博文
多维注意力特征聚合立体匹配算法
|
引用本文
张亚茹, 孔雅婷, 刘彬. 多维注意力特征聚合立体匹配算法. 自动化学报, 2022, 48(7): 1805−1815 doi: 10.16383/j.aas.c200778
Zhang Ya-Ru, Kong Ya-Ting, Liu Bin. Multi-dimensional attention feature aggregation stereo matching algorithm. Acta Automatica Sinica, 2022, 48(7): 1805−1815 doi: 10.16383/j.aas.c200778
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c200778
关键词
深度学习,立体匹配,多维注意力机制,信息交互
摘要
现有基于深度学习的立体匹配算法在学习推理过程中缺乏有效信息交互, 而特征提取和代价聚合两个子模块的特征维度存在差异, 导致注意力方法在立体匹配网络中应用较少、方式单一. 针对上述问题, 本文提出了一种多维注意力特征聚合立体匹配算法. 设计2D注意力残差模块, 通过在原始残差网络中引入无降维自适应2D注意力残差单元, 局部跨通道交互并提取显著信息, 为匹配代价计算提供丰富有效的特征. 构建3D注意力沙漏聚合模块, 以堆叠沙漏结构为骨干设计3D注意力沙漏单元, 捕获多尺度几何上下文信息, 进一步扩展多维注意力机制, 自适应聚合和重新校准来自不同网络深度的代价体. 在三大标准数据集上进行评估, 并与相关算法对比, 实验结果表明所提算法具有更高的预测视差精度, 且在无遮挡的显著对象上效果更佳.
文章导读
计算两个输入图像上对应像素的相对水平立体匹配对于理解或重建3D场景至关重要, 广泛应用于自动驾驶[1]、无人机[2]、医学成像和机器人智能控制等领域. 通常, 给定一对校正后的图像, 立体匹配的目标是位移, 即视差.
近年来, 基于深度学习的立体匹配算法研究已取得重大进展, 相比传统方法[3-4], 可从原始数据理解语义信息, 在精度和速度方面有着显著优势. 早期基于深度学习的方法[5-6]是经卷积神经网络(Convolutional neural network, CNN)获得一维特征相关性度量之后, 采用一系列传统的后处理操作预测最终视差, 无法端到端网络训练. 随着全卷积神经网络(Fully convolutional networks, FCN)的发展[7], 研究者们提出了将端到端网络整合到立体匹配模型中[8-16]. 对于全卷积深度学习立体匹配网络, PSMNet[17]提出一种空间金字塔池化模块, 扩大深层特征感受野, 提取不同尺度和位置的上下文信息. CFPNet[18]在金字塔模块基础上引入扩张卷积和全局平均池化扩大感受野, 使其更有效地感知全局上下文信息. MSFNet[19]利用多尺度特征模块, 通过级联融合不同层级的特征捕获细节和语义特征. 除了以上对特征提取网络的研究之外, 在代价聚合中, 第一个端到端视差估计网络DispNet[20]提出沿视差方向计算一维相关性的匹配代价计算方法. 由于仅沿着一个维度计算相关性, 损失了其余多个维度的有效信息, 因此为了更好地利用多维度的上下文语义特征, Kendall等[21]提出了GC-Net, 通过采用3D编解码结构在三个维度上理解全局语义信息. 受GC-Net启发, 众多学者提出了多种变体来正则化代价体, 建模匹配过程, 例如, 结合2D和3D卷积运算的多维聚合子网络[22]、多尺度残差3D卷积模块[23]、堆叠3D沙漏结构[17, 24]等. 尽管上述方法在视差估计中已取得长足进步, 但在网络学习推理过程中, 图像特征和代价体特征的多层级多模块交互利用仍存在不足, 缺乏全局网络信息的长距离依赖, 导致网络不具有敏锐的鉴别性能, 准确估计视差依然极具挑战性.
随着注意力机制在多种研究任务, 如语义分割[25]、 自然语言处理[26]、超分辨率[27]等方面的广泛应用, 注意力机制在立体匹配网络中引起了关注[28-30]. 其中, 基于SE-Net[31]的扩张空间金字塔注意力模块[28]虽然采用降维减小了计算成本, 但是降维的同时导致特征通道与其权重之间的对应是间接的, 降低了通道注意力的学习能力. MRDA-Net[30]只在2D特征提取网络末端和3D编解码网络末端引入单一池化3D注意力模块来整合全局信息, 无法做到多模块信息交互, 导致网络获取显著信息不充分. 综上, 由于2D图像特征为3D张量, 3D代价体特征为四维张量, 两者之间的维度差异使常规注意力方法无法同时应用于特征提取与代价聚合这两个子模块中, 注意力机制在立体匹配网络中应用较少、方式单一, 从而整个立体匹配网络缺乏有效协同的注意力机制, 对长距离上下文信息无法做到多模块多层级关注.
