰,人们还是可采取这种结构的。然而,这只是一个例外而不是常规的。美国城市之间的距离的例子展示了把Pearson相关系数应用到对称临近矩阵后如何扭曲其结果,即使在简单的地理和二维情况下。当人们进行到多变量分析,如因子分析(Bensman,2004)时,使用Pearson系数到非对称矩阵上的优点变得明显。然而,在这种情况下,Pearson相关系数应该运用到非对称矩阵,而不是对称同被引矩阵。对于使用MDS表示对称临近矩阵,人们最好把原始矩阵(如同被引矩阵)输入到分析中。
4.4社会网络分析
最近,基于图论的社会网络分析可视化技术有了长足的进步(Scott, 1991; Wasserman & Faust, 1994)。虽然我们以上讨论的非对称矩阵可以看做是社会和行为科学的一个典型设计,这些新技术并没有把变量(链接)作为案例(节点)的属性,而只是研究其链接,并用链接解释节点。网络的发展是这些研究的主题。同被引数据可以看做是文本之间的链接数据,而被引文献则是文本的属性。然而,无论是在方法论和理论假设的方面,社会网络分析的传统与信息科学共现数据的分析是有所不同的。
我们认为上述的非对称矩阵比对称共现矩阵包含更多的信息。后者可以通过数学的方法由前者矩阵和其转置矩阵相乘得出(Engelsman & Van Raan, 1991)。共现矩阵由原始(非对称)矩阵推导出来,因此含有较少的信息(Leydesdorff, 1989)。另外,人们可以通过使用欧几里德距离度量,或通过使用Pearson相关或余弦产生一个相异、相似性矩阵。然而,网络分析学家对因子之间的交流结构更感兴趣,所以将链接作为重点分析单位。两个数据集链接的数量被定义为在各自数据集中出现次数的乘积。例如,如果一个作者在一个文献集中被引用两次,在另一个中被引用三次,这种“隶属关系”的数量——因为这种测量被称为社会网络分析——是6,而共现的数目只是2。
但是这种定义上的差异并没有造成绘图上的不同,因为Pajek的可视化算法几乎成为网络可视化标准的程序,它首先将所有的值降为二值变量(0和1),此后使用户通过变线尺寸来可视化。图13显示了我们运用Pajek和Kamada & Kawai的基于弹簧算法(1989)可视化共现矩阵。该算法通过寻求最小化弹簧系统所含能量来减少应力。可以把它看做等同于非度量多维标度。

使用社会网络分析工具做共现数据的可视化和分析有几个优点。首先,在理解互联网操作的压力驱使下,人们对发明更加综合性地阐述网络的算法越来越感兴趣,同样的事情也发生在生物和物理系统的其他网络(Da F. Costa et al., 2005)。社会网络分析受益于图论理论的发展。同样可视化技术也呈现了爆炸式发展。
使用PROXSCAL可能比使用Pajek更适用于同被引数据的可视化,因为PROXSCAL可以将衡量尺度考虑在内。然而,如上所述Pajek可允许用户以该线的粗细程度表明关系的强度。PROXSCAL和其他MDS程序要求用户自己绘制相关线路和类团。在上面的例子中,图13显示了类似于图10和图11的结果,因为所研究的数据集是一样的,其中包含了两个不同作者集;把同被引矩阵缩减到二值矩阵并不显著影响其结果。
