博文
歌唱是否有其逻辑原点?——从复杂系统视角重新理解歌唱
||
歌唱是否有其逻辑原点?
——从复杂系统视角重新理解歌唱
马金龙
【导读】
三个值得思考的问题:
❶ 歌唱是“说话加旋律”吗?
如果是,那婴儿的咿呀、劳动号子、戏曲行腔算什么?本文论证:歌唱与语言可能源于共同的原初人声,后来才向不同方向分化。
❷ 为什么有些声音“技术正确”却“不像在唱”?
因为歌唱不是部件的简单相加,而是一个复杂系统的涌现。文章用“动态闭环”模型解释了这一现象,并提供了系统化教学思路。
❸ 群体歌唱为什么比独唱更有感染力?
不只是因为“人多”,而是因为它将个体的呼吸、节拍、情感动态耦合,生成了新的系统层级——共同体本身。本文从复杂系统视角重新理解歌唱,提出“歌唱的逻辑原点在于:人类声音从单纯的信息工具,转化为一种能够承载情感、组织时间、显现身体并生成共同体的形式”。
关键词:歌唱;复杂系统;涌现;动态闭环;声乐教学;共同体
导语
在通常理解中,歌唱属于音乐艺术与声乐教学的范畴,似乎主要是技巧问题。但如果追问“歌唱何以成立”,就会发现,这一问题实际上涉及语言、身体、情感、时间组织乃至复杂系统理论。本文试图讨论:歌唱是否有其逻辑原点?如果有,这个原点是什么?我倾向于认为,歌唱并非语言之后的一种简单修饰,而是人类声音系统在情感表达、身体显现和共同体生成中的一种高阶涌现。
我们通常把歌唱看作一种艺术技能:需要音准、节奏、呼吸、共鸣、咬字和表达。但如果进一步追问:歌唱为什么会出现?歌唱何以成为歌唱?它是否有某种逻辑原点?问题就不再只是声乐技巧问题,而进入了更根本的层面。
这里所说的“逻辑原点”,并不是追问历史上第一首歌出现于何时何地,而是追问:如果歌唱作为一种人类行为能够成立,它最基本的生成根据是什么?换句话说,是什么使得“歌唱”区别于“发声”,又区别于“说话”?
术语说明:本文所说的“逻辑原点”,指的是一个现象得以成立的最小必要条件集合,是使该现象能够从相关现象中分化出来并保持自身特性的核心机制。
我倾向于认为:歌唱是有其逻辑原点的。
而且,这个原点不在乐谱、唱法体系或艺术制度之中,而在于:人类声音从单纯的信息工具,转化为一种能够承载情感、组织时间、显现身体并生成共同体的形式。
一、歌唱不是“说话加旋律”
关于歌唱,一个常见看法是:歌唱不过是说话加上旋律。
但这个定义其实过于简化了。
因为在现实中,我们很早就会遇到许多介于“说”和“唱”之间的人声形式:
· 婴儿的咿呀和拖长音;
· 呼唤、哭诉、哼鸣;
· 祷告、吟诵、号子;
· 民间歌谣、戏曲行腔、说唱、呼麦等。
