博文
基于i向量和变分自编码相对生成对抗网络的语音转换
|
引用本文
李燕萍, 曹盼, 左宇涛, 张燕, 钱博. 基于i向量和变分自编码相对生成对抗网络的语音转换. 自动化学报, 2022, 48(7): 1824−1833 doi: 10.16383/j.aas.c190733
Li Yan-Ping, Cao Pan, Zuo Yu-Tao, Zhang Yan, Qian Bo. Voice conversion based on i-vector with variational autoencoding relativistic standard generative adversarial network. Acta Automatica Sinica, 2022, 48(7): 1824−1833 doi: 10.16383/j.aas.c190733
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c190733
关键词
语音转换,相对生成对抗网络,i向量,非平行文本,变分自编码器,多对多
摘要
提出一种基于i向量和变分自编码相对生成对抗网络的语音转换方法, 实现了非平行文本条件下高质量的多对多语音转换. 性能良好的语音转换系统, 既要保持重构语音的自然度, 又要兼顾转换语音的说话人个性特征是否准确. 首先为了改善合成语音自然度, 利用生成性能更好的相对生成对抗网络代替基于变分自编码生成对抗网络模型中的Wasserstein生成对抗网络, 通过构造相对鉴别器的方式, 使得鉴别器的输出依赖于真实样本和生成样本间的相对值, 克服了Wasserstein生成对抗网络性能不稳定和收敛速度较慢等问题. 进一步为了提升转换语音的说话人个性相似度, 在解码阶段, 引入含有丰富个性信息的i向量, 以充分学习说话人的个性化特征. 客观和主观实验表明, 转换后的语音平均梅尔倒谱失真距离值较基准模型降低4.80%, 平均意见得分值提升5.12%, ABX 值提升8.60%, 验证了该方法在语音自然度和个性相似度两个方面均有显著的提高, 实现了高质量的语音转换.
文章导读
语音转换是在保持语音内容不变的同时, 改变一个人的声音, 使之听起来像另一个人的声音[1-2]. 根据训练过程对语料的要求, 分为平行文本条件下的语音转换和非平行文本条件下的语音转换. 在实际应用中, 预先采集大量平行训练文本不仅耗时耗力, 而且在跨语种转换和医疗辅助系统中往往无法采集到平行文本, 因此非平行文本条件下的语音转换研究具有更大的应用背景和现实意义.
性能良好的语音转换系统, 既要保持重构语音的自然度, 又要兼顾转换语音的说话人个性信息是否准确. 近年来, 为了改善转换后合成语音的自然度和说话人个性相似度, 非平行文本条件下的语音转换研究取得了很大进展, 根据其研究思路的不同, 大致可以分为3类, 第1类思想是从语音重组的角度, 在一定条件下将非平行文本转化为平行文本进行处理[3-4], 其代表算法包括两种, 一种是使用独立于说话人的自动语音识别系统标记音素, 另一种是借助文语转换系统将小型语音单元拼接成平行语音. 该类方法原理简单, 易于实现, 然而这些方法很大程度上依赖于自动语音识别或文语转换系统的性能; 第2类是从统计学角度, 利用背景说话人的信息作为先验知识, 应用模型自适应技术, 对已有的平行转换模型进行更新, 包括说话人自适应[5-6]和说话人归一化等. 但这类方法通常要求背景说话人的训练数据是平行文本, 因此并不能完全解除对平行训练数据的依赖, 还增加了系统的复杂性; 前两类通常只能为每个源−目标说话人对构建一个映射函数, 即一对一转换, 当存在多个说话人对时, 就需要构建多个映射函数, 增加系统的复杂性和运算量; 第3类是解卷语义和说话人个性信息的思想, 转换过程可以理解为源说话人语义信息和目标说话人个性信息的重构, 其代表算法包括基于条件变分自编码器 (Conditional variational auto-Encoder, C-VAE)[7]方法、基于变分自编码生成对抗网络(Variational autoencoding wasserstein generative adversarial network, VAWGAN)[8]方法和基于星型生成对抗网络 (Star generative adversarial network, StarGAN)[9]方法. 这类方法直接规避了非平行文本对齐的问题, 实现将多个源−目标说话人对的转换整合在一个转换模型中, 提供了多说话人向多说话人转换的新框架, 即多对多转换, 成为目前非平行文本条件下语音转换的主流方法.
