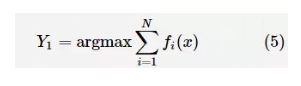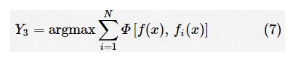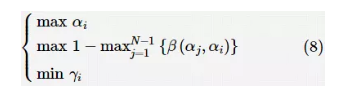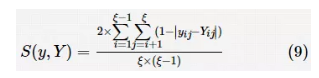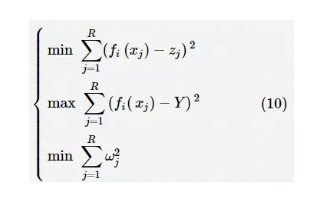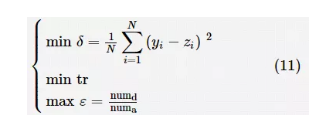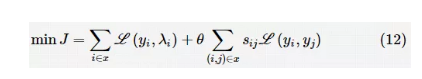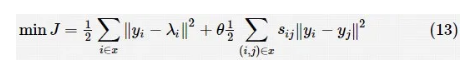HU Y, QU B Y, LIANG J, et al. A survey on evolutionary ensemble learning algorithm[J]. Chinese Journal of Intelligent Science and Technology, 2021, 3(1): 18-35.
1.引言
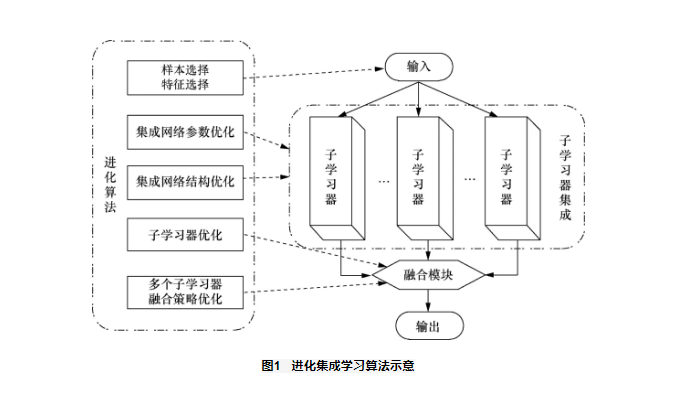
作为当前人工智能(artificial intelligence,AI)发展的主要方向之一,机器学习(machine learning, ML)越来越多地受到人们的关注。由于单个学习器的泛化能力或鲁棒性往往较差,因此一些研究将多个学习器以一定的策略组合,构成集成模型,以提高学习器解决问题的能力。许多研究结果表明,新构建的集成学习(ensemble learning,EL)系统往往可以获得比单一学习器更优越的泛化性能或鲁棒性,并且可以在保证集成学习系统性能的前提下,选择一组最佳子学习器来提高学习系统的效率,这些优势使集成学习逐渐成为机器学习领域的研究热点,美国人工智能协会(American Association Artificial Intelligence,AAAI)前主席 Thomas G Dietterich 教授还曾将集成学习、可扩展机器学习(例如对大数据集、高维数据的学习等)、强化学习、概率网络列为机器学习的四大研究方向。近些年,随着集成学习的不断发展,其已被广泛应用于数据挖掘、自然语言处理、搜索引擎、图像处理、模式识别等多个领域。 集成学习方法最早被应用于解决分类问题,之后这种整合多个子学习器、利用群体学习器的输出来补偿误差、提高整个学习系统的泛化能力或鲁棒性的学习方法,逐渐被拓展到解决回归和聚类等问题中。然而,集成学习中不同子学习器的多样性与求得解的准确性或鲁棒性之间往往存在冲突,这种冲突一般可以通过调整子学习器自身结构参数或群体学习器的融合权值等方法解决,这明显是一个优化问题。与传统优化方法相比,遗传算法(genetic algorithm,GA)、粒子群优化(particle swarm optimization,PSO)算法和差分进化(differential evolution,DE)算法等一系列进化算法(evolutionary algorithm,EA)具有适用性广、鲁棒性强、可以实现全局优化等特点。因此,一些学者将集成学习与进化算法结合,组建成进化集成学习(evolutionary ensemble learning,EEL)算法。 进化算法很早就被应用于单个学习器的优化任务中,如优化学习器的参数、内部连接权值、网络结构等。随后,一些学者逐渐将进化算法引入集成学习中以平衡学习系统的多样性和精度等性能,并以此来构建进化集成学习系统。进化集成学习算法示意如图1所示。在进化集成学习算法中,进化算法通常被用于集成学习系统中的样本选择、特征选择或对集成模型包含的参数、网络结构等进行优化,也有部分工作使用进化优化算法选择一组最佳子学习器或对多个子学习器的融合策略进行优化。
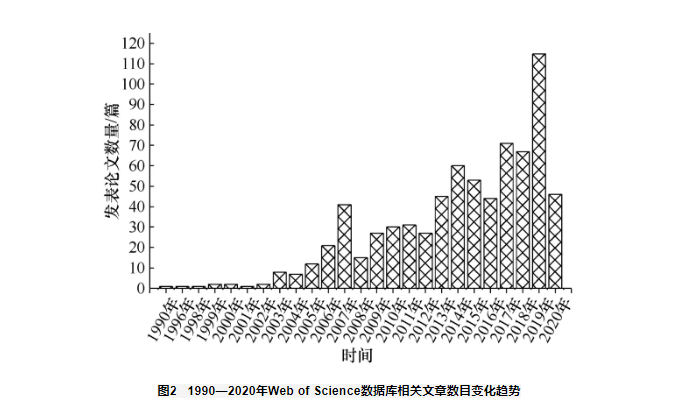
以“ensemble learning”和“evolutionary algorithm”为关键词在Web of Science数据库中搜索相关文章,数目变化趋势如图2所示,由图2可知,相关文章数量总体呈增长趋势。随着集成学习处理问题的维度、复杂度的增加(如大数据、云计算和深度网络集成等)以及进化算法的突破和发展(如多模态优化、大规模优化、超多目标优化等),进化集成学习算法具有越来越广阔的应用前景。
