博文
数据挖掘领域必须熟悉的十大经典算法其二——CART算法
|||
国际权威学术组织IEEE International Conference on Data Mining评出了数据挖掘领域的十大经典算法。在真正进入数据挖掘算法的学习之前,这十个在该领域产生了深远影响的算法应该优先学习一下。
注:本文是对《大数据、数据挖掘与智慧运营综述》第一章的重新梳理,并加入了自己的理解。每个算法只是简单介绍,日后会详细研究。
2.CART决策树算法
CART决策树相比之下C 4.5改进之处就是增加了一个GINI系数作为决定分支变量的准则,由这个值来进行数据分隔,并建立一个二分式决策树,以决定最佳分支变量。(出自1984年 Breiman先生的论文)
GINI系数是衡量数据集合对于所有类别的不纯度,不纯度越小,证明该属性越适合作为分支属性。穷举所有属性作为分支变量所带来的不纯度,通过比较找出最佳分支属性就是这个算法的核心。
CART算法相比于C 4.5算法准确率更高,但是算法的效率只能说半斤八两。接下来我从近些年的论文中总结一下CART的改进方向。
1. 减少计算GINI系数的次数从而提高效率
例如:根据Fayyad边界判定定理、奥卡姆剃刀定律
这种方法的改进思想是在决定最佳分支变量时,结合Fayyad边界判定定理,检查相邻不同类别的边界点。Fayyad边表界判定定理明:最优分裂点总是处在不同类别的边界点处。所以只需要算出不同类边界处的GINI指数值就可以,不需要计算所有分割点的GINI指数值。因此所属类别越少,效率越高。在样本集只有两个类别的时候效率是最高。
 实验结果出自《基于改进CART决策树建立水华预警模型》
实验结果出自《基于改进CART决策树建立水华预警模型》
2. 强化弱势属性的数据特征来提高准确度
例如:关键度度量
这种方法提出了几个新系数。
类属分散度:第j个叶节点中的类别i的样本数占子树总的样本集中类别i的样本数的比重

类属决策度:第j个叶节点中的类别i的样本数占叶节点j的总的样本数的比重

关键度:其值为类属分散度和类属决策度之积

为了克服偏类样本集中多数类的数量优势,给小类属提供机会展示自己的数据特征,改进的CART算法在选择叶节点的类别标号时,选取关键度最大的类别标号
对于样本集主类类属分布不平衡的情况,利用关键度度量选取叶节点的类标号,可以提高分类准确率,使在数量上占少数但并不是稀有的类别可以在分类中得到表现。
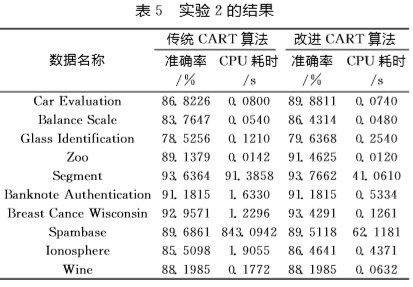
看起来经过改进,CART算法已经接近完美,其实从实验结果上看在小样本集上,CART算法的准确始终偏低。
下一章,我会介绍更适用于小样本集的SVM算法
https://blog.sciencenet.cn/blog-3401624-1157610.html
上一篇:数据挖掘领域必须熟悉的十大经典算法其一——C 4.5算法
下一篇:数据挖掘领域必须熟悉的十大经典算法其三——SVM
全部作者的其他最新博文
全部精选博文导读
相关博文
- • Does Consciousness Depend on Hallucination?(初学者版)
- • Relativity of Consciousness (初学者版)
- • Artificial Consciousness in Legal Applications (初学者版)
- • 2024-6-22回顾:Integrating the DIKWP Model into Hardware(初学者版)
- • Child-Safe Device Using the DIKWP Model(初学者版)
- • Purpose Driven 3-No problem-solving of DIKWP-TRIZ(初学者版)