博文
反馈即你所需:从ChatGPT到自动驾驶
||


ChatGPT
ChatGPT的诞生。2022年11月,微软和OpenAI联合发布了一款名为ChatGPT的人工智能聊天机器人程序 (GPT:Generative Pre-trained Transformer)。在短短两个月内,全球用户数量超过1亿,成为历史上增长最快的消费者应用程序。
ChatGPT几乎可以像百科全书一样回答任何问题,具有惊人的流畅度、人类般的表达,甚至是复杂度。更令人惊叹的是,它可以像初级工程师一样编写代码,甚至可以通过医学和法律许可考试,展示了机器智能的点点涌现。
背后的技术。首先,ChatGPT选择了一个理想的应用场景:对话,任何人都可以随时随地进行。ChatGPT使人们能够通过自然的问答互动、文本内容的创造性组成和强大的知识库,轻松体验人工智能的魅力,从而引发人们对人工智能的巨大兴趣。
事实上,相关技术已经证明了突破性和可行性。“G”代表生成式模型,指能够随机生成观测数据的模型。作为典型代表,自回归语言模型 (ALMs) 被广泛应用,以自动生成文本。“P”代表预训练,这是从独立于特定任务的大量标记数据中获得训练模型的过程。自2018年谷歌发布 “Bidirectional Encoder Representations from Transformers” (BERT) 以来,“预训练+微调”在自然语言处理 (NLP) 领域逐渐受到关注。字母“T”代表Transformer,这是一种深度学习架构,可以结合注意力机制,在处理长文本时表现异常出色。
更重要地,ChatGPT采用了人类反馈强化学习 (RLHF) 技术。根据提示输入,人类专家对预训练语言模型生成的答案进行评价和标记,然后使用这些标签来创建比较数据库,用于训练强化学习 (RL) 的奖励模型并优化语言模型。通过这种方式,实现语言模型输出与人类表达、逻辑和常识的对齐。这些技术正是ChatGPT性能从量变到质变、涌现智能的原因。
反馈: 一种有效机制
反馈,是应对开放、复杂、多变、不确定环境的最有效机制。
早在中国秦代,都江堰的设计就体现了反馈的思想:通过“鱼嘴堤” 将岷江分为深而窄的内溪和浅而宽的外溪,以此构建水量反馈,控制流入成都平原的水,实现在雨季大部分水流入外溪,保护成都平原免遭洪水侵袭,而在旱季大部分水流入内溪,灌溉成都平原。
1948年,诺伯特·维纳出版了著名的 “Cybernetics: Or Control and Communication in the Animal and the Machine (控制论:或动物与机器中的控制与通信)”。他研究了人工和生命系统中的信息流,阐明了这些系统的通用控制机理,将反馈归纳为基本原理:反馈指将系统的输出返回到输入端与参考/基准进行比较,并以某种方式改变输入进而影响系统性能的过程。
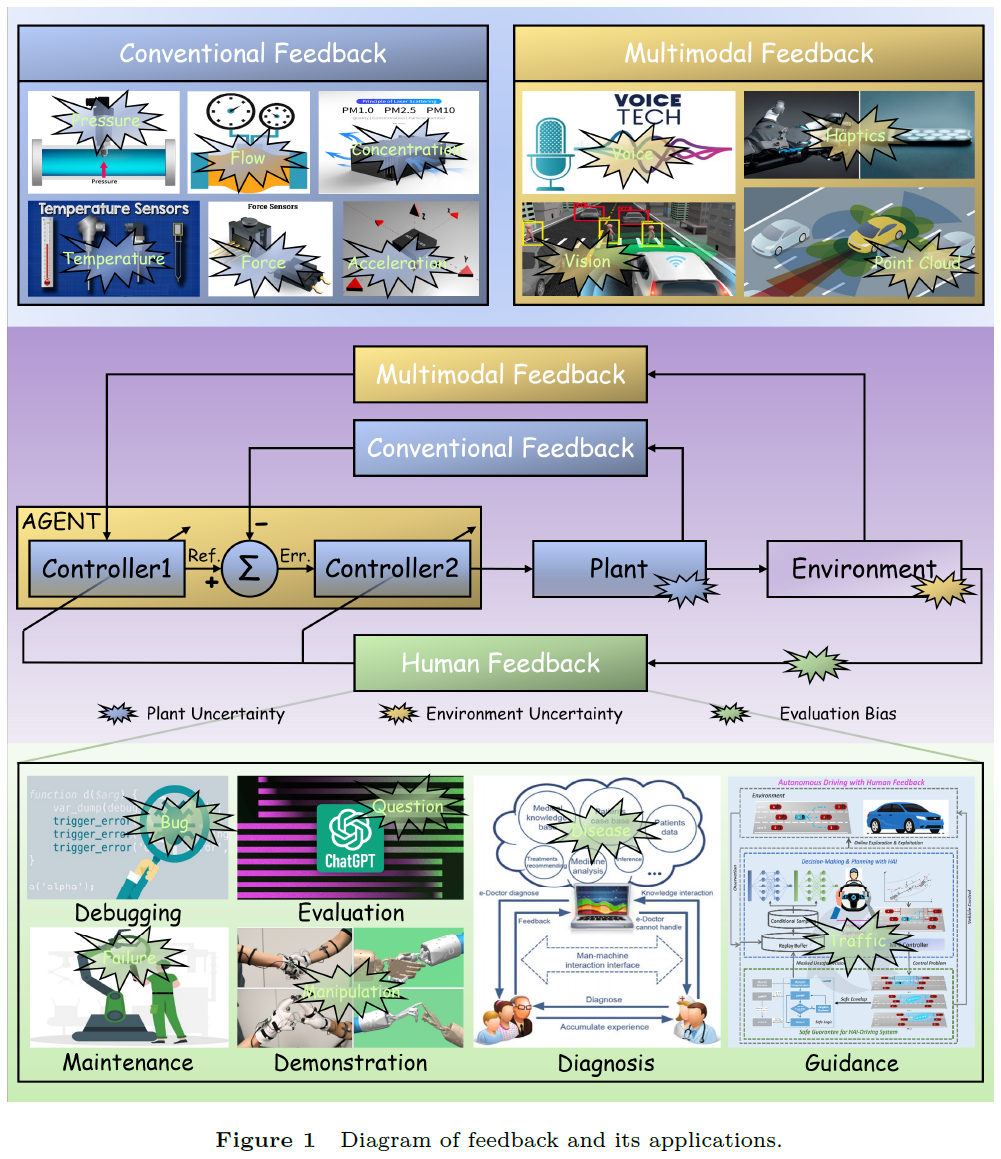
如图1所示,工业系统测量温度、压力、流量、力、加速度等物理量作为反馈 (图中的传统反馈),实现对人类操作的模仿和替代。正是反馈对系统不确定性/干扰的有效应对,成就了工业控制的巨大成功。