其中,wi(x)为权值方程。当权值的更新采用静态权值组合方法时,融合策略一般为线性组合方法;当wi为1/N时,则称之为简单平均;当权值更新采取动态权值组合方法时,集成学习系统会根据不同子学习器的性能(如均方误差、绝对误差等)分配不同的权值。 基于 Median Partition 共识函数的融合策略可以表示为:
其中,Φ为相似度度量函数,适用性较广的度量指标有样本之间的欧氏距离等,还有一些研究使用基于信息论的测量指标(如类别熵、归一化互信息等指标)作为相似度度量。 针对不同的问题,融合策略也不尽相同。分类问题输出的是类标签、秩序列或概率分布,集成分类学习的融合方法常使用多数投票或者基于权值的投票方法;回归问题的输出是连续数值,集成回归学习的融合策略常使用基于权值的投票方法;集成聚类学习常使用基于 Median Partition 的共识函数作为融合策略,此外,基于Objects Co-occurrence的共识函数也是集成聚类学习问题中常用的融合策略。 在集成学习方法中,一般的融合策略是将不同子学习器学习的结果整合输出。然而,一些研究将集成学习系统中子学习器的输出作为特征代入新的学习器中,从而组建新的学习系统,这类融合策略又被称为可训练的集成学习融合策略,其比较适用于对不同样本数据比较敏感的子学习器组合,有关这类融合策略的论述见参考文献。
目前关于集成学习的文章有很多。鉴于集成学习技术的多样性,为了帮助相关学者找到学习的方向以及开发新的集成学习技术和算法,不同的学者提出了各种各样的分类法。Rooney N 等人根据子学习器是否属于同一种类型将集成学习分为同质和异质两类;针对需要解决的问题,集成学习可以被分为集成分类学习、集成回归学习和集成聚类学习;根据在学习的过程中是否产生新的子学习器以适应数据结构或提高学习系统的整体性能,集成学习可以被分为生成性集成学习和非生成性集成学习;根据是否使用进化算法来优化集成学习系统,集成学习可以被分为进化集成学习和非进化集成学习;根据子学习器的选择和组合,集成学习可以被分为选择性集成学习与非选择性集成学习等。 本文主要对进化集成学习算法进行综述。下文根据进化算法的优化任务(如数据处理、集成模型参数组合优化、集成模型结构组合优化以及集成模型融合策略优化)总结了一些比较有代表性的进化集成学习算法。本文还在每一类别里分别总结了采用的进化算法的名称、优化问题的分类、目标函数及最终解的选择方法和优化任务信息以及采用的子学习器的名称、属性、集成方法、融合策略及解决的问题等内容。其中,有些作者并未概括所提方法和提出简称,为了更好地对不同进化集成学习算法的特点进行总结,本文对这些无简称的方法按照对应英文名称的首字母或根据算法特点进行命名。需要注意的是,本文所述的集成学习特指由多个子学习器组合集成一个整体学习系统的学习方法,一些包含多种集成策略的进化算法以及由集成了多种数据分析策略的单学习器构成的集成方法,虽然也被命名为集成算法,但并不在本文所述的集成学习的范畴内。
3.分类、回归和聚类问题中的进化集成学习算法
3.1 基于数据处理的方法
一些学者使用不同的进化算法对集成学习的样本进行数据处理。这方面的研究主要集中在样本选择、特征选择和特征构建上。样本选择主要被用于减少样本规模,最大限度地检测并消除冗余和错误的样本信息。特征选择通过一定的方法筛选并剔除数据的冗余特征,以达到降低数据特征空间维度、提高解决问题效率的目的。特征构建则对源数据进行推断,并构建有利于数据分析的新的特征。样本选择、特征选择和特征构建在数据挖掘和机器学习中有着重要的意义和广泛的应用。在集成学习系统中,选取最小规模的样本子集或有效特征子集可以最大限度地减轻学习系统的计算负担,提升学习系统的综合学习能力。 针对分类问题中的基于数据处理的进化集成学习研究,参考文献和参考文献都采用多目标优化算法来提高集成模型的预测能力,然而二者的优化任务并不相同。前者主要针对样本选择与特征选择问题,以最大化预测性能以及最小化样本规模为优化目标,且在最终解的选择方案中以曲线下面积(area under the curve,AUC)值为参考。这样的优化方案可以较好地处理不平衡数据分类问题,却忽视了多样性的分析。而后者将 SVM 的结构优化作为其优化任务之一,以提高集成模型的多样性,并且将 SVM 结构优化、参数优化与样本选择同时作为优化任务,在进化的过程中同时兼顾集成模型的特性及数据特征的属性。参考文献则通过集成不同属性的子学习器(SVM、DT)达到增强集成模型多样性的目的,且其集成方法相对于参考文献和参考文献也较为复杂。然而,在进化算法的选择上,参考文献却选择了基础的PSO算法,作者并未增加其他进化策略以增强算法的局部搜索能力和解决高维度数据等问题的能力,且以最小化分类错误率为目标函数的单目标优化算法忽视了集成模型的结构属性对特征选择问题的影响。 Liu Y等人以SVM为子分类器,通过设计一种改进的多目标蚁群优化(MOACO)算法对高维度的实体解析(ER)问题进行处理。参考文献中提出的EC-ER算法的目标函数表达式如下:
