博文
【李白之58:爬楼NLU】
|||
爬楼NLU(Natural Language Understanding): 二楼句法结构三楼语义落地
李:
问各位一个 lexical feature 的转移问题及其解决途径,譬如 “所吃”。在小词 “所” 与 vt 结合成合成词以后,该词的语义等价于vt 标配宾语的语义。换句话说 “吃” 的动作性 语义本体标注 [consume] ,应该被置换成名词性标注 [food]。这个 feature 更新如何实现比较合适?到 HowNet 里面去挖出来? 如果 feature 不更新,那些细线条的指望语义 features 查询条件的规则就会失效。“所” 是一例,“的字结构” 是类似的例子。无论小词负载结构 还是小词参与合成词模式 都躲不过这个 feature 大转移的语义坎儿。当然可以为每一种主要关系(譬如 动宾)从 HowNet 抽取出一个语义词表,等到需要更新的时候,就让系统根据关系的规定来查表解决。不知道有人在 parsing 中做了这个工作没有? 估计很少,多数系统还没有细线条到这个地步。
白:
所,是N/S。的,是N+/X。所吃,是 N/S 与S/*N*,结合以后变成N/**,这是句法层面。subcat层面,它继承S的逻辑宾语坑的subcat。的,就没这么精准了。X里面谁空着就提取谁的subcat。“这本书我送的是他。”间接宾语也能提取。*N*是分母的一般形式,吃还是S/2N,所吃,是N/N,被谁所吃不知道。我所吃,N与N/N正好得出N。
李:
这里的继承有文章。“所吃” 继承的subcat 有:(1)“吃”的本体标配宾语,(2)subcat 剩余坑,也就是主语坑 /N == [animate]。这两项继承 一个是本体自己的 type 一个是坑的 type,都不是简单的事儿。因为承载本体的语词“吃” 由于小词“所”的作用 ,已经与本体概念 来了个乾坤大转移。
白:
[animate],[food]; 继承后者,即food。“这碗饭的所吃”不可以,
李:
N/**,这个句法符号里面有很多本体名堂。当然,这些本体关系信息都是现成的 ,Hownet 里面就有类似的知识表达:吃: s=[animate] o=[food]。
白:
“考”有点特殊。我们不知道“考”句法上应该是几个标配坑,但“所考”的subcat可以是人、学校、科目、某种证书。也就是说,不排除标配坑与subcat的对应有多元化的可能性。简单说逻辑宾语是不足以刻画这里面的复杂性的。不过,“所考”不可以继承分数【score】, 似乎所有事前不能有所控制的,都不能用“所”。“所梦”VS“所梦想”
李:
甲: 吃了吗
乙: 吃了
甲: 所食何物?
乙: 所食非物。
甲: 莫非秀色?
乙: 非也。 所食不过食堂耳。
甲:我的所吃更惨 非食堂 非馆子 更非秀色。所吃乃瘪、苦头、抑或 一鼻子灰。
白:
嗯,句法层能说“吃食堂”,“所吃”就可以是“食堂”。就是说,“吃”的逻辑宾语,是一堆而不是一个subcat。
李:
我要说的是 本体标配受事,还有一个上位概念,这个上位概念倚靠的是句法,表达的是逻辑谓宾的语义相谐。它不是本体那样纯粹 那样独立于具体语言,但又离不开本体的大框架。我一直把这种上位逻辑语义叫做逻辑宾语、逻辑主语,有意借用句法术语,加上前缀“逻辑”。所以逻辑宾语 可以是 【受事】、【对象】。【地点】等,以及其他种种说不清的搭配,逻辑主语 可以是 【施事】、【工具】、【地点】等。
白:
语义相谐不局限于受事,而是“可宾”的subcat。所砍,不能是工具。所去,可以是处所。所卖,可以是买主。所送,可以是对手方。
李:
这个 logical S 和 logical O 其实是很关键的概念。
白:
但是标逻辑主宾语给谁看给谁用?
