博文
面向效用的社会化网络数据K匿名发布
|||
这是是我们组刚刚发表在DASFAA 2011上的一篇论文,“Utility-Oriented K-Anonymization on Social Networks”
随着社会化网络(Social network)网站的兴起和流行,这些网站所获得的用户数据也就包含有极大的科研价值(utility),同时这些数据中又包含有用户的大量隐私信息(private information)。作为数据拥有者的网站方如果把social network数据发布出来是一个很大的问题:一方面用户的隐私信息不可以被泄露,另一方面发布的数据又要对科研人员有价值,如何权衡显得格外重要,这也是数据挖掘中一个重要的课题:隐私保护。
在传统表数据的隐私保护中提出了K匿名(K-Anonymity)的概念,也就是基于某些背景知识F,发布出去的数据中每个数据项都有K-1个其他数据项相同。在social network数据的发布中也同样的引进了K匿名的概念,同时根据不同的背景知识又分为:基于节点度的K匿名,基于顶点邻居结构的K匿名,基于对称的K匿名,基于同构的K匿名等等。图1给出一个这样基于节点度的K匿名例子
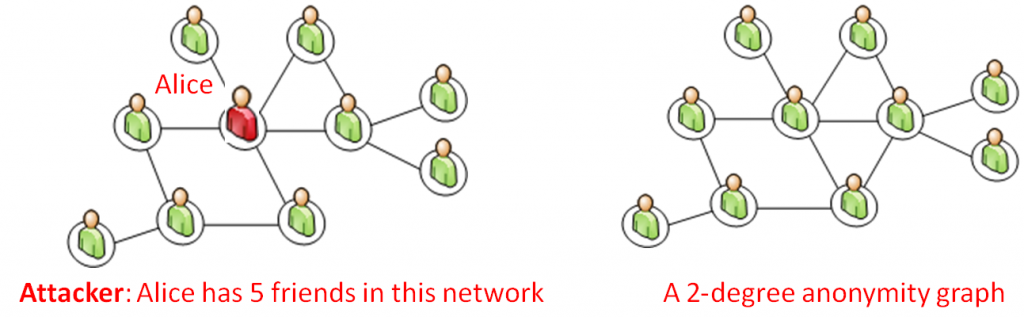
图1 基于顶点度的K匿名示例(K=2)
如果一个攻击者知道Alice在网络中有5个朋友,则在图1左侧的图中攻击者很容易就确定那个点代表Alice,而图1右侧的图中因为有两个顶点的度都是5,因此如果攻击者只有顶点度信息的话就无法定位Alice了。
显然,为了保护用户的隐私安全,在数据发布前我们需要对原始数据动些“手脚”,而且希望这些“手脚”对原数据的影响越小越好。之前的工作大部分使用 添加/删除 边/顶点 的数量来衡量影响。可是,我们发现同样一个加边操作,用着图的不同地方产生的影响也是不同的,如图2所示。

图2 不同加边位置对图结构影响不同示例
显然,G2相对G1来说更好的保护了原图G的结构信息。
为了衡量一个边操作对图结构的影响,我们使用Clauset等人提出的Hierarchical Random Graph (HRG)来管理图的community结构,并提出了Hierarchical Community Entropy (HCE)的概念来衡量每一个操作的影响。
https://blog.sciencenet.cn/blog-483379-433900.html
上一篇:Latex不常用宏包介绍(3)
下一篇:gnuplot生成嵌入字体的eps文件
随着社会化网络(Social network)网站的兴起和流行,这些网站所获得的用户数据也就包含有极大的科研价值(utility),同时这些数据中又包含有用户的大量隐私信息(private information)。作为数据拥有者的网站方如果把social network数据发布出来是一个很大的问题:一方面用户的隐私信息不可以被泄露,另一方面发布的数据又要对科研人员有价值,如何权衡显得格外重要,这也是数据挖掘中一个重要的课题:隐私保护。
在传统表数据的隐私保护中提出了K匿名(K-Anonymity)的概念,也就是基于某些背景知识F,发布出去的数据中每个数据项都有K-1个其他数据项相同。在social network数据的发布中也同样的引进了K匿名的概念,同时根据不同的背景知识又分为:基于节点度的K匿名,基于顶点邻居结构的K匿名,基于对称的K匿名,基于同构的K匿名等等。图1给出一个这样基于节点度的K匿名例子
图1 基于顶点度的K匿名示例(K=2)
如果一个攻击者知道Alice在网络中有5个朋友,则在图1左侧的图中攻击者很容易就确定那个点代表Alice,而图1右侧的图中因为有两个顶点的度都是5,因此如果攻击者只有顶点度信息的话就无法定位Alice了。
显然,为了保护用户的隐私安全,在数据发布前我们需要对原始数据动些“手脚”,而且希望这些“手脚”对原数据的影响越小越好。之前的工作大部分使用 添加/删除 边/顶点 的数量来衡量影响。可是,我们发现同样一个加边操作,用着图的不同地方产生的影响也是不同的,如图2所示。
图2 不同加边位置对图结构影响不同示例
显然,G2相对G1来说更好的保护了原图G的结构信息。
为了衡量一个边操作对图结构的影响,我们使用Clauset等人提出的Hierarchical Random Graph (HRG)来管理图的community结构,并提出了Hierarchical Community Entropy (HCE)的概念来衡量每一个操作的影响。
https://blog.sciencenet.cn/blog-483379-433900.html
上一篇:Latex不常用宏包介绍(3)
下一篇:gnuplot生成嵌入字体的eps文件