其中,αi表示第 i 个子分类器的准确率;β(αj,αi)表示第i个分类器与第j个分类器的差异度,差异度的值通过计算不同分类器预测结果的皮尔逊相关系数得到;γi表示第 i 个子分类器的特征数量。参考文献中设计的多目标优化算法旨在使集成学习系统保持更高的分类准确率和子分类器多样性的同时,获得更少的样本特征数量。在获得最优Pareto 前沿解后,作者按照优先度梯度的方法获得最终的Pareto最优解。优先顺序从高到低分别是准确率最高、差异度最大和特征数量最少,在满足前两个目标的前提下选择最少的特征数量。然而在特征选择中,相同的特征数量对应着多种不同的特征组合,这显然是一个多模态的优化问题,在实际情况中可以采用多模态优化技术获得同一最佳特征子集下的多种特征组合。这样在保证集成学习模型预测性能和多样性的前提下,赋予了决策者更多选择最佳特征子集的机会。 参考文献和参考文献是进化集成学习的应用性研究,它们分别使用进化集成学习算法解决图像分类问题和激光诱导集成光谱元素定量分析问题。在优化算法上,二者使用了简单的遗传规划(genetic programming,GP)算法或 GA,并且都以最大化预测准确性为适应度函数。不同的是,参考文献针对图像分类问题,使用 GP 算法对原有图像的数据进行特征构建,并生成有利于图像分析的特征。而参考文献的优化任务为使用GA从包含噪声的数据中进行特征选择。为了保持集成学习模型的多样性,二者都选择集成多种不同的子学习器。虽然二者建立的进化集成学习模型取得了较好的预测效果,但是GP算法和GA作为基础的进化算法,在解决复杂的实际问题时,搜索最优解的能力有限。如果加入局部搜索策略或者小生境策略,则可以进一步增强算法的局部搜索能力。 李毓等人对回归模型的响应变量与协变量进行分析,并指出变量选择旨在去除冗余协变量,找到与响应变量相关度最高的协变量,这显然是一个特征选择问题。基于此,作者提出一种结合了带权值的单路径遗传算法和Boosting回归模型的进化集成学习算法(BoostGA),并将此方法用于回归模型的变量选择问题中。在变量选择过程中,首先每个训练个体被赋予不同的权值,然后根据赤池信息量准则(akaike information criterion,AIC)设计目标函数,计算出不同的带权值样本个体对应的适应度值,再通过遗传算法获得部分拥有较大适应度值的样本,最后计算不同变量在所获得的样本中的比重,进而确定不同变量的重要性,并选择出期望的最佳变量集。然而,文献中所提模型主要采用基于误差分析的单目标遗传优化算法,虽然在变量选择过程中也通过信息熵对集成学习系统的多样性进行分析,但由于分析中带有经验参数设计,限制了该算法在实际应用中的推广。 Jiménez F 等人使用非支配径向基演化算法(ENORA)对销售预测问题的样本数据进行特征选择。文中包含两个优化目标,一个是最小化选择的特征数量,另一个是最小化随机森林的预测结果与期望值的均方根误差。最终从得到的非支配解中,选择具备最小均方误差的特征子集用于回归预测任务。然而,由式(1)可知,提高不同子学习器的差异度可以提高集成网络的多样性,在集成学习中可以在保持偏差和方差不变的情况下降低生成误差。因此在样本选择和特征选择问题中,加入多样性保持策略或以多样性为指标设计目标函数更有助于找到最佳样本子集或特征子集。 由于缺乏准确的标签,在无监督学习的过程中很难找到合适的准则用于选择样本的最佳特征子集,并且随着特征数量的增加,选择特征子集的难度不断加大,这些都限制了特征选择在无监督学习中的实际应用。在参考文献中,作者以K-means为子学习器,通过随机子空间方法构建集成聚类学习模型CEFS。其中,种群增量学习(population based incremental learning,PBIL)算法被应用于集成聚类学习的特征选择问题中。该方法对所有特征进行二进制编码,以最大化聚类算法的产生解与集成解的相似程度为目标进行优化。这种相似程度的表达式如下:
