博文
[转载]你需要什么样的分类算法?深度学习吗?未必
|||
分类是机器学习最主要的任务,那么最好的分类算法是哪种?一定是现在最热的深度学习吗?
针对Quora上的一个老问题:不同分类算法的优势是什么?Netflix公司工程总监Xavier Amatriain近日给出新的解答,他根据奥卡姆剃刀原理依次推荐了逻辑回归、SVM、决策树集成和深度学习,并谈了他的不同认识。他并不推荐深度学习为通用的方法,这也侧面呼应了我们之前讨论的问题:深度学习能否取代其他机器学习算法。
不同分类算法的优势是什么?例如有大量的训练数据集,上万的实例,超过10万的特征,我们选择哪种分类算法最好?Netflix公司工程总监Xavier Amatriain认为,应当根据奥卡姆剃刀原理(Occam's Razor)来选择算法,建议先考虑逻辑回归。
选择一个合理的算法可以从很多方面来考察,包括:
训练实例的数量?
特征空间的维度?
是否希望该问题线性可分?
特征是否是独立的?
是否预期特征能够线性扩展?
过度拟合是否会成为一个问题?
系统在速度/性能/内存使用等方面的要求如何?
……
这个看起来有点吓人的列表并没有直接回答问题,但我们可以按照奥卡姆剃刀原则解决这个问题:用能够满足需求的最简单的算法,如果绝对的必要,不要增加复杂性。
逻辑回归
作为一般的经验法则,我建议先考虑逻辑回归(LR,Logistic Regression)。逻辑回归是一个漂亮乖巧的分类算法,可以训练你希望的特征大致线性和问题线性可分。你可以很容易地做一些特征引擎把大部分的非线性特征转换为线性。逻辑回归对噪声也相当强劲,能避免过度拟合,甚至使用L2或L1正则化做特征选择。逻辑回归也可以用在大数据场景,因为它是相当有效的,并且可以分布使用,例如ADMM。 逻辑回归的最后一个优点是,输出可以被解释为概率。这是一个好的附加作用,例如,你可以使用它排名而不是分类。
即使在你不希望逻辑回归100%地工作,你也可以帮自己一个忙,在使用“票友”办法之前,运行一个简单的L2正则化逻辑回归作为基线。
好了,现在你已经设置逻辑回归基线,下一步你应该做的,我基本上会推荐两个可能的方向:支持向量机(SVM)或者决策树集成。如果我不知道你的具体问题,我肯定会选择后者,但我将开始描述为什么SVM可能是一个值得考虑的方法。
支持向量机
支持向量机使用一个与LR不同的损失函数(Hinge)。它们也有不同的解释(maximum-margin)。然而,在实践中,用线性核函数的SVM和逻辑回归是没有很大的不同的(如果你有兴趣,你可以观察Andrew Ng在他的Coursera机器学习课程如何从逻辑回归中驱动SVM)。用SVM代替逻辑回归的一个主要原因可能是因为你的问题线性不可分。在这种情况下,你将不得不使用有非线性内核的SVM(如RBF)。事实上,逻辑回归也可以伴随不同的内核使用,但出于实际原因你更可能选择SVM。另一个使用SVM的相关理由可能是高维空间。例如,SVM已经被报道在工作文本分类方面做得更出色。
不幸的是,SVM的主要缺点是,它们的训练低效到痛苦。所以,对于有大量训练样本的任何问题,我都不会推荐SVM。更进一步地说,我不会为大多数“工业规模”的应用程序推荐SVM。任何超出玩具/实验室的问题可能会使用其他的算法来更好地解决。
决策树集成
第三个算法家族:决策树集成(Tree Ensembles)。这基本上涵盖了两个不同的算法:随机森林(RF)和梯度提升决策树(GBDT)。它们之间的差异随后再谈,现在先把它们当做一个整体和逻辑回归比较。
