博文
python httpx 异步爬虫
|
小麦多组学网站geneHub页面需要加一个外链,但外链地址与基因id有关。所以要首先拿到外链地址与基因id的对应关系。因此,需要写一个爬虫来获得这个信息。
因为小麦有12万以上的基因,所以如果一个一个顺序爬取,会耗费一定的时间。正好前几天在公众号上看到使用python httpx的内容,所以就想着用httpx构造一个异步的爬虫。
相比看httpx的文档,直接看网上的实现例子似乎更快。本文参考如何使用 asyncio 限制协程的并发数。
具体的实现如下:
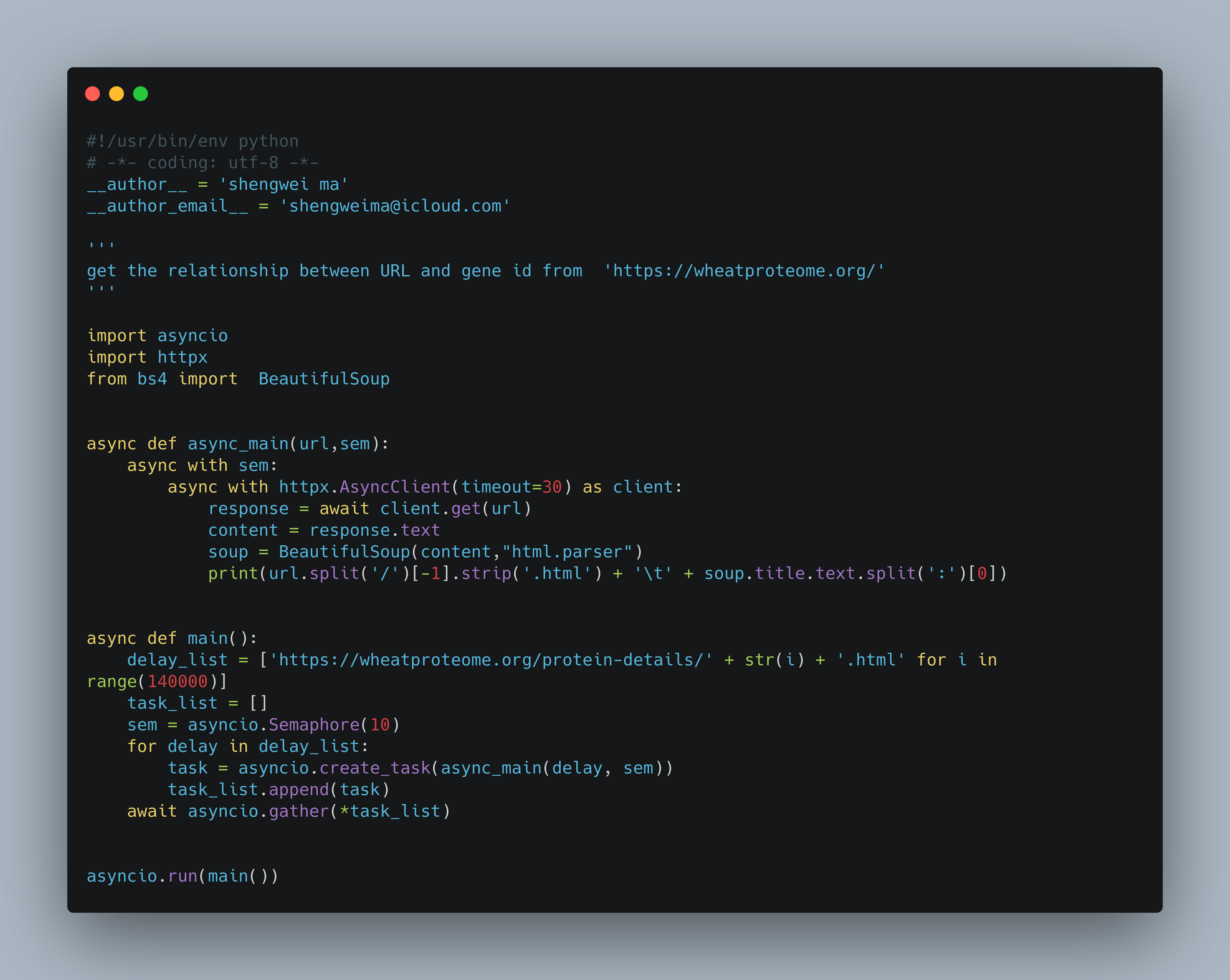
https://blog.sciencenet.cn/blog-1094241-1302802.html
上一篇:翻译|三代测序在群体水平上的研究进展
下一篇:十几万组装一个小麦基因组