这说明,歌唱并不是在成熟语言之后才被人为附加上去的装饰。
更合理的看法可能是:歌唱与语言都可能源于原初的人声表达,后来才向不同方向分化。
· 语言越来越趋向符号化、指称化和抽象表达;
· 歌唱则越来越趋向情感强化、时间延展和声音自身的显现。
如果说语言更关心“声音说了什么”,那么歌唱更关心“声音如何让存在被听见。”
这一分化并非绝对的历史事件,而是功能分化的逻辑进程:当人声的主导功能从“指称对象”转向“显现状态”时,歌唱的可能性便被激活。
二、从复杂系统看,歌唱的原点不是某个部件,而是一个动态闭环
传统声乐教学常把歌唱拆成若干部分:呼吸、发声、共鸣、咬字、情感等。
这种拆分当然有教学便利,但它也容易让人误以为:歌唱不过是这些部件的简单加总。
可实际并非如此。
歌唱表现出复杂系统的典型特征:
复杂系统是指由多个相互作用的组成部分构成的系统,其整体行为无法通过简单叠加各部分来预测,而会呈现出涌现、自组织、非线性等特征。
· 多因素耦合;
· 非线性变化;
· 实时反馈;
· 自组织;
· 稳定态与突变并存。
有时一个歌者越用力控制某个局部,整体反而越差;有时只是任务意图或听觉目标稍有变化,声音却会突然贯通。
这些现象都说明:歌唱不是线性的“零件拼装”,而是一个动态生成系统。
因此,如果要追问歌唱的逻辑原点,就不能把它理解为某个单独器官动作,也不能等同于某个音高、某种音色。
更合理的说法是:
歌唱的最小有效生成单元,不是某个局部动作,而是一个“意图—呼吸—发声—反馈”的动态闭环。
也就是说,歌唱最初的成立,不在于“声音发出来了”,而在于:
一个生命体在表达意图中,通过身体动力和声音生成,使自己可被自身与他者听见,并在反馈中实时调节。
这才是歌唱作为行为系统成立的必要条件。
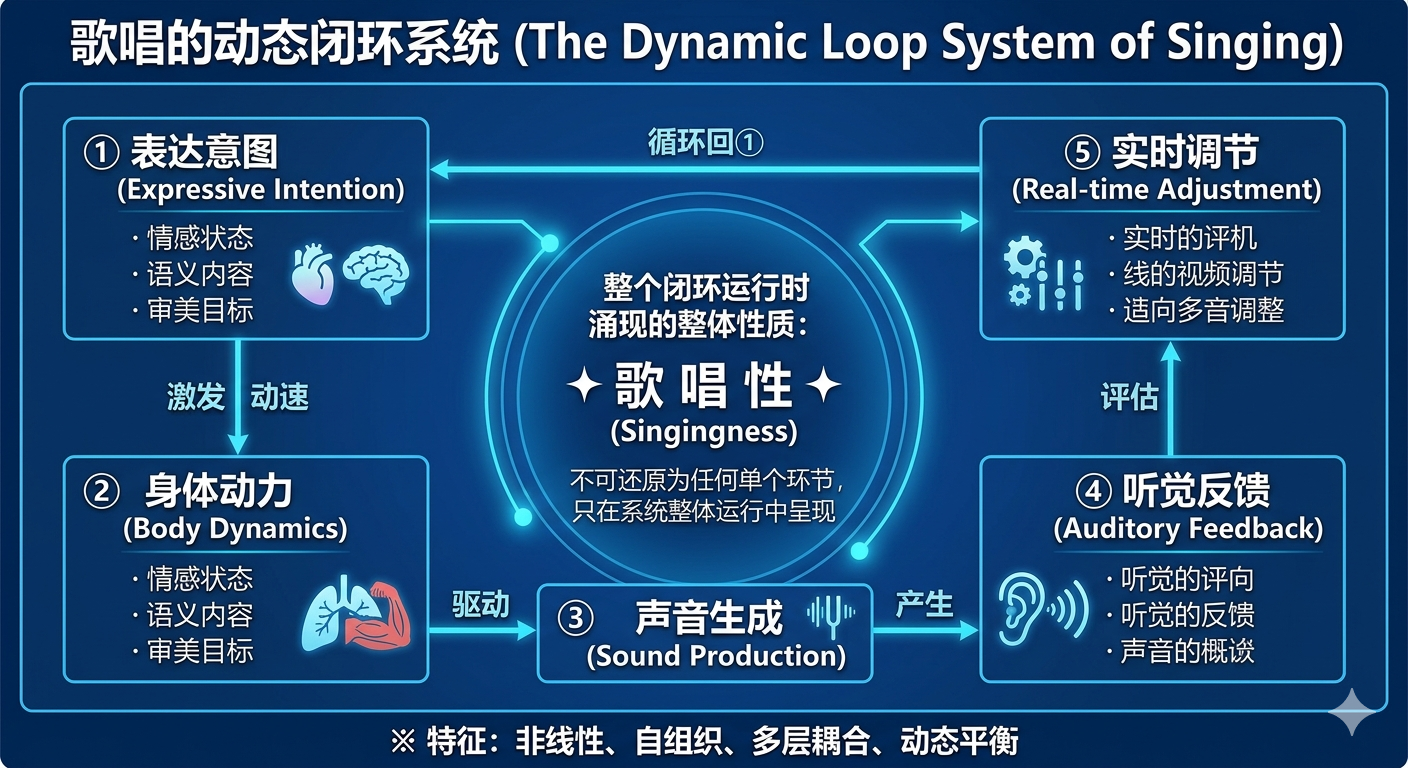
图1:歌唱的动态闭环系统
歌唱不是线性的部件组装,而是由“意图→身体→声音→反馈→调节”构成的自组织循环系统。五个环节实时耦合、相互制约,当系统进入高度协调状态时,“歌唱性”作为整体涌现性质便会显现。这一性质无法在任何单一环节中找到,也无法通过简单相加获得,只能从系统整体运行中生成。
如图1所示,这五个环节构成的不是单向流程,而是持续循环的动态平衡。一个优秀歌者的成长,本质上是这个闭环系统从低效、不稳定状态逐渐进化为高效、自洽状态的过程。
三、歌唱与语言的分道扬镳
“歌唱先于语言还是后于语言”是一个常见问题。
但与其简单争论先后,更值得追问的是:它们究竟在哪里开始分道扬镳?