基于C-VAE模型的语音转换方法, 其中的编码器对语音实现语义和个性信息的解卷, 解码器通过语义和说话人身份标签完成语音的重构, 从而解除对平行文本的依赖, 实现多说话人对多说话人的转换. 但是由于C-VAE基于理想假设, 认为观察到的数据通常遵循高斯分布, 导致解码器的输出语音过度平滑, 转换后的语音质量不高. 基于循环一致生成对抗网络的语音转换方法[10]可以在一定程度上解决过平滑问题, 但是该方法只能实现一对一的语音转换.
Hsu等[8]提出的VAWGAN模型通过在C-VAE中引入Wasserstein生成对抗网络(Wasserstein generative adversarial network, WGAN)[11], 将 VAE的解码器指定为WGAN的生成器来优化目标函数, 一定程度上提升转换语音的质量, 然而Wasserstein生成对抗网络仍存在一些不足之处, 例如性能不稳定, 收敛速度较慢等. 同时, VAWGAN使用说话人身份标签one-hot向量建立语音转换系统, 而该指示标签无法携带更为丰富的说话人个性信息, 因此转换后的语音在个性相似度上仍有待提升.
针对上述问题, 本文从以下方面提出改进意见: 1)通过改善生成对抗网络[12]的性能, 进一步提升语音转换模型生成语音的清晰度和自然度; 2)通过引入含有丰富说话人个性信息的表征向量, 提高转换语音的个性相似度. 2019年, Baby等[13]通过实验证明, 相比于WGAN, 相对生成对抗网络(Relativistic standard generative adversarial networks, RSGAN)生成的数据样本更稳定且质量更高. 