其中,ξ表示要解决问题的类别数目;y和Y分别表示子学习器和集成学习器的输出结果。由于单个聚类算法进行特征选择时难以选择合适的评价准则,常用的scatter separability和DB-index方法分别容易造成高维和低维数据偏差。Hong Y 等人通过集成多个聚类算法来提高集成聚类学习的鲁棒性,并利用集成学习模型确定特征选择评价准则,提出基于集成聚类的无偏差特征选择方法。然而所提方法并没有包含对整个集成网络的多样性分析,可以通过集成多个差异度大的子学习器或者设计多样性指标,并使用进化计算的方法,寻找同时满足相似度和多样性指标的最佳特征子集。
3.2 基于集成学习模型参数优化的方法
集成学习网络中的参数对整个模型的性能有很大影响。需要注意的是,这里的参数主要指集成学习生成阶段子学习器包含的参数或集成模型中包含的其他参数。在机器学习中,即使是相同的学习器,当设置的参数不同时,预测效果也大相径庭。因此,许多研究采用不同的进化优化方法对集成学习中学习器的参数进行优化,以增加集成学习模型参数的多样性,从而提高整个集成学习系统的多样性。常见的集成学习模型中的参数包括神经网络的权值和阈值、SVM 的正则化参数和核参数、径向基等核函数中包括的参数以及集成模型学习过程中人为设置的一些系数(如负相关系数、误差系数)等。 在基于集成学习模型参数优化的研究方法中,按照进化算法优化问题的类别,可以将分类问题中的优化方法分为单目标优化方法和多目标优化方法两类。 基于单目标优化算法的研究有参考文献和参考文献。在参考文献中,Padilha C A等人以最小二乘支持向量机(LSSVM)为子学习器构建集成分类学习系统(MLGALSSVM),并且以最小化误差为目标函数,采用GA同时进行参数优化、融合权值优化、特征选择和最佳子学习器的选择。该研究同时兼顾集成模型的结构特性与数据特征属性,在进化过程中不断地优化整个集成模型。然而,基础的GA不能很好地同时处理多个复杂的优化任务。针对不同的优化任务应设计相应的目标函数,因为单目标优化的方法无法很好地处理不同优化任务之间的关联性与冲突性。 Huang T等人提出了一种自适应小生境差分(ANDE)算法。该算法通过在DE算法中加入启发式聚类算法来构造小生境并以此来增强算法解决多模态问题的能力。ANDE算法中还使用自适应的方法对 DE 算法中的参数进行调节。作者还使用ANDE算法对神经网络的权值进行优化。基于ANDE算法在解决多模态问题中的优势,文献中建立的ANDE-NNE 可以更有效地发掘更多最优神经网络参数组合。然而文献中建立的集成模型结构相对简单,且该文献缺乏对所建集成模型的多样性分析。 基于多目标优化算法的研究有参考文献和参考文献。Chen H 等人以径向基神经(RBF)网络为子学习器设计集成学习算法,从而解决分类问题。提出的MRNCL算法通过带有适应度共享和分配的非支配排序方法设计一种多目标进化优化算法,并将该算法用于优化 RBF 网络的中心、宽度和隐含层到输出层的权值。优化算法的适应度函数的表达式如下:
其中,R 表示集成模型中训练样本的数量;fi表示第i个子学习器的输出值;xj为子学习器第j个训练样本的输入量;Y 为集成学习模型的最终输出量;zj表示第j个训练样本的期望输出值;ωj表示第j个训练样本对应的RBF网络输出层的权值。盛伟国等人利用加入小生境技术的遗传算法对集成神经网络的权值、阈值进行编码,以最小化均方误差和负相关误差的合并值为优化目标对集成分类学习算法进行优化。虽然建立的集成模型采用负相关学习技术增加模型的多样性,然而,加权合并的方法同时增加了两个目标的合并系数,其并未充分考虑两个目标的特性,无法准确得到使两个优化目标均达到相对最优的解集,其本质上仍属于单目标优化。 在使用基于集成学习模型参数优化的方法来解决回归问题的研究中,采用单目标优化算法的有参考文献和参考文献。在参考文献中, Yao X等人使用改进的进化规划(EP)算法对集成神经网络中的负相关惩罚系数进行优化,并提出NNE-TFP 算法。胡梦月等人使用加入局部搜索和莱维飞行策略的蝙蝠优化算法(BA)对 KELM算法中的回归模型参数和核参数进行优化。二者均采用进化集成回归学习方法解决实际应用问题(电信网络流量预测及风电预测)。针对所解决问题的特性,二者均设计了对应的集成学习模型,前者采用负相关学习的方法增加模型的多样性,而后者采用改进的AdaBoost.RT算法构建集成预测学习算法Ada-KELM。并且二者分别使用改进的 EP 算法与BA提高进化算法适应特定问题的能力。 Jin Y等人分别使用动态加权法(DWA)和NSGAII对MLP组成的集成学习方法的神经元连接结构和权值进行多目标优化。不同的是,DWA 是将最小化均方误差和神经网络的正则化信息的加权合并值作为一个优化目标,而NSGAII采用非支配排序的方法分别对两个目标函数进行优化。