博文
隐马尔科夫模型简介(一)
|||
1. 一个简单的例子
假设我们想知道某个固定的地区一些年来的平均年平均气温。为了让这个问题变得有趣,我们假设我们关注的这些年份是在温度计发明之前的遥远过去。我们不能回到过去,所以需要寻找与温度相关的非直接证据。
为了简化问题,仅会考虑两种年平均温度,"hot"和"cold"。假设现代的证据证明hot year之后又是一个hot year的概率是0.7,cold year之后又是一个cold year的概率是0.6,而且这个概率在过去的岁月里都适用,那么目前的信息总结如下:
 (1)
(1)
其中H代表"hot",C代表''cold"。
另外,当前的研究证实树的年轮与温度相关。也为了简化起见,我们将树的年轮分为三种大小:small,medium和large,分别用S, M和L表示。最后基于存在的证据显示,年平均温度与树的年轮之间的关系如下:
 (2)
(2)
对于这个例子来说,状态(state)是年平均气温,H或C。从一种状态到另一种状态的转移过程是马尔科夫过程(Markov process)。因为下一个状态仅依赖于当前状态,而且符合如矩阵(1)的固定概率。然而,真实的状态是隐藏的("hidden"),因为我们不能直接获取到过去那些年份的气温。
虽然我们不能观测到过去那些年的状态(气温),但是我们可以观测到树的年轮大小。通过矩阵(2),树的年轮告诉我们关于气温的概率信息。因为状态是隐藏的,这种类型的系统我们称为隐马尔科夫模型(Hidden Markov Model,HMM)。我们的目标是有效地,且高效地利用观测到的数据了解马尔科夫过程的不同特征。
我们称矩阵(1)为状态转移矩阵(state transition matrix):
 (3)
(3)
称矩阵(2)为观测矩阵(state transition matrix):
 (4)
(4)
在这个例子中,还需要知道一个初始状态分布(initial state distribution),记为π,而且假设
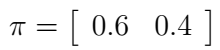 (5)
(5)
[注] 这里的初始状态分布指关注的这几年中,最开始的那一年,高温的概率为0.6,低温的概率是0.4 (注:这个对应关系在文章中虽未明说,但从后面的算式中可查看到)
A、B和π中每个元素都是概率值,矩阵中每行都是一个概率分布,每行之和为1。
现在我们关注的四年(例如2007-2010年),我们观测到这四年树的年轮分别为S, M, S和L,且用0表示S,1表示M,2表示L,那么观测链如下:
 (6)
(6)
如下图:

通过观测到的年轮结果,我们想推测出最可能(most likely)的马尔科夫过程状态链(注:也即这四年气温情况分别是怎样的)。这个问题不像看起来那么可以一刀切(clear-cut),因为对"most likely"人们有不同的理解。一方面,我们可以将"most likely"大致地定义为,所有长度为4的可能状态链中概率最高的那种状态链。(注:也即所有可能的2^4种状态[每一年要么是高温要么是低温,而且有4年],每种状态都有对应的概率,这其中概率最大的那种)。我们可以采用动态规划算法(Dynamic programming, DP)来求解出这个特殊解。
另一方面,我们可能会将"most likely"合理地定义为,使状态链中每个状态的可能最大化 (注:例如状态链中第一个状态最可能是低温,第二、三、四个状态最可能是高温、低温、高温,那么最后整条状态链最可能是低温-高温-低温-高温)。
其实,动态规划算法得到的解与隐马尔科夫算法得到的解并一定完全一致。动态规划算法必须要有合理的状态转移,而这个在隐马尔科夫模型算法中不是必须的。(注:老实说读到这里才开始真正佩服HMM!另外,有关动态规划算法,欢迎关注我的另一篇博文:http://blog.sciencenet.cn/blog-2970729-1112311.html) 而且,即使所有的状态转移都是合理的,HMM方法也不同于DP方法,那就是在处理标记问题时(notation)。
2. 标记问题

所有可能的观测结果通常用{0,1,...,M-1}表示,因为这样可以在不失普遍性的前提下,使标记问题简单化。观测到的序列依次用Oi表示,其中Oi∈V for i = 0, 1,...,T-1。
注:用上面的例子来说,T为4,表示观测的年份数,从2007-2012共4年;
N为2,表示观测状态数,气温要么是高温,要么是低温;
M是3,表示树的年轮大小数,年轮要么是大号(L),要么是中号(M),要么是小号(S);
Q是高温和低温,即{H,C},它是一个集合!是所有可能的马尔科夫状态集合;
V是大号(L)、中号(M)和小号(S),对应为数字即{0, 1, 2},是一个集合!是所有可能的观测结果集合;
A是状态转移矩阵,是一个矩阵!如果写成概率公式,如下:
B是观测矩阵,是一个矩阵!如果写成概率公式,如下:

注意:这两个公式后面会有用到!另外,A和B矩阵是行随机的。它们和状态无关,是客观存在的规律。
π是初始状态分布;
O是观测的序列,例如(S, M, S, L),或者换算为数字(0, 1, 0, 2)
整个马尔科夫过程用图展示如下:
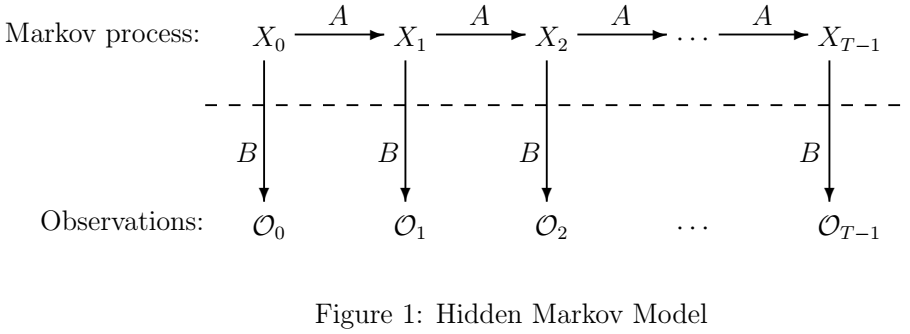
其中Xi代表隐状态,其它的解释如上。隐藏于虚线上方的状态链,即马尔科夫过程,取决于当前状态和A矩阵。我们仅能观测到Oi,它通过B矩阵与隐状态关联起来。
λ= (A, B,π)
那么,一个长度为4的状态链可以写为:
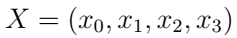
例如:低温,高温,低温,高温。这个是我们最终想要知道的。
与其相对应的观测链如下:
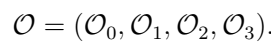
例如:年轮S, 年轮M, 年轮S,年轮L。是我们观测到的
于是,状态x0的概率为πx0。在x0的条件下观测到O0的概率是bx0(O0),从x0转移到x1的概率为ax0,x1。依次类推,最终观测为O,推测为X这种链(例如高温-高温-低温-低温)的概率是:
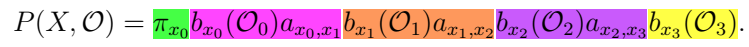
在上面通过年轮推测气温的例子中,观测O=(0,1,0,2),对应(小年轮,中年轮,小年轮,大年轮)。那么高温-高温-低温-低温这种可能的状态链的概率是:
P(HHCC) = 0.6(0.1)(0.7)(0.4)(0.3)(0.7)(0.6)(0.1) = 0.000212
同理,我们可以算出每种可能情况(总的是2^4种可能,有四年,每年两种可能的温度情况),如下表:
其中,normalized probability是这16种可能的状态链的概率归一化之后的结果。
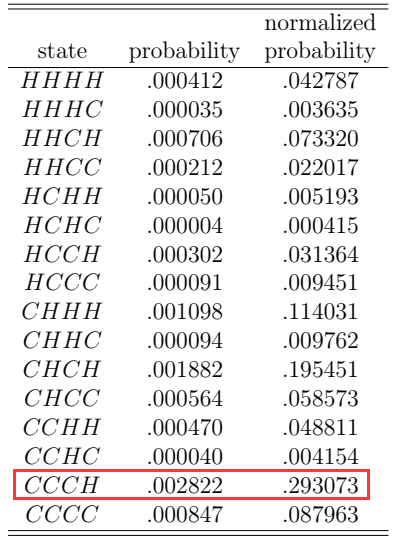
如果是动态规划算法,推测最可能状态链是CCCH,因为其normalized probability最大;如果是隐马尔科夫模型,则计算如下:
1. 先算出上表中所有第一个状态为H的可能性之和,即HHHH,HHHC,HHCH,HHCC,HCHH,HCHC,HCCH,HCCC的normalized probability之和,为0.188182。第一状态为C的可能性之和为1-0.188182=0.811818
2.再依次算出第二个状态,第三个状态和第四个状态的H/C概率,如下表:
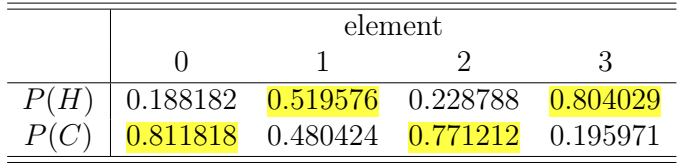
因为链的各个element计算是独立的,这里只需要挑选出每个element概率最大的状态,构成概率最高的状态链,本例中HMM计算出的最可能状态链是CHCH。
注意:两种算法计算出的最可能状态链不同,但是两种状态链都是合理的。
参考文献:
Mark Stamp. A Revealing Introduction to Hidden Markov Models
https://blog.sciencenet.cn/blog-2970729-1188964.html
上一篇:HiCPro安装中的iced问题
下一篇:隐马尔科夫模型简介(二)