此外, 在说话人确认[14-16]和说话人识别[17]领域的相关实验证明, i向量(Identity-vector, i-vector)可以充分表征说话人个性信息. 鉴于此, 本文提出基于i向量和变分自编码相对生成对抗网络的语音转换模型(Variational autoencoding RSGAN and i-vector, VARSGAN + i-vector), 该方法将RSGAN应用在语音转换领域, 利用生成性能更好的相对生成对抗网络替换VAWGAN模型中的Wasserstein生成对抗网络, 同时在解码网络引入含有丰富说话人个性信息的i向量辅助语音的重构. 充分的客观和主观实验表明, 本文方法在有效改善合成语音自然度的同时进一步提升了说话人个性相似度, 实现了非平行文本条件下高质量的多对多语音转换.
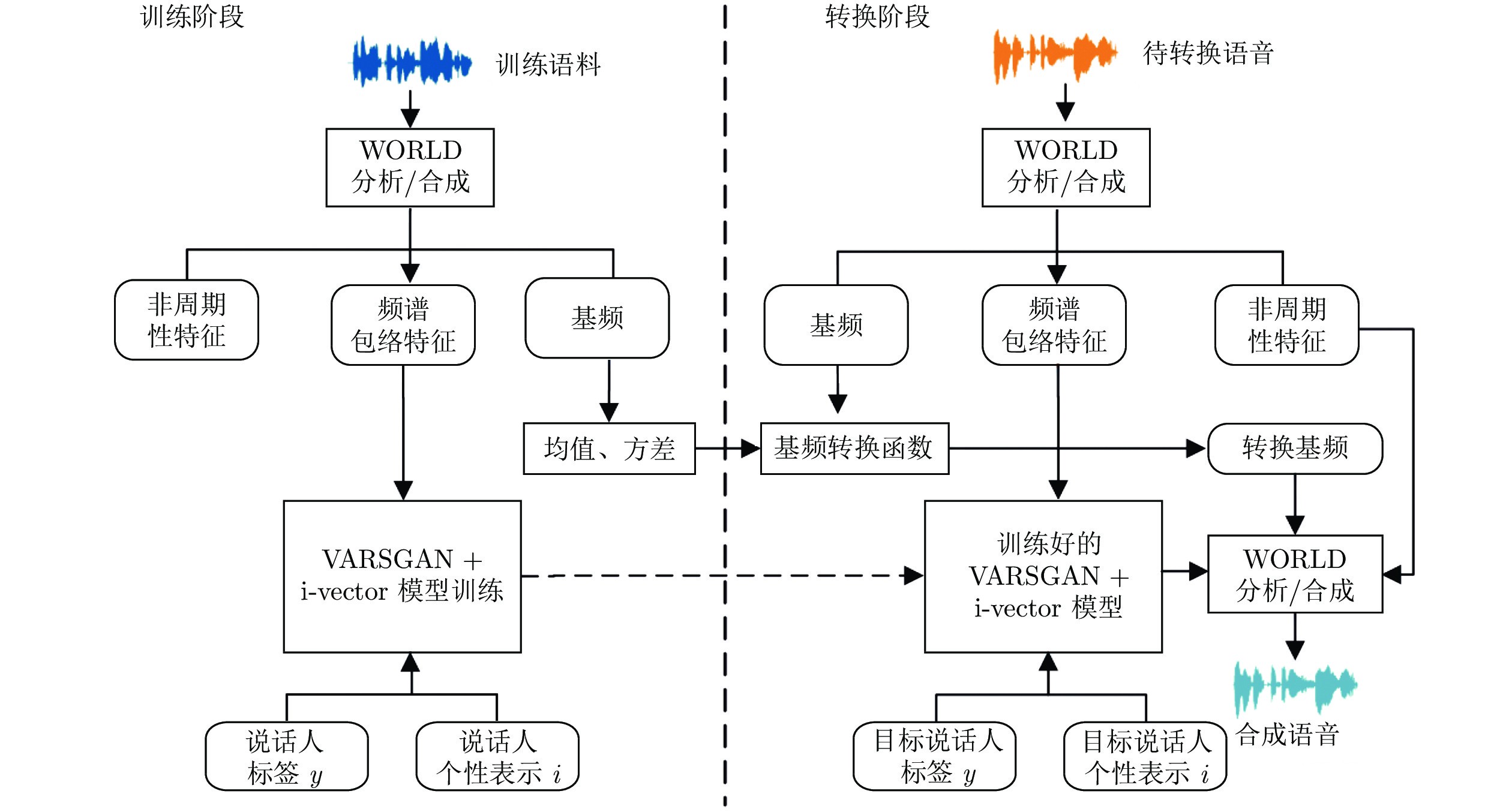
图 1 基于VARSGAN + i-vector 模型的整体流程图
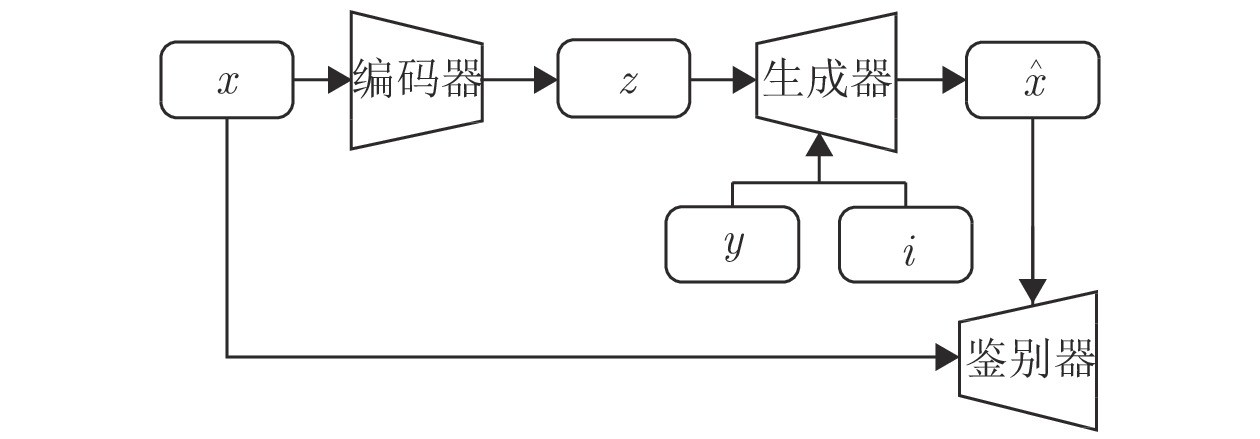
图 2 VARSGAN+i-vector 模型原理示意图
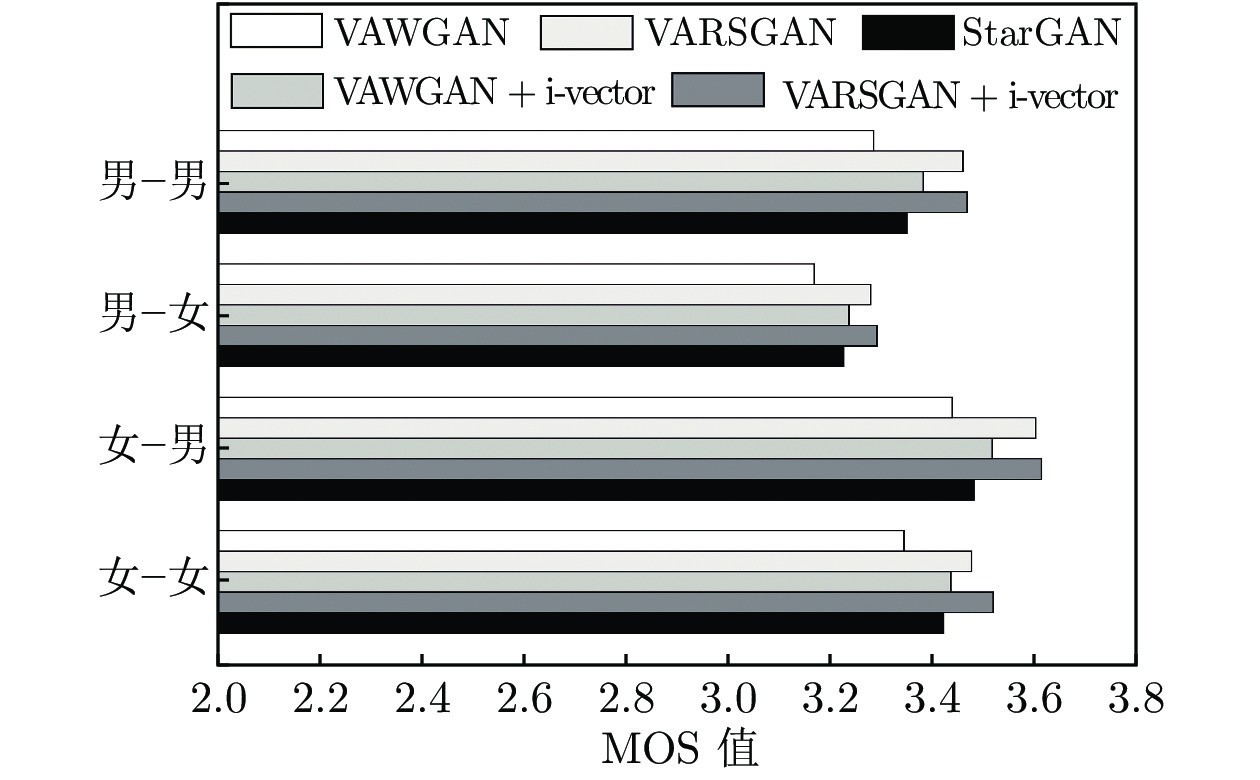
图 6 5种模型在不同转换类别下的MOS值对比
本文提出一种基于VARSGAN + i-vector的语音转换模型, 该方法利用RSGAN 替代基准模型中的WGAN, 改进了语音转换模型中生成对抗网络的性能, 从而生成语音自然度更好的转换语音. 进一步将i向量引入基于VARSGAN的语音转换模型, 在模型训练和转换过程中利用i向量表征说话人的个性信息, 有效提升转换语音的个性相似度. 