博文
《新智元笔记:跨层次结构歧义的识别表达痛点》
|||
一个困扰我的问题是跨层次结构歧义的表达:“他要整个高大上的节目献给全国人民”:

“整个”分析成定语。但口语中,它还有动词谓语的可能:“整个”=“整出(创制)一个”。上面示意了一下,为表达识别出来的歧义,这里需要打破 base XP 的框框。第二条依存关系路径是:“要”是谓语“整个”的儿子(情态),“节目”也是“整个”的儿子,是其宾语(O)。值得注意的是,这个歧义表达要求短语内部的定语跳出来做句子的谓语。
层次纠缠的结构歧义的表达,如果不生成多颗全树,而是表达在一颗树里面,的确不是一个一贯的东西,是两张皮。但是好处也是明显的,经济实惠,共享了句中大部分与歧义无关的依存关系。句法识别这样的结构歧义原则上不难。有“整个”这个词去drive的话,总是可以识别的。
(白: O前是表示生产、制作、呈现意义的动词,O后是双宾动词的情况,可以激活“整个”的分解语义。)
先不说排歧,因为排歧很多时候人也有难处。咱们先讨论清楚结构歧义的表达。识别完了,怎么表达?需要一点斟酌。因为只有表达合适了,后去才可以用(无论是后去的排歧,或者不排歧提供给人去互动或干预)。关键是,这个表达要好用。后去觉得不好用,那就白表达了。因为大多数其他的依存关系是可以共用的,所以结构歧义,是可以在同一颗依存树里面表达的。
在多年的实践中,发现了在依存表达中,加入 base XP 的短语结构,会带来很多很多便利。结果就人为地在本来应该没有非终结节点的纯粹的以词为基础的依存树里面,强加了这个 XP 的表达。这样一来,就出现了结构歧义的层次纠缠的问题。如果当时决定从base XP更进一步,允许XP的短语结构有嵌套,那么PP-attachement中的PP就可能成为一个扩展的NP里面的成分。这时候,PP再拿出来做谓语的状语,就同样面临层次纠缠问题。所以,这表明,这一切都是人为的。是我们为了方便做了权衡的一种表达方法。关于这种baseXP短语结构与依存关系的hybrid的好处,新来的朋友参见:《新智元笔记:基本短语是浅层和深层parsing的重要接口》。在多数时候,它的确是方便的,短语这一刀给我们带来了极大的便利,但在层次纠缠的结构歧义表达时候也给我们带来一些不便。不便之处,花点功夫可以克服。人为的东西都是可以人为克服的。
对于结构歧义在同一颗依存关系树上的表达,后续的应用,需要专门为这种表达写一个歧义检索程序,用起来就没有问题了。这个检索算法,我昨天想了一下,也不难。你从任一个节点出发,一路遍历它的子子孙孙。如果其结果是树上的所有节点都访问到了,那么这个节点就是天王老爷。如果有多个天王老爷,就说明有结构歧义。就这么简单。因为依存关系的结构原则是,有且仅有一个天王老爷。多了,就是歧义。在我们的“整个”的那句案例中,从“要”出发可以遍历。从“整个”出发,也可以遍历。其他的所有节点都不具有这个遍历终结节点的可能。白老师,这样有问题么?
前几天提到的“一张嘴”的词启动歧义识别也是如此:
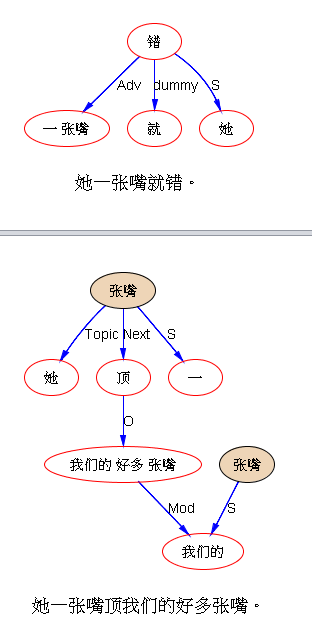
(刘:我是一只特立独行的猪,这个结果会是咋样呢?)

“结果”取了副词的用法,也说得过去,但错过了其名词的用法,虽然总体语义无大碍。

这个也有一个错,“树”应该做定语的,可是分析成“看”的宾语了,大局没错。
这些漏掉的歧义结构,从道理上都可以识别,如果歧义表达和检索按照今天说的方案那样到位的话。不过做起来还是有些繁难,以后再说吧。要点就是,对于一个已经基本对于 false parses 免疫了的细颗粒 parser 而言,与其追求不大切合实际的结构排歧,不如把下一步的重点放在歧义识别、表达和检索上。
【相关】
《新智元笔记:基本短语是浅层和深层parsing的重要接口》
https://blog.sciencenet.cn/blog-362400-955366.html
上一篇:【新智元笔记:搭配二论】
下一篇:《新智元笔记:汉语parsing的合成词痛点》