最后,文献中分别对比了两种优化算法对集成神经网络的结构和参数的优化效果。其中,Ackley函数被用于验证所提出的集成学习算法 NNRE-MOEA 在解决回归问题中的性能。文献中虽然对集成网络的复杂度进行了分析,却未以最大化多样性为优化目标进行参数寻优。同样对集成分类学习模型中的神经网络权值进行多目标优化的还有 DIVACE等方法。 Bui L T等人分别采用NSGAII和基于非支配排序的DE算法对以BP算法为子学习器的集成回归学习系统进行多目标优化。其中,优化算法的编码对象是神经网络权值,优化目标是最小化均方误差和最大化集成系统多样性。经过多目标寻优后得到非支配解集,作者分别通过选择全部解集和只选择最优解集两种方式将对应的BP算法代入Adaboost模型中,组建集成学习模型 Adaboost-FET,并将其用于解决货币汇率问题。虽然建立的Adaboost-FET模型在测试问题中取得了较好的预测效果,然而BP算法需要经过不断迭代来训练网络参数,以达到较好的预测效果,这个过程会耗费大量时间,在集成模型中这个弊端更加明显。在子学习器的选择中,可考虑 ELM 等单层神经网络,在不影响预测效果的前提下提高集成学习算法的效率。 聚类中心个数直接影响整个聚类学习器的预测性能。因此,通过进化算法来确定集成聚类学习模型中的聚类中心个数具有十分重要的意义。 参考文献中使用模糊C均值聚类(FCM)算法作为子学习器,将链、超图结构和组织P系统(tissue-like P system)组合成集成聚类学习模型,融合策略采用概率轨迹积累(PTA)和基于概率轨迹的图划分(PTGP)两种共识函数。为解决聚类中心个数设置问题,作者采用 NSGAII、非支配邻域免疫算法(non-dominated neighbor immune algorithm,NNIA)和 Pareto 包络选择算法(Pareto envelope-based selection algorithm,PESA)3种多目标优化方法,分别对集成聚类学习模型中的子系统进行优化。虽然所建模型在UCI测试集中取得了较好的效果,然而采用的3种优化算法均为基础优化算法,随着数据维度的增加,算法的搜索能力会逐渐退化或者限于局部最优。并且随着优化目标的增加,算法找到最优Pareto前沿解的能力会逐渐减弱。在解决复杂的实际问题时,应该根据要解决的问题加入局部搜索策略,以提高算法的局部搜索能力,或者加入决策变量的分析策略,以提高算法解决大规模优化问题的能力。 在参考文献中,Handl J等人将多目标优化算法—— PESA-II与K-means和最小生成树(MST)结合,提出一种名为MOCK的进化集成聚类算法。文献中并没有对聚类中心个数或样本对应的标签进行编码,而是采用一种基于轨迹邻接的编码方案,直接对样本形成的图形结构进行编码,最终在进化的过程中确定集成模型中包含的重要参数——聚类中心个数。Mohammadi M等人提出一种使用GA在进化过程中确定关联矩阵和集成聚类结果的算法。通过使用进化算法,提出的 GACEII可以在进化的过程中确定聚类算法中的重要参数,即聚类中心个数。上述方法均使用进化算法间接地实现对聚类中心的寻优,同时对聚类中心个数与样本标签等进行编码寻优的方法也值得更深入的研究。集成聚类学习模型还包括聚类学习器本身包含的一些参数(如基于密度的聚类算法中关于密度的阈值等),更广泛的研究还包括采用进化算法对这些相关参数进行优化,以提高集成模型的整体性能。
3.3 基于集成学习模型结构优化的方法
结构的多样化是集成学习模型多样性的重要体现。对集成学习模型的网络结构进行优化包括对子学习器的结构优化以及对整个集成网络子学习器的组合优化。前者主要指利用进化算法优化神经网络或决策树等子学习器的节点分布及其对应的激活函数和学习规则等。后者可以被理解为采用进化算法在进化过程中选择最优的子学习器组合。 在基于集成学习模型结构优化的进化集成学习算法中,一些研究以神经网络为子学习器组建集成学习模型,通过进化算法对神经网络的结构(节点分布)进行优化,并且这些研究均通过改善子学习器的结构来提高整个集成学习模型的多样性。参考文献和参考文献均以最小化误差和集成网络的复杂度(网络节点连接次数)为目标进行优化。参考文献将两个目标加权合并为一个目标函数,然后采用单目标优化算法进行优化。这样的方法增加了加权系数,但不能像多目标优化算法那样得到多个可行解。参考文献虽然采用了多目标优化的方法,但是其针对不同的误差进行优化目标的设计,优化过程中并没有考虑集成学习模型的多样性或复杂度等性能指标。 