充分的客观和主观实验结果表明, 相比于基准模型 VAWGAN 和 StarGAN, 本文提出的方法在有效改善转换语音的合成质量的同时, 也显著提升了说话人个性相似度, 实现了高质量的语音转换. 今后工作将研究序列到序列的语音转换, 进一步考虑韵律特征的建模和转换, 此外, 降低对训练数据量的需求以实现小样本语音转换[26]也是课题组后续进一步研究的关注点和探索方向, 这也是该技术真正进入工业领域需要接受的挑战之一.
作者简介
李燕萍
南京邮电大学通信与信息工程学院副教授. 2009年获南京理工大学博士学位. 主要研究方向为语音转换和说话人识别. 本文通信作者. E-mail: liyp@njupt.edu.cn
曹盼
南京邮电大学通信与信息工程学院硕士研究生. 2017年获淮阴师范学院学士学位. 主要研究方向为语音转换和深度学习. E-mail: abreastpc@163.com
左宇涛
南京邮电大学通信与信息工程学院硕士研究生. 主要研究方向为语音转换. E-mail: zuoyt@chinatelecom.cn
张燕
金陵科技学院软件工程学院教授. 2017年获南京理工大学博士学位. 主要研究方向为模式识别和领域软件工程. E-mail: zy@jit.edu.cn
钱博
南京电子技术研究所高级工程师. 2007年获南京理工大学博士学位. 主要研究方向为模式识别和人工智能. E-mail: sandson6@163.com
https://blog.sciencenet.cn/blog-3291369-1347102.html
上一篇:采用分类经验回放的深度确定性策略梯度方法
下一篇:基于上下文和浅层空间编解码网络的图像语义分割方法