我们整个研究的中心思想是,人们应意识到:网络数据不等同于数据属性。从网络的角度看,例如,不妨把重点放在网络的结构是如何随着时间的推移而发展的。何时刻何人执行了何功能?然而,科学计量学家常把有兴趣于特定的节点(作者)以及他们是如何随时间发展的,而网络分析师可能会讨论其结构特点如“功能等同”和“结构洞”(Burt, 1982, 1995)。这两种传统可以被视为是核心矩阵的潜在互补的两个方面。上面我们也提到,如果有核心矩阵,通过分析非对称矩阵可对该数据深入了解,但我们现在将转向当没有可用的基础底层数据的情况。
5.ACA扩展到互联网研究
在Web环境中,检索原始引用(如在图2中所示),然后使用Pearson系数来构造一个相似性矩阵(如图3)的方法往往是不可行的。网页集的大小对于少数研究员来说处理量过于庞大。如果我们要研究的是网络共链分析,那么图2那样的形式是很难得到的。因为人们还需要外链(outlink:链接从一个网页外出)的数据。没有一个现有的搜索引擎可提供对外链接搜索功能。然而,一些搜索引擎,如雅虎和谷歌可以搜索反向链接(链接进入,或指向一个网站)。雅虎也有一个共同的链接的搜索功能,可以将数据收集为图1 所示的形式。也有人开展过类似于同被引分析的共链分析(如 Vaughan & You, 2005),并已发现网络可以作为一个非常有用的数据源。
在下面的例子中,我们通过使用搜索引擎在http://scholar.google.com/将作者同被引分析扩展到Web环境。我们在网络上搜索以上的24位作者的共现情况,运用名首字母和姓作为检索策略,在谷歌学术http://scholar.google.com/advanced_scholar_search上。所有搜索于2004年11月27日进行。

虽然两个组在这种表示中仍然清晰可见,Van Raan获得了这两个子网络相关的枢纽的位置。一些信息检索科学家在Web上不可见,但其中某些人比科学计量学家联系还要紧密。在科学计量学家组内,我们可以看到Van Raan主要吸引了“荷兰”组,“匈牙利”组也表现出较强的相关性。
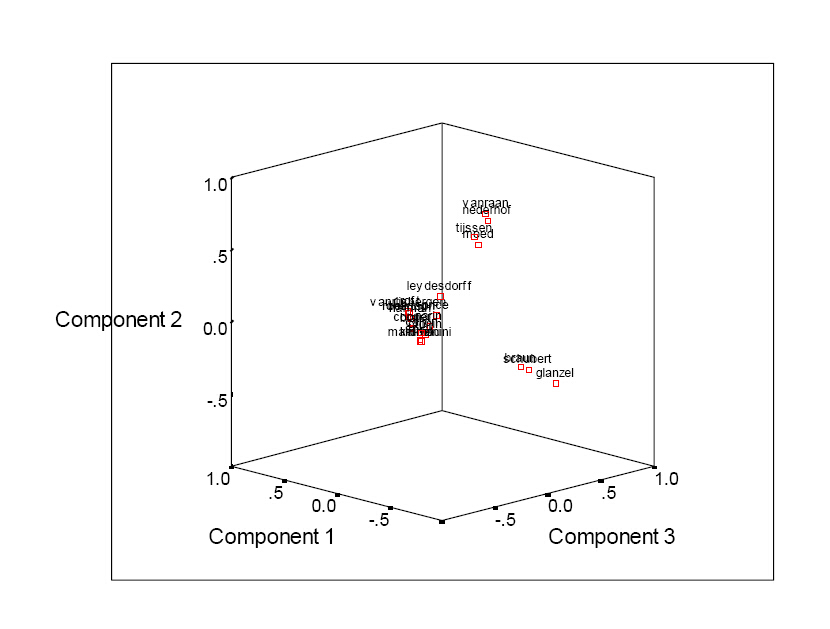
用因子分析可以进一步理解和解释这些结果。图15表明结果。第一因子(说明此矩阵的方差只有11.25%)由Croft和Van Rijsbergen再次领衔。第二个因子(8.37%)可以被视为一种“Leiden”(荷兰莱顿)因子,而第三个因子(6.47%)可以作为布达佩斯地址(前)的科学计量学家群的区分。此模式与图10中基于ISI引用数据所示的有所不同,因为其机构部分被增强如图15。
图10和图15之间的相似性和差异(即ISI数据和网络数据)与ISI引用的早期研究对比网络引用分析是类似的。在图书馆学和信息科学(Vaughan & Shaw, 2003)和其他学科(Vaughan & Shaw, 出版中),ISI引文数与网页引用次数相关,但网络引用只有约30%至40%代表知识上影响。因此,相比于图8和图10,机构和国家成分在图14和15分别增强。