决策树集成有超过LR的不同优势。一个主要优势是,它们并不指望线性特征,甚至是交互线性特性。在LR里我没有提到的是,它几乎不能处理分类(二进制)特性。而决策树集成因为仅仅是一堆决策树的结合,可以非常好地处理这个问题。另一主要优点是,因为它们构造了(使用bagging或boosting)的算法,能很好地处理高维空间以及大量的训练实例。
至于RF和GBDT之间的差别,可以简单理解为GBDT的性能通常会更好,但它们更难保证正确。更具体而言,GBDT有更多的超参数需要调整,并且也更容易出现过度拟合。RF几乎可以“开箱即用”,这是它们非常受欢迎的一个原因。
深度学习
最后但并非最不重要,没有深度学习的次要参考,这个答案将是不完整的。我绝对不会推荐这种方法作为通用的分类技术。但是,你可能会听说这些方法在某些情况下(如图像分类)表现如何。如果你已经通过了前面的步骤并且感觉你的解决方案还有优化的空间,你可能尝试使用深度学习方法。事实是,如果你使用一个开源工具(如Theano)实现,你会知道如何使这些方法在你的数据集中非常快地执行。
总结
综上所述,先用如逻辑回归一样简单的方法设定一个基准,如果你需要,再使问题变得更加复杂。这一点上,决策树集成可能正是要走的正确道路,特别是随机森林,它们很容易调整。如果你觉得还有改进的余地,尝试GBDT,或者更炫一些,选择深度学习。
你还可以看看Kaggle比赛。如果你搜索关键字“分类”,选择那些已经完成的,你能找到一些类似的东西,这样你可能会知道选择一个什么样的方法来赢得比赛。在这一点上,你可能会意识到,使用集成方法总容易把事情做好。当然集成的唯一问题,是需要保持所有独立的方法并行地工作。这可能是你的最后一步,花哨的一步。
他们各有什么优缺点:
不同分类算法的优点是什么-Ediwin Chen版
//声明:翻译:Edwin Chen的博客 –“Choosing a Machine Learning Classifier”
我们怎么知道该选择怎么样的机器学习算法来解决我们的分类问题?当然,如果你真的很注重分类的精度,你最好多选几种机器学习方法测试一下(每个算法尝试使用不同的参数来看看哪个结果最好),并且要根据交叉验证方法(Cross-Validation)选择一个最好的算法。但是如果你只是要找一个看起来不错的算法来解决你的问题,或者找一个开始下手的算法,可以尝试使用下面这些年来我总结的感觉很好用的大纲。
你的训练集多大
如果你的训练集很小,高偏离/低方差的分类器(例如,朴素贝叶斯)比低偏离/高方差的分类器(如,KNN-K近邻)有着很大的优势,因为后者容易过拟合(至于什么是过拟合,和什么是偏离/方差的问题,请开这扇门)。但是低偏离/高方差的分类器随着你的训练集的增大变得越来越有优势(他们有很小的渐近误差),因为高偏离的分类器不能提供高精度的模型。
你也可以认为是生成模型和辨别模型的区别(//TODO 这块我也不太明白,记得回头仔细看看)。
朴素贝叶斯NB的优点
超级简单,你只是在做一大群计算。如果假设的NB条件相互独立性成立,那朴素贝叶斯比其他辨别模型如逻辑回归要快,你只需要较少的训练数据即可。并且及时假设条件不成立,朴素贝叶斯分类器在实际使用中也通常有较好的效果。这是一种好的尝试,如果想让一些东西快又简单并且性能很好。它的主要缺点是不能学习不同特征之间的相互作用。(例如,它不能学习这种情况:你爱和Brad Pitt还有Tom Cruise演的电影,但是你不喜欢他俩一起演的电影。)
逻辑回归的优点