Nag K等人设计了一种基于决策树的集成分类器,并将多分类问题转化为二分类问题进行求解。作者以最小化假正(false positive,FP)和假负(false negative,FN)的数量,以及最小化决策树的树叶节点为优化目标对决策树结构进行优化。由于文献中以最小化FP和FN的数量为优化目标,设计的进化集成学习算法 ASMiGP 更加适合不平衡数据的分类问题,这点在实验分析阶段得到了验证。与其他集成方法不同,所提方法并未将集成学习系统的多样性作为一个优化指标参与优化过程,而是通过保障被划分为二分类问题的数据特征的差异性来保证整个集成系统的多样性。实验结果显示,该方法可以增强学习系统的多样性,然而,该方法在处理拥有较多样本的问题时会造成巨大的计算消耗。 Ojha V K等人使用多目标遗传规划(MOGP)算法对子学习器的节点分布和激活函数类别进行优化。文献中选择神经网络和决策树两种不同的学习器组建一种名为异质柔性神经树(HFNT)的集成学习系统。Ojha V K等人还使用HFNT解决分类、回归和时间序列预测问题。在HFNT中,多层反馈神经网络的节点可以设定不同的激活函数,并且不同的节点还可以跨层连接。Ojha V K等人以最小化学习器学习结果的错误率、最小化树的规模和最大化多样性指标为优化目标,对HFNT的网络节点和不同节点对应的激活函数种类进行寻优。3 个优化目标的数学表达式如下:
其中,yi表示第i个子学习器的实际输出值;zi表示第i 个子学习器的期望输出值;δ 表示集成学习系统输出值与期望值的均方误差;tr表示神经树中除根节点之外的节点个数;ε表示HFNT的多样性指标,其值等于互异的树的个数(numd)与所有树的个数(numa)的比值。其中,如果两个树的节点数目不同、节点对应的激活函数不同或者输入的样本特征不同,则称两个树互异。确定了HFNT的结构后,文献中还采用DE算法对集成网络中的权值进行微调。在最后的组合阶段,融合策略采用多数投票的方法。文献中所提方法在针对测试函数的训练中取得了良好的效果,然而并没有在实际的问题中进行验证。 采用进化算法选择最佳子学习器组合的方法有参考文献和参考文献。Min S H以最大化集成学习模型分类准确度为目标函数,使用 GA对集成学习算法中的子学习器进行二进制编码,以寻找最佳子学习器组合。文中将K近邻(KNN)、逻辑回归(LR)、DT和SVM 4种方法作为子学习器,通过随机子空间的方法构建异质集成分类学习模型GAHRS,并将之用于处理公司破产预测问题。其中,子学习器的输出采用多数投票法进行整合,以获得集成学习系统的输出。虽然文献中使用互异的子学习器组建集成学习模型,以增加网络的多样性,但是该方法过于依赖经验分析,而针对不同的问题,需要选取不同的子学习器,并且不同的集成模型对子学习器的要求也不同,如预测结果随机性较强的子学习器更适合以Bagging模型组建集成学习系统。 Liu W等人以多个基于信念规则(BRB)的分类器构建集成分类学习模型。作者分别采用 DE算法和PAES算法来优化BRB的参数并进行子学习器的组合优化。虽然使用的进化算法在一定程度上提高了集成模型的预测能力,然而作者并未根据具体的问题对优化算法进行改进,以提高搜索能力。并且作者并未对构建的集成学习模型进行整体分析,而是分别使用两种优化算法对子学习器的内部参数以及子学习器组合进行优化。 在参考文献中,Faceli K等人根据多目标优化算法可以同时利用多个聚类评价准则,以获得多个最优解,并且集成多个聚类算法使获得的解具有更好的鲁棒性,将多目标优化算法与集成学习结合,提出一种多目标聚类集成(MOCLE)算法。在所提算法中,Faceli K等人分别根据NSGAII和强度 Pareto 进化算法(SPEA)设计了两种适用于集成聚类的多目标进化算法。其中,Faceli K等人将所有子学习器(如K-means、单连接算法(SL)、平均连接算法(AL)和共享近邻(SNN)算法)的结构参数以及样本对应的标签定义为初始种群,以最小化总体偏差(所有样本与其对应的聚类中心的距离的总和)和连接性指标(反映相邻样本被放置到同一个聚类中心的频率)为优化目标。与其他集成聚类不同的是,MOCLE 算法并不是将所有子学习器的学习结果整合到一起,然后通过共识函数进行输出,而是设置了具有共识函数作用的交叉算子。因此,MOCLE 算法可以在进化的过程中直接输出集成结果。然而,MOCLE 算法在设置初始种群时需要对子学习器的一些设置(如聚类数目等)进行经验分析,以提高集成模型的多样性。所提优化算法旨在从初始设定的集成模型中寻找最佳集成效果,而不是对所有可能存在的子学习器组合进行寻优,因此,Faceli K等人删除了变异的过程。