博文
共现分析的7个瓶颈(5)
||
5.共现聚类分析中相似性计算的问题
即在聚类分析操作过程中具体的参数选择问题。如图1中的a,b所示,以普遍使用的SPSS软件为例,探讨数据类型、相似系数和类间距离计算方法等参数的选择。
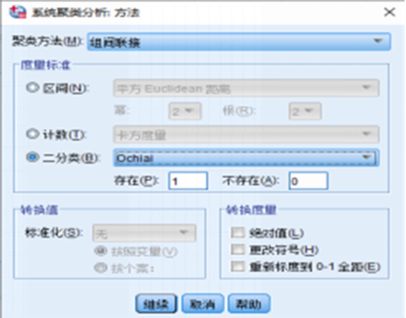

(1) 输入什么类型的数据?
在SPSS系统聚类模块中,重要的是在“方法”选项中设置“度量标准”,告诉软件你输入的数据是哪一种类型,具体选项为“区间”、 “计数”和“二分类”三种。对于我们推荐的词篇矩阵或者被引-引用矩阵被引-引用,由于矩阵里的数字只有0和1表示某一个关键词或者被引文献是否在对应列中的文献中出现,因此应当选择“二分类”。
(2) 计算什么相似系数?
相似性度量是聚类分析的基础,因此相似系数的选择决定了聚类结果的准确性。首先应当了解各种相似系数的计算方法或原理。即不同的相似系数适用于不同类型的数值及其分布。如欧氏平方距离是一种相异性度量,数值越大两个关键词之间的相异程度越大。Pearson相关系数要求矩阵数据服从正态分布,且至少在逻辑范畴内必须是等间距的。Cosine系数与ochiai系数原理相同,区别在于Cosine系数一般用于区间矩阵,ochiai 系数一般应用于二分类矩阵,但实际应用中,国内学者常把二者混淆,出现如“计算共现矩阵的ochiai系数矩阵”之类的方法。我们推荐使用ochiai系数,因为该系数适用于我们输入的二分类的词篇矩阵,同时其计算公式中为:AB两文章总被引次数/squr((A的总被引次数)*(B的总被引次数)),类似余弦和互信息的原理,消除了关键词出现总次数或被引文献总被引次数对相似性度量的影响。
(3) 如何计算类间距离?
在系统聚类分析的凝聚聚类的过程中,随着新类别的不断形成,涉及到如何计算分类对象与新生成类别之间的距离的问题。简单地讲,A和B两个词聚成一个类之后,需要计算其他词与这个新类别(含A、B)的关系,比如关键词C与新生成的类别之间距离的计算可以采取C与A和B两个距离中最大的那个数(最远邻元素),也可以反之选择最小的(最近邻元素),当然也可以选择两个距离的平均值(组间或者组内联接)。
可以将整个聚类空间想象为一块橡皮,如图2中a,b所示,如果选择最短距离法(SPSS中文翻译的最近邻元素),则各个聚类对象(高频关键词或高被引文献)则如卷心菜一般一层层地向中心聚集。如果选择最大距离法,则聚类对象会向外分散开去。据此,我们在书目信息共现聚类分析中的经验体会是:如果所分析的主题领域比较集中或关键词之间联系紧密,则适宜采用最大距离法,使得关键词之间尽量远一些,聚类树得到清晰的轮廓;反之,如果所分析领域中关键词或者被引文献之间比较松散,则采用最小距离方法,让各个关键词或者被引文献尽量的集中到一起。
综上所述,无论是高频关键词的共现聚类分析,还是高被引论文的同被引聚类分析,我们推荐的参数选择是:输入词篇矩阵或者被引文献-来源文献矩阵,选择ochiai系数,数据类型选择“二分类”,类间聚类视具体情况而定,一般用平均距离(组间或者组内联接)。
https://blog.sciencenet.cn/blog-82196-1325832.html
上一篇:共现分析的7个瓶颈(4)
下一篇:共现分析的7个瓶颈(6)