语义落地,还是本体的坑好用,除非像“所X”这种含混的。
李:
主要是为了概括句型:svoc,就三个args。arg0 逻辑主语,arg1 逻辑宾语,arg2 逻辑补足语,更加杂乱一些,包括谓词结构嵌套也在内。但不管这三个 args 的内部逻辑语义细节多丰富,这三个坑从语言句型结构上定下了框架,万变不离其宗。
白:
好像不需要这一层,大面上也都可以语义落地。从“跟谁有关系”到“是什么关系”。
当“是什么关系”有多选时,就对应subcat集合,当然可以有个概率分布之类。按老乔的理论,你这是移位前的“logical form”,本质上还是句法。
李:
对 是句法。句法才是纯粹的语言学,到了语义就开始变味了。
白:
但是这标签贴了又不是最终落地用的,感觉不爽。要贴标签的话,还是只贴一次为好。句法不贴又何妨。
李:
在我这儿 语义落地靠的就是 svoc 句型,有了svoc 的框架,落地的句型 就一目了然了。 具体工作不过是给句型做细节条件的微调,然后就落地为具体场景的角色了。譬如 o 落地为 【发布的产品】,s 落地为 【发布产品的公司】:Apple launched iPhone 7 yesterday
白:
在我这儿,“可宾”包括的subcat范围,一是可以学出来的,二是仅仅跟少量词语的语义落地有关,没有大动干戈的必要。大多数落地(role assignment)的场景都不需要这个中介。
李:
把 s 标签 map 到 【发布产品的公司】这类工作,简直就是玩儿。 是典型的以不变应万变。不管产品和客户需求有多少变化 本质上 语义落地玩的就是换名的游戏。比起 parsing 这一层工作的繁难,信息抽取层面的这些工作太简明了。 虽然需要落地的谓词 都是少量的,但所有的谓词都逃不过句法的逻辑句型。 因此针对所有谓词建立句型模式 就形成了一种以不变应万变的结构准备,接下去爱怎么落地 都是一览众山小了 跑不过如来佛的手掌 。所以 这一层本身虽然不是客户的需求 而只是内部的桥梁,但我还是很推崇它作为语义落地骨架或桥梁的地位。
白:
如来佛手掌可以有多种造型
李:
那是。跳过它落地 完全可以想象。也许是偏好 总之玩一个主人三个仆从的游戏觉得很好把握,组合一下 也是非常有限的边界。不会做着做着 觉得进入迷宫 或搞不清漏掉多少。说着说着 觉得自己一方面批判乔老爷(参见【乔姆斯基批判- 李维】), 一方面可能中了他老人家句法中心论、句法自足论的流毒太深 而不自知。
白:
从“有关系”到“是受事”,中间再经历一个环节好,还是直达好?我的选择是“直达”。至于“受事”是“发布的产品”,这只是一个alias。没有什么技术含量的
李:
对呀。正因为没有含量 所以就更像是游戏。真正有技术含量都在前期的 deep parsing 里面了,那才是自然语言理解的核武器。换句话说 svoc deep parsing 已经把句法做到通用领域的极致了,以至于落地到领域几乎就是一个换名的游戏,换一个领域容易接受、客户听起来舒适的情报标签。
白:
回到前面“吃食堂”,“食堂”可直接匹配“处所”,我说它是O不是O,有何意义?
李:
关键的 argument 还是:落地是千变万化的领域 和 各种不同客户的需求,但 svoc 永存 永远不变。只要领域用的是语言数据 这就是恒定的,就如二元关系的永恒一样。
白:
这里焦点不是有没有,是可不可以不用,不用是否一定差。语言学有很强的构造性,你构造他就有。角色本地名称是第一性的,通用名称是第二性的。对机器来说本地名称可以是不要名称,只有编号:第一个语义坑、第二个语义坑……,给个本地别名,就是公司、产品,给个通用名,就是施事受事。
李:
关于直达还是通过语义中间表达的桥梁,我也问过类似的问题。我诘问的对象是费尔默理论。在信息抽取的落地框架前, 有没有必要先经过一下他老人家的 FrameNet 的框架?我的答案是否定的:多此一举 没有必要。这就基本否定了 FrameNet 的实用意义。没有必要的理由是 FrameNet 理论上缩短了语义落地的距离,实践中增加了落地的麻烦。一个 svoc 的简单通用句型 分化到成百上千的 frames 去 还没有最终到达目标地。
白:
svoc也没有达到目的地,“有填坑关系”不是更干脆么,中间的过程,无论借助subcat锁定还是借助语序,都是自动化的。
李:
svoc 可控、intuitive,而且语言学家如数家珍。其实,说了半天,从落地对策的大类上,我和白老师是一伙的。标不标 svo 只是细节的差异,虽然从我的架构看,这个差异还是蛮重要的。
白:
语言学家如果是我培养出来的,用我这一套也可以如数家珍。
李:
但如果落地从领域落地泛化到通用的应用,譬如搜索,搜索没有预先定义的事件。svo 的搜索比较容易训练给大众,这与多数人的基本语感相吻合 who did what. 这类重要应用增加了 svo 的独立价值。你要搜索产品发布事件?好 那你就搜索:“发布” 其宾语是 【产品】。至于这个宾语在语言中有多少变体的句式 那都不是大众需要关心的,deep parsing 早就 normalize 了。
