博文
像样条那样入党:Local Spline Regression
||
Semi-Supervised Classification via Local Spline Regression
Xiang, S; Nie, F; Zhang, C;
Pattern Analysis and Machine Intelligence, IEEE Transactions on
Volume: PP , Issue: 99
Digital Object Identifier: 10.1109/TPAMI.2010.35
Publication Year: 2010 , Page(s): 1 - 1
IEEE Early Access
Abstract | Full Text: PDF (1012 KB)
这篇文章讲的是半监督学习,就是一堆样本中,只有个别样本知道是啥类别的,其他都不知道,要从这些个别样本中推知其他大量样本的类别。
这个就向是党的发展,为数众多的人民群众中,只有少数党员,如何发展党的组织呢?
一般的方法,满足一下俩条件:
- 跟周围的同志学习,跟周围同志搞好关系,小片社区要和谐。这是学习的途径。
- 有了途径,源头在哪里?向谁学习啥东西?当然是向党员学习党的理论了。党员要发挥带头作用,影响其他同志,不能让其他歪门邪道的影响盖过了党的影响。

作者的工作,就是在如何保持小片社区和谐上下功夫,提出了一个新的M。
在这里,作者别出心裁,跟以往从其他样本的类别推断为止样本的类别不同,作者提出:直接从样本推断类别标号!不用党员帮带,自己向党靠拢。
怎么靠拢(推断)呢?用线性函数?核函数?还是其他的?这些想法都太土了!作者大胆提出:用样条函数!!啥玩意?样条没听说过呀……回头翻翻小波的书去……
咱都知道线性和核,谁想到样条?这正是作者的新颖之处。
用啥样的样条函数g_i?要看需要最小化的目标函数是啥:

对应的样条函数啥样子?请看:对每个样本i,找出它的小社区N_i,每个小社区里的样本的样条函数是:

而要最小化的目标函数呢?
这里的M_i就是 的倒数的左上方那一小块。这样就求出来了M。
的倒数的左上方那一小块。这样就求出来了M。
再看刚开始的目标函数:

其中用y_i是党员,f_i是所有群众。把这个目标函数最小化,就能满足我们发展党组织的要求了。
于是求极值,得到如何从党员发展党组织的公式:
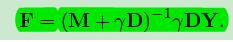
但是还有几个问题:已经发过去问了,有了答案就来告诉大家:)
启发:
原来半监督学习中,一般要分局部和全局的两部分来考虑:局部要一致,样本的类别跟周围同志不能相差太离谱;全局上说,要保持那些已标记类别的样本的影响力;
样条函数是一个很好的思路,可以考虑不要用什么线性,核的方法,而用样条;
可以将这种方法用在半监督的蛋白质分类和功能预测上吗?
最后上作者王道,自动化所的向世明老师,成绩卓著,考研的同学可别错过了!

https://blog.sciencenet.cn/blog-205121-330098.html
上一篇:猥琐男泡妞攻略,与你偶遇在很多场合:Neighborhood counting
下一篇:[回顾]哪些样本最离谱?:Class Conditional Nearest Neighbor
全部作者的精选博文
全部作者的其他最新博文
全部精选博文导读
相关博文
- • 热烈祝贺海南大学9位学者入选斯坦福大学顶尖科学家2024年Career榜
- • 祝贺访问学者吕改芳和研究生杨梦蝶等合作SCI论文在Colloids and Surfaces A发表
- • Relativity of Hallucination(初学者版)
- • Are Human Beings Living in a Hallucination?(初学者版)
- • Theory of Relativity of Hallucination by Yucong Duan(初学者版)
- • The "Emergence" of LLMs by Relativity of Consciousness(初学者版)