不过需要提醒的是,网络引文数据的稳定性是值得商榷的(Vaughan & Shaw, forthcoming; Wouters et al., 2004)。此外,网络数据比高度编码的ISI更容易受到操控(Garfield, 1979)。对ISI引文所做的几十年的研究都帮助我们理解了引文,而对网络引用研究则十分有限。虽然网络信息计量学在近几年(Thelwall, Vaughan, & Björneborn, 2005)快速发展,但仍需要更多这方面的研究。本文讨论将共现矩阵扩展到web环境中就是向着这个方向努力。
6.结论和讨论
共现矩阵,如同被引、共词、共链矩阵已被广泛应用于信息科学的研究。然而,关于正确统计分析的应用,混乱和争论仍然存在。问题的实质在于对不同类型的矩阵的本质的理解。本文讨论了对称同被引矩阵和非对称被引矩阵以及可应用于这些矩阵的适当的统计技术之间的差异。其结论是,Pearson相关系数不应该被应用到一个对称的同被引矩阵,但可以应用到非对称被引矩阵,以获得分析所需临近矩阵,用于如多维标度。本文还提出相似性和相异性矩阵之间有明显的区别,并且我们展示了如何使用这些统计软件如SPSS时应如何定义。并用实例支持我们的分析参数。
让我们进一步想想:尽管地理距离有衡量标准,但“知识结构”并没有一个正确的测量方法。同著和同被引数据本身只是对抽象结构的探索性表示。但是,我们争论的要点不是数据质量水平问题,即作为知识结构指标,一种共现数据的类型是否比另一种更有效或可靠(Leydesdorff, 1989)。我们要表示的是关于方法论的问题:如果分析者可以使用基础的非对称数据矩阵,那么相似或不相似性只能在适当的归一化后表达(例如,使用Pearson相关系数或Salton的余弦)。然而,共现矩阵已经是这个非对称矩阵的概要统计:它含有的信息减少了,但也可以直接用于映射。
这场争端的一位裁判员提出人们可能因为理论上的原因还是偏喜欢把共现矩阵转换为相似矩阵,比如,使用共现相似矩阵,研究者就能够比较合著分布,而不能比较合著计数。我们认为,这种说法把数据收集阶段可能出现的局限和数据分析阶段在方法上的决策混淆了。如果研究者除了共现数据以外没有其他的数据可以用(如互联网研究的案例),那就只好把这些数据输入到MDS或因子分析之类的以临近度量开始的统计程序中,因为这是获得合著分布的唯一途径。然而,人们最应谨慎运用Pearson相关的共现矩阵,因为正如我们上面所示(当比较Van Raan和Schubert的研究的时候),这种数据操作会改变相关性的信号。如果原始数据可用的话,人们应倾向于使用原始(即非对称)数据矩阵作为统计分析的输入。此外,人们可以从这种非对称矩阵中获得共现矩阵开展其他的统计分析,例如,利用Pajek/ UCINET的“Affiliations”功能,但没有对它的相关系数的进一步处理。
本研究将共现矩阵扩展到网络环境应用中,现有网络数据的属性以及由此而来的数据收集方法均与从传统的数据库如ISI不同。本文使用谷歌学术搜索引擎收集了数据集,以传统的因子分析和新的可视化软件Pajek进行基于社会网络的分析,并指出了Pajek在分析共现数据中的局限性。本文的唯一目的是澄清围绕矩阵性质和共现矩阵应用的问题,因此有助于信息科学这一领域的进一步发展。
https://blog.sciencenet.cn/blog-82196-808057.html
上一篇:文献计量学投稿中经常遇到的败笔
下一篇:书目共现聚类分析的视频