如今,智能系统采用多模态感知作为反馈,以期实现模仿、增强和取代人类的感知、认知、沟通等其他能力。例如,自动驾驶 (AD) 系统通常以分层或端到端的方式引入多模态反馈,如相机、雷达、激光雷达等信号,提高系统输出性能。
在分层的“感知-规划-控制”架构中,规划模块 (图1控制器1) 接收来自摄像机、雷达、激光雷达等的多模态反馈信息,完成驾驶行为的决策和规划并输出期望轨迹给跟踪模块 (控制器2)。跟踪模块则进一步基于车辆速度、加速度和位置等反馈,输出控制信号到车辆执行器。
而在端到端架构中,与大多数视觉驱动模型一样,自动驾驶“智能体”接受图像等多模态信号,直接输出车辆控制指令。值得指出的是,在交通系统中,智能体可以是行人、有人/无人驾驶车辆,以及其他交通参与者。此外,文本、语音、触觉等其他信号也被广泛用于多模态反馈。因此,反馈已从单模态信号扩展到多模态信号,以应对环境不确定性对系统的影响。
人类反馈,进一步拓展了反馈的外延
随着系统和交互环境变得越来越复杂,仅通过多模态反馈已难以保证控制器/智能体的良好性能。作为地球上最聪明的物种,人类能够出色应对复杂和不确定环境。因此,如图1下半部分所示,将人引入反馈回路,通过人类的校准、操作、调试、监督、知识、评估、认知等增强系统智能,以更好地应对复杂系统和环境的不确定性,以及人类偏差。
事实上,人类反馈的思想早已渗透到自动化、计算机和人工智能等众多领域。例如,工业控制系统需要每年检查和校准,以解决漂移和老化等问题;应用最为广泛的PID控制器就是由工程师评估系统输出进行参数调整;计算机程序需要大量的人工调试。而汽车工程师则使用主观评价方法对车辆功能、性能和可靠性等进行分析,以调整机械和电控系统参数。此外,基于人工智能的电子医生系统利用医生诊断结果进行反馈学习,以提高诊断准确性和效率;图像处理利用人类反馈对深度神经网络模型进行参数微调,以提高预测精度。
回到ChatGPT,虽然它的成功表面上看是由于参数暴涨了、模型更大了。但ChatGPT 的前身,GPT-3的性能仍然不稳定。无论参数如何增加,无论计算如何暴力,也难以解决训练的长尾效应。对此,ChatGPT 使用了RLHF 技术,创新地融入了人类反馈,极大提升了用户对应答的满意度和接受度。可以说,在前期GPT技术基础上,人类反馈机制为ChatGPT提供了应对对话场景开放性和不确定性的智能提升范式,成为其成功的关键。
两种人类反馈注入系统的方式:在线和离线。一方面,ChatGPT通过离线收集可靠的人类评价来训练奖励模型,属于离线人类反馈。另一方面,类似于工业控制系统中的传统反馈,人类反馈也可以在线引入,以实现控制器或智能体的在线调整与训练。
在这两种情况下,如图1所示,对人类反馈数据的质量进行评估是首要任务。例如,机器人系统可以从与人类可靠的互动数据中学习,以提高其工作效率和性能。而在不确定的聊天场景中,人类反馈信息可能带有偏见,甚至含有不轨意图,从而导致了对齐标准的不可靠。在这种情况下,在线人类反馈可能会恶化系统的性能。ChatGPT 正是通过离线的可靠的人类专家反馈来增强模型性能。因此,在引入人类反馈到学习任务之前,确保反馈信息的可靠性是成败关键。
人类反馈成功案例: 自动驾驶