考虑上述问题, 本文在Gwc-Net[24]的基础上提出一种多维注意力特征聚合立体匹配算法, 通过对特征提取和代价聚合两个子模块设计不同的注意力方法, 从多模块多层级的角度去理解关注整个网络传输过程中的上下文信息. 设计2D注意力残差模块, 使用无降维自适应2D通道注意力, 逐像素提取和融合更全面有效的信息特征, 学习局部跨通道间的相关性, 自适应关注通道间的区别信息. 提出3D注意力沙漏聚合模块, 利用3D平均池化和3D最大池化构建3D通道注意力, 将其嵌入多个子编解码块的末端, 重新校准来自不同模块的多个代价体, 整合多模块输出单元计算匹配代价.

图 1 算法网络结构图
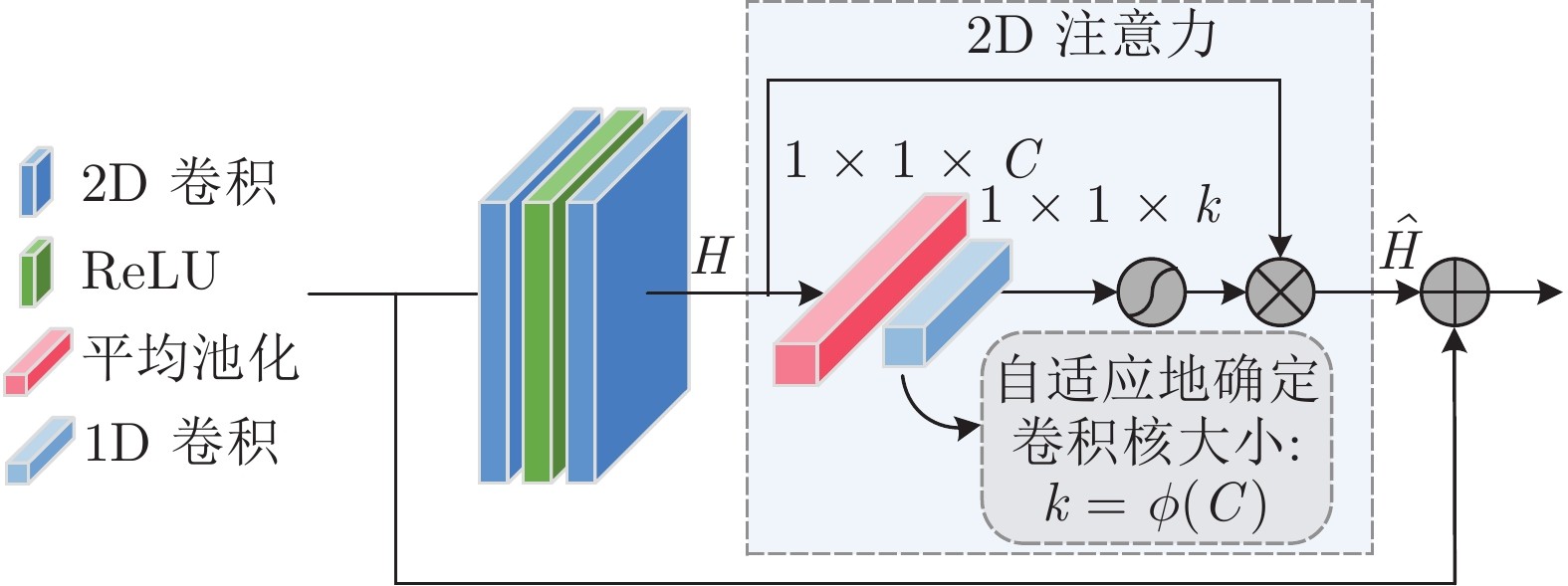
图 2 2D注意力残差单元结构图

图 3 联合代价体结构图
本文提出了一种多维注意力特征聚合立体匹配算法, 以多模块及多层级的嵌入方式协同两种不同维度的注意力单元. 2D注意力残差模块在原始残差网络基础上引入自适应无降维2D通道注意力, 理解局部跨通道间的相互依赖性, 保留显著细节特征, 为代价聚合过程提供了全面有效的相似性度量. 3D注意力沙漏聚合模块在多个沙漏结构的基础上嵌入双重池化3D注意力单元, 捕获多尺度上下文信息, 有效提高了网络的聚合能力. 2D注意力和3D注意力之间相辅相成, 对整个网络的权重修正, 误差回传都起到了积极的作用. 在3个公开数据集上的实验结果表明, 所提算法不仅具有较高的预测精度, 而且可以敏锐地鉴别推理无遮挡区域中主体对象的显著性特性.
作者简介
张亚茹
燕山大学博士研究生. 主要研究方向为人工智能, 计算机视觉和计算机图形学. E-mail: yrzhang1014@163.com
孔雅婷
燕山大学硕士研究生. 主要研究方向为人工智能, 计算机视觉和计算机图形学. E-mail: kongyt10@163.com
刘彬
燕山大学信息科学与工程学院教授. 主要研究方向为人工智能和计算机视觉. 本文通信作者.E-mail: liubin@ysu.edu.cn
https://blog.sciencenet.cn/blog-3291369-1346960.html
上一篇:大幅面DLP型3D打印机错位均摊接缝消除方法研究
下一篇:采用分类经验回放的深度确定性策略梯度方法