这种操作虽然减轻了计算负担,却在一定程度上使算法失去了全局搜索的能力。Liu R 等人在MOCLE 算法的基础上增加了基于不同聚类结果相似度的目标函数,以增强原有算法的预测能力。 Mahmood A 等人针对网络视频分类问题提出了基于GA的集成聚类学习算法,以提高预测结果的鲁棒性、稳定性和准确性。提出的SS-EE算法以子学习器(图聚类(GC)算法、仿射传播聚类(AP)算法和谱聚类(SC)算法)的种类和聚类集成方法(基于簇的相似度划分(CSPA)、元的种类聚类算法(MCLA)和超图划分算法(HGPA))的种类等信息为编码对象,使用进化算法完成对整个集成学习模型结构的优化。Mahmood A等人根据视频信息设计了名为预配对百分比(pre-paired percentage, PPP)的指标,并以最大化PPP指标为优化目标指导GA的进化过程。PPP指标的计算主要依据网络视频信息的模型分析,因此限制了所提集成聚类学习模型的推广应用。
常见的集成学习方法通过集成多个相同属性的学习器(如分类、回归或聚类学习器)来完成有监督或无监督学习。然而,有些研究却将分类学习器或回归学习器与聚类学习器结合,共同组建混合集成学习系统,并通过进化算法改善所建系统的学习能力。 Minku F L等人提出一种基于聚类和协同进化算法的集成神经网络模型CONE。CONE首先采用进化聚类(ECM)算法将数据划分到不同的子空间中,然后使用基于模糊逻辑的神经网络(EFuNN)对不同子空间中的数据进行分类。由于被划分到不同子空间中的数据的结构不同,导致对应的EFuNN网络结构也互不相同,Minku F L等人分别采用单目标协同进化遗传算法(CEGA)、多目标协同进化遗传算法(MO-CEGA)和多目标协同进化策略(MO-CES)对不同EFuNN的结构或参数进行优化,从而在保证分类精度的同时,优化网络规模、提高计算效率。通过聚类算法对问题进行知识提取的方法增加了集成算法的可解释性,使CONE更适用于解决在线预测问题。 Rahman A等人提出一种面向聚类的集成分类学习算法NULCOEC。该算法使用一种非均匀分层方法对数据进行划分,每一层包含不同数量的聚类学习器(层次聚类算法)。Rahman A 等人分别使用单目标GA和多目标GA,以最大化准确率和多样性为目标对整个集成学习模型的分层层数和每层聚类学习器的数目进行优化。针对每一层的聚类学习器,文献中还使用分类学习器(如SVM)对聚类结果进行决策。最终Rahman A等人使用多数投票的方法对所有层的学习结果进行融合。 在参考文献中,Coletta L F等人将NB和DT 两种分类学习算法与经典的聚类学习算法K-means组合成一个集成学习系统C3E-SL。所提方法首先通过集成分类学习模型对训练数据进行学习,然后得到测试数据所属标签的概率分布,再通过集成聚类学习模型对上一步生成的概率分布结果进行重新提炼,进而得到最终结果。整个集成模型的学习过程可以概括为一个优化问题:
其中,yi表示聚类学习算法为每个样本数据赋予的标签概率;λi表示分类学习算法对第 i 个样本数据学习后得到的标签概率分布;表示损失函数;sij表示聚类算法共识函数联合矩阵中包含的元素;θ 表示一个正实数系数。该式子的两个组成部分分别表示集成分类学习部分和集成聚类学习部分的损失函数值。当损失函数选择平方损失时,上述优化问题可以表示为:
在所提集成学习方法中,整个集成学习系统学习的过程即式(13)逐渐收敛的过程。其中,由式(13)可知,系数θ在整个集成学习系统中起到连接集成分类学习模型和集成聚类学习模型的作用。基于系数θ对集成学习模型的影响,Coletta L F等人采用DE算法,以最小化整个集成系统的分类误差为优化目标,对θ和集成学习系统收敛过程中的迭代次数进行了优化。 参考文献和参考文献均使用单目标优化算法对混合集成学习模型进行优化。不同的是,前者的优化任务为获得聚类中心个数和子学习器的最优组合,而后者对集成模型中极限学习机(ELM)的权值参数进行优化。二者都使用聚类算法和分类算法构成混合集成学习模型,然而聚类算法在二者中的作用却不相同。前者使用基于PSO算法的进化聚类方法对数据进行聚类,并生成随机子空间,而后者则以多维缩放K均值聚类(MSK)算法为融合策略,对 ELM 集成网络的输出结果进行聚类。两种混合集成学习模型最终被分别用于解决分类和回归预测问题。