自动驾驶汽车在减少交通事故方面有望超越人类驾驶员。然而,目前AD的技术水平仍远未达到预期。特定场景下基于规则和模型的技术,以及基于人工智能的方法,都不够聪明去处理开放、动态、无限的实际交通场景。以强化学习为例,它由奖励函数驱动,并通过与交通环境交互来学习如何驾驶汽车。但由于动态变化和复杂的驾驶环境,导致样本效率低下,学习成本高昂,奖励设计超难。

与ChatGPT类似,考虑到人类在复杂驾驶场景中的强鲁棒性和适应性,将人类作用引入AD的学习循环中以增强其智能具有重大潜力。基于此,我们对人类反馈在线增强的自动驾驶决策控制进行了研究,所提出的方法同样可以与基于离线人类驾驶数据的预训练相结合。
为了提高AD的学习速度和个性化能力,同时实现安全和持续的进化,我们提出基于混合增强智能 (HAI) 的决策控制框架,以将人类反馈纳入学习过程。首先,建立了基于交互强化学习 (Int-RL) 的决策层。在训练过程中,人类驾驶员对RL智能体进行实时监督,当其学习状态不合理时,利用人类引导决策代替机器决策,以此辅助学习过程。然后,将决策指令输出给控制层,使用模型预测控制 (MPC) 分别执行纵、横向运动控制任务。最后,提出了安全保障机制,建立了基于安全驾驶包络的探索/利用方法,以确保HAI系统的安全性。结果表明,所提出的框架可以实现AD决策控制的高效、可靠和安全地演进。
此外,为了提高自动驾驶强化学习算法在复杂场景下的样本数据效率,并增强车辆在拥堵交通场景下主动切入行驶的能力,我们提出了人类知识增强的强制换道方法。针对典型拥挤匝道出口场景,首先建立了安全探索保障机制。通过编码人类驾驶员先验知识并对状态空间的有效范围进行约束,以保证安全。然后引入了人类专家在线对车辆的不合理行为进行合理引导,并结合驾驶任务目标,构建了奖励/策略增强机制,以加速策略学习。最后,输出决策指令到控制模块以完成车辆控制任务。实验结果表明,所提出的方法提高了数据效率和训练速度,以及在不同交通流密度下车辆主动切入行驶的成功率。
在自动驾驶领域,安全可靠的人类反馈不仅可以提高车辆的学习效率,还可以塑造一个安全的、类人的、可信的AD系统。相反,不可靠的人类反馈可能会严重恶化系统性能,触发功能失效,造成安全事故。有资质的专业评价师或可以减少此问题的不利影响。为了进一步从普通驾驶员甚至乘坐人员学习驾驶技能,如何对人类反馈可靠性进行在线评估以设计反馈机制是一个关键问题。此外,由于人在反馈回路的引入,交通事故发生时不可避免地会出现责任分配的法律问题,因此在广泛应用如AD等以人为中心的智能系统的过程中,必须认真考虑量化或评估人为因素对事故的影响,甚至制定新的法律法规。
总之,从传统的单模态物理量到多模态感知,反馈保证了系统功能的实现和性能的提升。而人类反馈的引入,正在使更复杂和不确定环境下智能体的表现与人类对齐。可以预见,在大数据、大模型和大算力时代,反馈机制将为通用人工智能的涌现铺平道路。反馈即你所需!
文章信息
https://blog.sciencenet.cn/blog-528739-1385838.html
上一篇:中国航天日 | 文章精选
下一篇:2022年度《中国科学》《科学通报》优秀编委、优秀作者和优秀编辑名单揭晓