白:
这只是一个动词被“实例化”的wizard
李:
如果不标svo, 搜索的时候可以这么说,搜索 “发布” 其二元关系词是 【产品】,也可以达到类似的结构搜索的效果,返回精准的产品发布事件的清单来。比纯关键词词搜索精细高明多了。可是如果客户想 搜索所有受雇的人 ,在 svo 系统中 就搜索:“雇佣” 检索出其【宾语】出来。在不标 so 的二元关系系统中,雇主和雇员就混在一起了。
白:
1、你无法排除取消发布、拒绝发布、打算发布、能够发布……这些用模态词沾染过的发布;2、发布的如果不是产品而是新闻怎么办。svoc自身无法区分哪些是产品哪些是新闻。
李:
这些都不是问题。或者说不是因为增加 svoc 而新出的问题。svoc 反而为在何处解决那个问题提供了蓝图和便利。这都是另外层面的问题,譬如节点的条件、数据的来源、李ta data 等。与评价 svo 本身的利弊没有关系。
白:
我的问题是,如果这些区分导致svoc这一层反正信息不足,反正还需要借助另一层的信息,那么直达那一层有何不妥
李:
但信息不足是有不同层面的。任何图谱(graph),是 arcs 信息不足,还是 nodes 信息不足?还是超越句内结构的discourse不足,还是 meta data 不足?不能混谈,虽然这些不同层面的信息有相互弥补的作用:戏(arcs)不够可以词(nodes)来凑。
白:
标签不足。
李:
arcs 不标标签 是一个极端。arcs 标了 soc 是多了一些句法结构的关键信息,soc 再细化为董老师的90多种逻辑语义,就又更多了信息。nodes 呢, 啥也不标 是一个极端, 标了 pos 有了一些信息分类,再标 subcats,进而做NE实体标注(包括产品),直到引进 常识本体乃至领域本体(ontologies), 信息就越来越丰富。自然也越来越难维护和掌控。
白:
反正要上三楼,就是二楼的高矮问题。
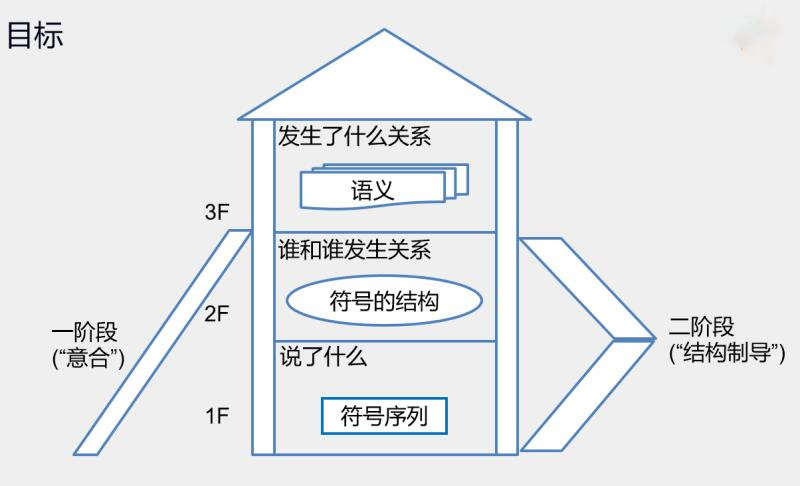
李:
对。
白:
如果为了上一个高的二楼,导致付出的代价接近上三楼,二楼就取消算了。三楼的细活儿做得越好,二楼矮点儿就越没关系。
李:
为搭建二楼 svoc 所需要的信息及其技术手段,基本全部可以继承下来为三楼服务。所以 为什么说 parsing 不仅仅是所看到的树结构,也不要指望一个 offshelf parser 就很容易语义落地为产品了。parser 要成为语义落地直通车, 需要借用 parsing 本身所带来的资源积累。结构图只是这些资源的一个最容易彰显的部分 但绝不是全部。
白:
自带插销插座,到三楼装配起来就easy多了。
李:
完全同意 同感。但 “二楼就取消算了”,不愿苟同。问题是三楼是 moving 的,业务场景变化 客户需求变化 产品角度变化 ...... 都使得三楼细活显得琐碎而不容易概括。
白:
不会
那都是贴牌问题,瓤不是moving的。
李:
二楼是清晰定义的目标。在我看来,二楼的 svoc 正是不变之瓤。
白:
我的二楼是让有关系的都勾搭上。是什么关系你们到三楼谈。但是自带了三楼才会用到的插销插座的,不妨提前锁定。到了三楼,就只剩贴牌了。但是也有需要必须在三楼才能锁定的,二楼无须代劳和强制。
李:
理论上 必须在三楼做的 只是领域知识。这些知识在二楼是避开的。
白:
另外贴牌是很外在的东东,没必要单独一层,只相当于在三楼化个妆。只需要示例就可以让领域的人干,都不用跟语言学家打照面。
李:
然,贴牌很多时候不过是 config,可以让用户或产品经理根据喜好而定,随时更换。
白:
跨领域的实体数据库,这个环节可以众包。领域知识说起来是无底洞,但是做法不同收效相差很远。根本分歧是,知识的使用是“推演”的套路还是“联想”的套路。“推演”的套路精准但笨重,只能借助人工而无法借助大数据。“联想”的套路模糊而轻盈,不过多依赖人工而寻求借助大数据讨巧。只要模糊给出的效果是应用可容忍的,“联想”的套路就会胜出。所以,哈工大做的“事理图谱”如果沿着联想的路往前走,我很看好。有理由相信,语言处理需要的知识,不是“精准”而是“轻盈”。对话场合大不了还可以追问。文本场合虽然不能受理追问,但受众有相对充分的时间调动“精准”的手段。二楼的高和矮,如果涉及到二楼的业绩,确实另当别论。如果二楼三楼的发明人都是公司的大老板,或许另样格局。这两碗水怎么端都是平的。
【相关】
https://blog.sciencenet.cn/blog-362400-1062755.html
上一篇:【李白之50:符号战壕的两条道路之辩(续)】
下一篇:【生涯花絮:1989年的老照片】