虽然参考文献和参考文献均将聚类方法与分类或回归学习器结合来提高混合集成模型的学习效果,然而,在优化算法的选择上二者均采用简单的进化算法,参考文献虽然将 PSO 算法用于优化 PIO 算法,以提高算法的全局搜索能力,但这种方法增加了算法的复杂度,并且改进后的PIO算法的优化效果也没有得到验证。 在参考文献中,Onan A等人使用集成聚类算法对整个集成模型中的集成分类学习器进行组合优化。提出的EPACMOEA首先使用多种分类学习器(5种贝叶斯分类器、14种基于核函数的分类器、10种不同的KNN分类器、3种基于规则的分类器和8种基于DT的分类器)组建集成分类学习模型,并对文本情感分析数据进行分类,然后使用自组织映射(SOM)、最大期望(EM)算法和K-means++对建立的集成分类模型进行聚类分析,同时结合ENORA对建立的集成分类模型进行子学习器组合结构优化,最终通过Q统计指标选择多样性更好的分类器。 有监督学习器与无监督学习器结合的方法主要分为以下3类:一是使用聚类学习器进行知识提取,将数据划分到不同的子空间,然后结合分类或回归算法进行有监督学习,如参考文献和参考文献;二是使用聚类算法对有监督学习器的输出结果进行聚类分析,以提高整个学习系统的预测性能或计算效率,如参考文献和参考文献;三是使用有监督学习器对聚类的结果进行决策分析,通过有监督学习器来提高聚类算法的学习能力,如参考文献和参考文献。在混合进化集成学习中,进化算法分别被应用于集成模型结构优化、参数优化和子学习器组合优化等。然而,采用进化算法对集成模型的融合权值进行优化、多目标优化方法最终解的选择方法以及设计包括集成模型稀疏度、复杂度在内的优化目标等内容仍值得进行更广泛和深入的研究。并且这类混合进化集成学习方法大多被应用到解决分类问题中,后续的研究可以考虑使用该方法解决回归问题等。
4.结束语
本文将进化集成学习算法作为一个单独的问题进行详细的综述,并且对与分类、回归和聚类3种与机器学习方法相关的进化集成学习算法进行全面的综述。文中对进化集成学习的理论依据与组成结构以及分类情况进行了概述,然后分别根据进化算法在集成学习模型中的优化任务(即样本选择、特征选择、集成模型参数组合优化、集成模型结构优化以及集成模型融合策略优化)总结了一些相关的代表性论文,并分析了这几类方法的主要特点。此外,文中还对一些将无监督学习和有监督学习结合的混合进化集成学习算法进行了综述与分析。进化集成学习算法将集成学习与进化算法结合,不仅为提高集成学习的综合性能提供了新技术,同时也极大地丰富了集成学习的理论。未来关于进化集成学习算法的研究方向主要包括如下几个方面。 (1)进化集成学习算法中目标函数的设计选择合适的目标函数对提高进化集成学习算法的性能至关重要。较常用的目标函数包括预测结果的准确度、集成模型的多样性、网络结构的复杂性、网络的负相关度和样本的相似度等。如果要通过改变集成模型中子学习器的组合方式来实现对上述指标的优化,在实际应用中往往难以实现,费时费力且效果差强人意。并且上述指标的设计往往是针对特定应用问题的,在设计的过程中并未有统一的标准,因此,进化集成学习中目标函数的设计是一个值得深入研究的问题。 (2)进化集成学习算法中进化算法最终解的选择单目标优化算法选择最优解作为输出,然而其无法协调多个优化目标之间的复杂关系;多目标优化算法通过非支配排序的方法获得Pareto前沿解,其输出是一组解集,常用的最终解选择方法有选择全部解、按优先梯度选择解、通过Pareto曲线拐点或曼哈顿距离分析法选择解等。然而,分析现有的研究结果发现,最终解的选择方法与其需要解决的问题有很强的关联性。因此,在实际应用中,如何根据要解决的问题确定合适的最终解选择方案仍需要进行更广泛的研究。 (3)进化集成学习算法中进化算法的选择在进化集成学习中,需要根据集成模型的特点选择合适的进化算法。如在集成 ANN 的权值、阈值优化问题中,优化对象的维度可能达到几千维,应该选择大规模优化算法。而在集成学习的样本选择(或特征选择)问题中,相同的样本数量(或特征数量)对应的是一组样本子集(或特征子集),要解决该问题应选择多模态优化算法。但是,当前的进化集成学习算法往往缺乏对相关问题的详细分析。在面对大数据、云计算等复杂的机器学习任务时,相应的进化集成学习算法也需要根据实际问题重新设计针对性更强的进化算法。 (4)进化集成学习方法应用范围的拓展通过文献综述发现,当前的进化集成学习算法主要被用于解决分类问题,而面向回归和聚类问题的进化集成学习技术也值得更广泛的研究。此外,对进化集成方法进行改进以适用分布式计算、设计适用于在线学习的进化集成学习算法、将无监督学习与有监督学习方法结合以增强集成模型的学习性能等问题都是值得广泛和深入研究的课题。