逻辑回归有很多调整模型的方式,并且你不用像朴素贝叶斯方法那样担心太多相互关联的特征。你也能得到一个很好的概率性的解释,不像决策树和SVMs那样,并且你还能很容易的加入新的数据来升级你的模型(使用一个在线梯度下降方法),这一点也与决策树和SVMs不同,它们不好做模型维护。当你需要一个概率框架(例如,通过简单的调整分类阈值,来得知不确定区间或置信区间confidence intervals)或者如果你希望将来能在训练集中加入更多的数据并很快的融入你的模型,那你就应该使用逻辑回归。
决策树的优点
容易解释和说明(对某些人来说是这样-我不确定我是否属于这个阵营)。他们很容易处理相关的特征并且他们是无参数的,所以你不用担心异常点或数据是否线性可分离的问题。(例如,决策树可以很简单的应对下面这种情况,你的第一类A在特征x的低端,第二类B在特征x的中间范围,然后A也在上端)。它的一个缺点是它们不支持在线学习,所以当新的样本来临时你必须重建你的树。另一个缺点是它们容易过拟合,但是只是当集合方法如随机森林或加速的树的等加入进来的时候才会。还有,随机森林在处理很多分类问题时效果更好(通常比SVMs好一点我觉得),它速度快、伸缩性好,并且你不用担心它像SVMs一样去设置一大堆的参数,所以在当前它很受大家欢迎。
SVMs的优点
高精度、对过拟合有较好的理论保证,并且使用一个合适的核可以得到较好的效果,甚至你的数据在特征空间里不是线性可分的。特别是在高维空间的像文本识别的问题中效果好。占用内存、难以解释甚至在运行和调试的过程中有点烦人,所以,我认为随机森林将会取代它。
不同分类算法的缺点是什么?-Waleed Kadous
//声明:翻译:https://www.quora.com/What-are-the-advantages-of-different-classification-algorithms 中Waleed Kadous对问题“What are the advantages of different classification algorithms?”的回答
基于实例的学习技术(如最近邻):
- 消耗很多内存,因为要存储所有的实例
- 对低维空间效果更好,不适合高维空间
决策树和分水岭算法:
- 可能会过拟合
- 可能会陷入局部最小值的情况,所以需要集(ensembles)来帮助降低变量。
SVM:
- 选择和寻找一个恰当的核是一个挑战
- 结果/输出很难理解
- 没有一个标准的方法来处理多类的问题。基本上就是一个二值分类器
神经网络:
- 很难选择一个合适的拓扑结构
- 训练需要很长时间和很多数据
- 输出/问题 不好理解
逻辑回归:
- 缺乏表现力(这什么鬼?分个类需要什么表现力)
- 基本上是一个二值分类器
- 不好做增量处理
朴素贝叶斯:
- 表现简单,不能做丰富的假设
- 相互独立的属性的假设限制太多
贝叶斯网络/图像模型:
- 很难确定拓扑结构的依赖关系
那么什么时候应该使用深度学习呢?
正如吴恩达在深度学习课程中说的那样:Why is Deep Learning taking off?
如果说深度学习和神经网络背后的技术思想已经出现数十年了,那么为什么直到现在才开始发挥作用呢?接下来,我们来看一下深度学习背后的主要动力是什么,方便我们更好地理解并使用深度学习来解决更多问题。
深度学习为什么这么强大?下面我们用一张图来说明。如下图所示,横坐标x表示数据量(Amount of data),纵坐标y表示机器学习模型的性能表现(Performance)。
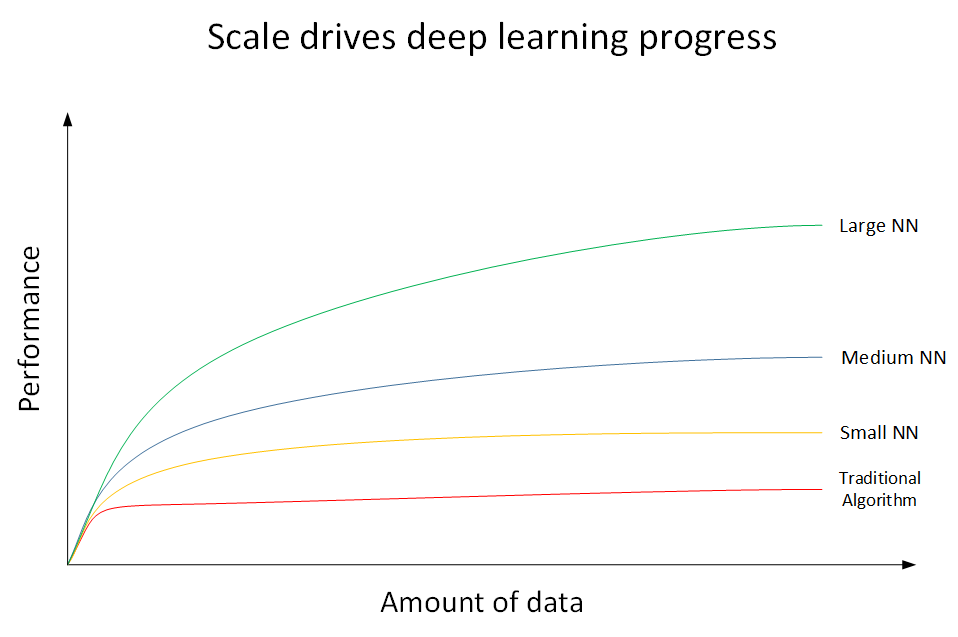
