博文
拟合度卡方检验——摘抄《应用数理统计方法》_陶澍
||
拟合度的卡方检验用于比较属于离散类型变量的样本所代表的的背景总体是否服从特定的理论或经验分布形式。其检验对象通常是以频数表示的类型数据。相应的理论或经验频数(期望频数)可以根据实际样本量和该分布的特定参数计算出来。卡方检验就是根据每一类别的实际观测频数与期望频数之间的差异大小来确定分布的异同。
对于类别间无固定顺序的类型变量,卡方检验是功效最强的拟合度检验方法之一。如果原始数据属连续型定量变量,也可以用分组统计方法将其离散化得出频数数据,然后利用卡方检验作分布类型判断,但这样的做法会造成数据信息(每个观测值的大小信息以及类型顺序信息)的浪费。这就是为什么用卡方检验进行连续数据的正态检验或其他分布检验不合适的主要原因。
卡方检验得名于其检验统计量在原假设成立时的抽样分布从属于卡方分布。其基本原理与第二章第2.5.2小节介绍的推广的中位数法的显著性检验类似。推广的中位数法首先将数据转换成大于或小于公共中位数的频数数据,并以每一样本中大于和小于公共中位数的数据个数是否相同作为判断若干样本的大小是否一致的依据。而本节介绍的以频率分析为目的的卡方检验,则直接对频数分布进行比较,故其检验的统计假设为:
H0:总体服从某一特定的分布类型;
H1:总体不服从某一特定的分布类型。
上述统计假设用的是一般表达式,即观测结果是否服从某一特定的理论或经验分布类型,而检验的直接对象却是观测频数与期望频数是否一致。因此还可以将统计假设用另一种形式表述为:
H0:各类别观测频数与期望频数之间没有明显差别;
H1:各类别观测频数与期望频数之间有明显差别。
由于考察对象仅与上述差别的平方和有关,所以无论观测频数大于还是小于期望频数,在检验中是同等对待的。正因为如此,卡方检验没有单双侧之分。
由于拟合度卡方检验是针对频数数据的,如果待检验的原始数据是定量变量,就必须进行分组统计,将观测结果归入a个类别中,并求出每一类别的观测频数:
Pi i=1····a
按照观测结果的分组方式,根据总样本量以及所检验的分布模型计算出每一类别的期望频数,并记为:
Pi^ i=1····a
例如,对于分成8个类别的200个数据,如果对它们是否服从均匀分布进行检验,那么8个类别的理论频数都应当等于:
Pi^= 200/8 =25
再如,同样将200个数据分到等差分布的8个类别中去,如果类别差是4的话,所得期望分布应当是:
Pi^ = 11
Pi^ = 15
······
Pi^ = 39
如果某些类别的期望频数太小,即当某一类别的期望频数为零,或者20%以上类别的期望频数小于5时,直接进行卡方检验可能导致错误结果。这时应将小频数类别与相邻类别合并,以满足分析要求。
检验统计量为a项之和。每项等于一个类别中观测频数与期望频数之差的平方和除以相应的期望频数。
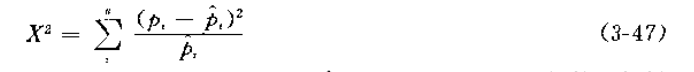
式中Pi为第i类别的观测频数,Pi^代表该类别的期望频数。如果样本量小于200,有必要作连续型校正,即按下式计算检验统计量:
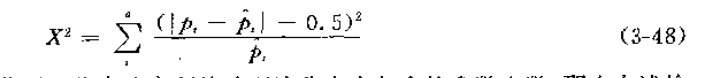
若用k代表确定所检验理论分布中包含的参数个数,那么上述检验统计量在原假设成立时的抽样分布服从自由度为 v = a-k-1 的卡方分布。以均匀分布为例,由于不涉及任何特定参数,故:k=0; 对于正态分布,因包含均值和方差两个参数,取 k=2 ,如此等等。计算结果可直接与附表A4种列举的检验临界值 α[a-k-1]比较,如果计算值大于临界值:
α[a-k-1]比较,如果计算值大于临界值:
> α[a-k-1]便可以拒绝检验的原假设。
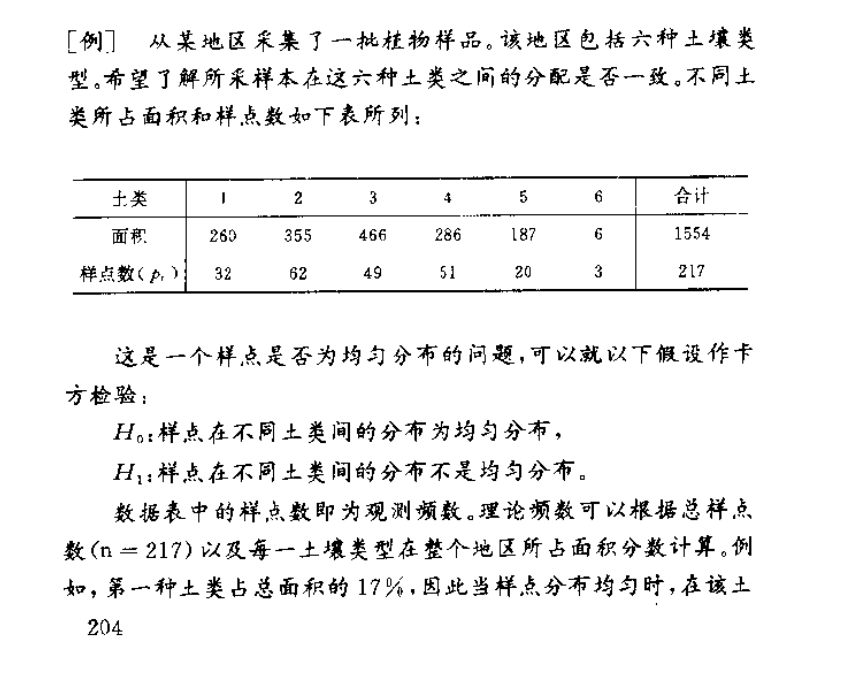


二、paml_codeml正选择_branch-site model,2 delta=2*(lnL_alter-lnL_null)
R语言计算卡方检验统计量的p值
p<- pchisq( 2 delta, df = 1, lower.tail=F ) #若p<0.05,则认为可拒绝null假设,认为指定的前景分支与背景分支的进化速率w存在显著差异
https://blog.sciencenet.cn/blog-3434047-1390527.html
上一篇:[转载]iqtree建树命令
下一篇:[转载]ggtree美化进化树