博文
采用分类经验回放的深度确定性策略梯度方法
|
引用本文
时圣苗, 刘全. 采用分类经验回放的深度确定性策略梯度方法. 自动化学报, 2022, 48(7): 1816−1823 doi: 10.16383/j.aas.c190406
Shi Sheng-Miao, Liu Quan. Deep deterministic policy gradient with classified experience replay. Acta Automatica Sinica, 2022, 48(7): 1816−1823 doi: 10.16383/j.aas.c190406
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c190406
关键词
连续控制任务,深度确定性策略梯度,经验回放,分类经验回放
摘要
深度确定性策略梯度(Deep deterministic policy gradient, DDPG)方法在连续控制任务中取得了良好的性能表现. 为进一步提高深度确定性策略梯度方法中经验回放机制的效率, 提出分类经验回放方法, 并采用两种方式对经验样本分类: 基于时序差分误差样本分类的深度确定性策略梯度方法(DDPG with temporal difference-error classification, TDC-DDPG)和基于立即奖赏样本分类的深度确定性策略梯度方法(DDPG with reward classification, RC-DDPG).在TDC-DDPG和RC-DDPG方法中, 分别使用两个经验缓冲池, 对产生的经验样本按照重要性程度分类存储, 网络模型训练时通过选取较多重要性程度高的样本加快模型学习. 在连续控制任务中对分类经验回放方法进行测试, 实验结果表明, 与随机选取经验样本的深度确定性策略梯度方法相比, TDC-DDPG和RC-DDPG方法具有更好的性能.
文章导读
强化学习(Reinforcement learning, RL)中, Agent采用“试错”的方式与环境进行交互, 通过从环境中获得最大化累积奖赏寻求最优策略[1]. RL算法根据Agent当前所处状态求解可执行动作, 因此RL适用于序贯决策问题的求解[2]. 利用具有感知能力的深度学习作为RL状态特征提取的工具, 二者结合形成的深度强化学习(Deep reinforcement learning, DRL)算法是目前人工智能领域研究的热点之一[3-4].
在线DRL算法采用增量式方法更新网络参数, 通过Agent与环境交互产生经验样本e=(st,at,rt,st+1), 直接将此样本用于训练网络参数, 在一次训练后立即丢弃传入的数据[5]. 然而此方法存在两个问题: 1)训练神经网络的数据要求满足独立同分布, 而强化学习中产生的数据样本之间具有时序相关性. 2)数据样本使用后立即丢弃, 使得数据无法重复利用. 针对以上问题, Mnih等[6]采用经验回放的方法, 使用经验缓冲池存储经验样本, 通过随机选取经验样本进行神经网络训练. 然而经验回放方法中未考虑不同经验样本具有不同的重要性, 随机选取无法充分利用对网络参数更新作用更大的经验样本. Schaul等[7]根据经验样本的重要性程度赋予每个样本不同的优先级, 通过频繁选取优先级高的经验样本提高神经网络训练速度. 优先级经验回放一方面增加了对经验样本赋予和更改优先级的操作, 另一方面需要扫描经验缓冲池以获取优先级高的经验样本, 因此增加了算法的时间复杂度. 与优先级经验回放不同, 本文提出的分类经验回放方法对不同重要性程度的经验样本分类存储. 将此方法应用于深度确定性策略梯度(Deep deterministic policy gradient, DDPG)算法中, 提出了采用分类经验回放的深度确定性策略梯度(Deep deterministic policy gradient with classified experience replay, CER-DDPG)方法. CER-DDPG采用两种分类方式: 1)根据经验样本中的时序差分误差(Temporal difference-error, TD-error); 2)基于立即奖赏值进行分类. 其中, TD-error代表Agent从当前状态能够获得的学习进度, RL经典算法Sarsa、Q-leaning均采用一步自举的方式计算TD-error实现算法收敛. CER-DDPG中, 将大于TD-error平均值或立即奖赏平均值的经验样本存入经验缓冲池1中, 其余存入经验缓冲池2中. 网络训练时每批次从经验缓冲池1中选取更多数量的样本, 同时为保证样本的多样性, 从经验缓冲池2中选取少量的经验样本, 以此替代优先级经验回放中频繁选取优先级高的经验样本. 分类经验回放方法具有和普通经验回放方法相同的时间复杂度, 且未增加空间复杂度.
本文主要贡献如下:
1) 采用双经验缓冲池存储经验样本, 并根据经验样本中的TD-error和立即奖赏值完成对样本的分类;
2) 从每个经验缓冲池中选取不同数量的经验样本进行网络参数更新;
3) 在具有连续动作空间的RL任务中进行实验, 结果表明, 相比随机采样的DDPG算法, 本文提出的基于时序差分误差样本分类的深度确定性策略梯度方法(DDPG with temporal difference-errer classification, TDC-DDPG)和基于立即奖赏样本分类的深度确定性策略梯度方法(DDPG with reward classification, RC-DDPG)能够取得更好的实验效果. 并与置信区域策略优化(Trust region policy optimization, TRPO)算法以及近端策略优化(Proximal policy optization, PPO)算法进行比较, 进一步证明了本文所提出算法的有效性.