上图共有4条曲线。其中,最底下的那条红色曲线代表了传统机器学习算法的表现,例如是SVM,logistic regression,decision tree等。当数据量比较小的时候,传统学习模型的表现是比较好的。但是当数据量很大的时候,其表现很一般,性能基本趋于水平。红色曲线上面的那条黄色曲线代表了规模较小的神经网络模型(Small NN)。它在数据量较大时候的性能优于传统的机器学习算法。黄色曲线上面的蓝色曲线代表了规模中等的神经网络模型(Media NN),它在在数据量更大的时候的表现比Small NN更好。最上面的那条绿色曲线代表更大规模的神经网络(Large NN),即深度学习模型。从图中可以看到,在数据量很大的时候,它的表现仍然是最好的,而且基本上保持了较快上升的趋势。值得一提的是,近些年来,由于数字计算机的普及,人类进入了大数据时代,每时每分,互联网上的数据是海量的、庞大的。如何对大数据建立稳健准确的学习模型变得尤为重要。传统机器学习算法在数据量较大的时候,性能一般,很难再有提升。然而,深度学习模型由于网络复杂,对大数据的处理和分析非常有效。所以,近些年来,在处理海量数据和建立复杂准确的学习模型方面,深度学习有着非常不错的表现。然而,在数据量不大的时候,例如上图中左边区域,深度学习模型不一定优于传统机器学习算法,性能差异可能并不大。
所以说,现在深度学习如此强大的原因归结为三个因素:
Data
Computation
Algorithms
其中,数据量的几何级数增加,加上GPU出现、计算机运算能力的大大提升,使得深度学习能够应用得更加广泛。另外,算法上的创新和改进让深度学习的性能和速度也大大提升。举个算法改进的例子,之前神经网络神经元的激活函数是Sigmoid函数,后来改成了ReLU函数。之所以这样更改的原因是对于Sigmoid函数,在远离零点的位置,函数曲线非常平缓,其梯度趋于0,所以造成神经网络模型学习速度变得很慢。然而,ReLU函数在x大于零的区域,其梯度始终为1,尽管在x小于零的区域梯度为0,但是在实际应用中采用ReLU函数确实要比Sigmoid函数快很多。
构建一个深度学习的流程是首先产生Idea,然后将Idea转化为Code,最后进行Experiment。接着根据结果修改Idea,继续这种Idea->Code->Experiment的循环,直到最终训练得到表现不错的深度学习网络模型。如果计算速度越快,每一步骤耗时越少,那么上述循环越能高效进行。
---------------------
参考文献:
原文:https://blog.csdn.net/szuodao/article/details/51743501
原文的原文 https://www.quora.com/What-are-the-advantages-of-different-classification-algorithms
奥卡姆剃刀原则:http://baike.baidu.com/view/646319.htm
莫文的博客http://www.cnblogs.com/nsnow/p/4670785.html
红色石头Will 博客:https://blog.csdn.net/red_stone1/article/details/77799014
https://blog.sciencenet.cn/blog-3389351-1185844.html
上一篇:自然计算——道法自然
下一篇:中小型公司如何做项目管理?
全部作者的其他最新博文
- • 大数据安全研讨交流会小记
- • 中小型公司如何做项目管理?
- • 自然计算——道法自然
- • 摄影的哲学思考