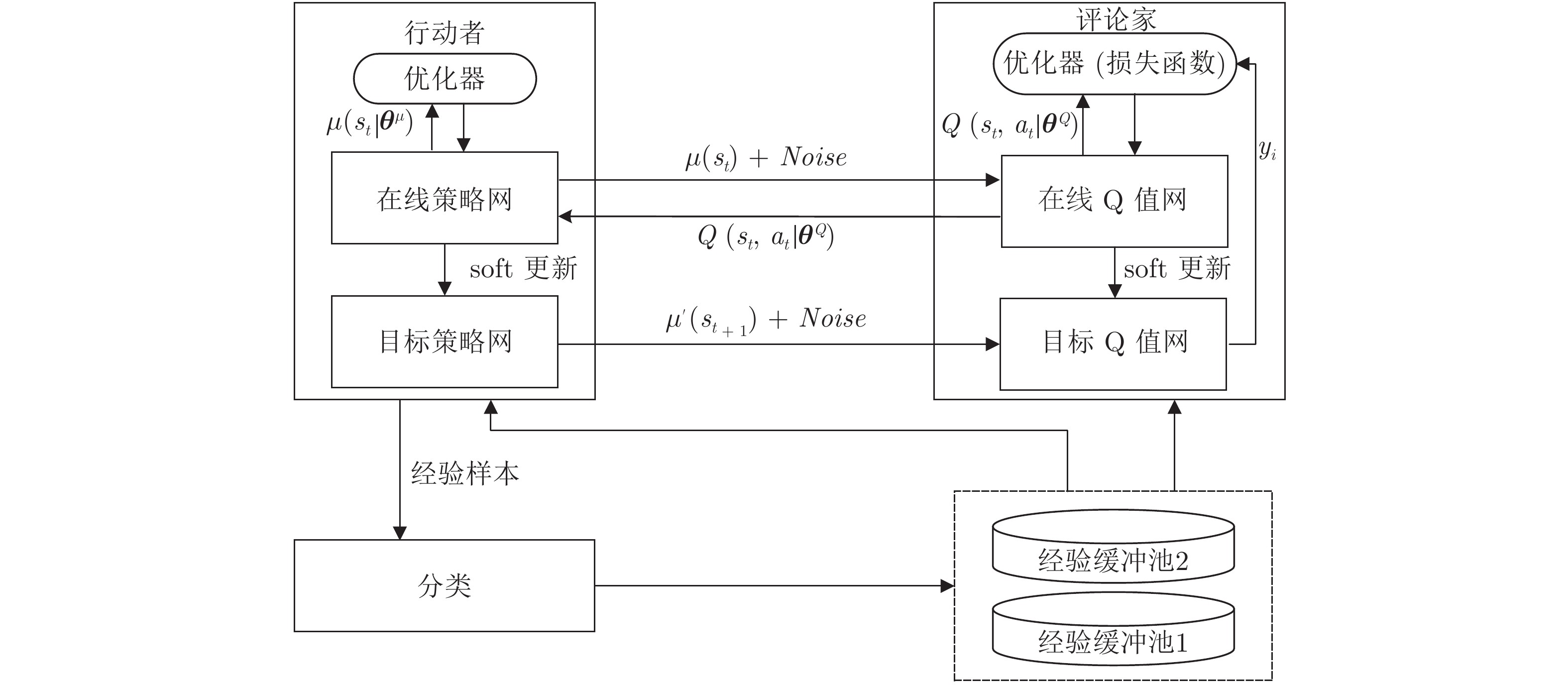
图 1 CER-DDPG算法结构示意图
DDPG算法在解决连续动作空间RL问题上取得了巨大成功. 网络模型学习过程中, 使用经验回放机制打破了经验样本之间存在的时序相关性. 然而经验回放未考虑不同经验样本的重要性, 不能有效利用样本数据, 对样本设置优先级又增加了算法时间复杂度. 因此, 本文提出分类经验回放方法并利用经验样本的TD-error和立即奖赏值进行分类存储用于解决经验回放中存在的问题. 在具有连续状态动作空间RL任务中的实验结果表明, 本文提出的TDC-DDPG和RC-DDPG方法在连续控制任务中表现更优.
作者简介
时圣苗
苏州大学计算机科学与技术学院硕士研究生. 主要研究方向为深度强化学习.E-mail: 20175227045@stu.suda.edu.cn
刘全
苏州大学教授. 主要研究方向为深度强化学习, 自动推理. 本文通信作者.E-mail: quanliu@suda.edu.cn
https://blog.sciencenet.cn/blog-3291369-1346961.html
上一篇:多维注意力特征聚合立体匹配算法
下一篇:基于i向量和变分自编码相对生成对抗网络的语音转换