从发生学和复杂系统角度看,二者的分化主要发生在声音功能的主导原则上:
· 当声音主要服务于清晰指称、稳定符号和抽象组织时,它趋向语言;
· 当声音主要服务于情感显现、时间展开、身体在场和群体共振时,它趋向歌唱。
也就是说,语言让声音逐渐“透明”起来,成为意义传递的通道;歌唱则让声音保持“在场”,使其本身成为经验的一部分。
所以,歌唱的原点不是“音乐附加到语言上”,而是:声音不愿只做工具,而要求自身被保留、被组织、被体验。
这一观点得到了比较音乐学和神经科学研究的部分支持:人类大脑对音乐音高的处理与语言音调的处理存在部分分离,暗示二者可能有独立的进化路径(Peretz & Coltheart, 2003)。明确了歌唱与语言的分化机制后,我们可以进一步追问:当声音选择了“显现状态”这一路径后,“歌唱性”这一独特品质是如何生成的?这就涉及复杂系统中的涌现问题。
四、“歌唱性”不是技术指标,而是一种涌现性质
在教学中经常会遇到这样一种现象:
· 有些声音音准、节奏都对,技术也合规,却总让人觉得“不像在唱”;
· 另一些声音技术未必极端精致,却有一种明显的“成立感”。
这说明,“歌唱性”并不是某个单项指标。
它不等于音准,不等于共鸣,也不等于情感强度。
从复杂系统角度看,歌唱性是一种涌现性质。
涌现(emergence):指复杂系统中,整体层面出现的新性质,这些性质无法在组成部分的层面上找到,也无法通过简单相加得到。
当呼吸、发声、听觉、语言、情感、身体与时间组织进入某种高度协调时,就会出现这样一种整体性质:
· 声音不只是发生,而是成立;
· 时间不只是流逝,而被组织成线条;
· 身体不只是器官动作,而在声音中显现;
· 意义不只通过词语传递,也通过声音本身生成;
· 情感不只是宣泄,而被形式化为可持续、可共享的经验。
换句话说,真正的歌唱,不是若干技术元素的叠加,而是“歌唱性”从人声系统中涌现出来。
这类似于水分子与“流动性”的关系:单个水分子没有流动性,但大量水分子的相互作用会涌现出流动这一整体性质。
五、群体歌唱更接近歌唱的原初逻辑
从歌唱原点的角度看,群体歌唱尤其值得重视。
因为它比个体歌唱更清楚地揭示了歌唱的社会性和共同体性质。
群体歌唱之所以更容易触发强烈情感共振,不只是因为“人数多”,而是因为它将多个个体的呼吸、节拍、音高、注意力和情感状态动态耦合起来,从而生成新的系统层级。此时涌现出来的,已不只是若干个人发声,而是:
· 共同时间;
· 共同呼吸;
· 共同音响;
· 共同情感场;
· 共同体在场。
个体歌唱更偏向“主体显现”;群体歌唱更偏向“共同体生成”。
从劳动号子、祭祀吟唱、宗教圣咏到现代合唱,歌唱长期都不是孤立的个人炫技,而是通过同步呼吸和共同发声,把离散个体组织成一个整体。
它不仅表达共同体,甚至直接生产共同体。
从这个意义上说,群体歌唱可能比现代舞台上的独唱,更接近歌唱的原初生成逻辑。
这一观点在人类学研究中得到支持:许多前文字社会的音乐活动都以群体参与为主,个人独唱往往是后期分化的产物(Blacking, 1973)。
六、“歌唱原点”视角对教学的启示
有人可能会觉得,“歌唱的逻辑原点”过于哲学化。
但恰恰相反,它对歌唱教学和训练有很直接的现实意义。
如果歌唱不是若干部件的加法,而是一个复杂系统中的高阶涌现,那么教学重点就不应只是“纠正局部动作”,而应转向:
· 识别学生当前处于何种发声稳定态;
· 设计任务与条件,使旧习惯失稳;
· 借助反馈、耦合和微扰,引导系统跨越相变点;
· 让新的声音状态成为可持续、可迁移、可自我维持的新稳定态。
在这种视角下,真正好的声音,不是老师临时“帮”学生做出来的声音,而是学生的人声系统开始能够自己生成的声音。
教学案例示例
某学生高音区习惯性喉头上提、声音紧张。传统方法反复要求其“放松喉头”,但越提醒越紧张。
从系统观出发,教师不再直接干预喉部,而是调整其听觉预期(想象声音在前方而非头顶)和呼吸意图(想象气息托住声音而非推挤声音),几次尝试后,喉头自然稳定,声音反而打开。
这体现了系统调节优于局部矫正的原理。
因此,评估一个声音是否真正“唱出来了”,不能只看它当下是否好听,还要看它是否具有:
· 整体成立性;
· 可回归性(学生能否独立再现);
· 可迁移性(能否应用于不同曲目);
· 适应扰动的能力(面对紧张、疲劳等干扰是否稳定);
· 低代偿性(是否需要过度用力);
· 自主再现能力(不依赖外部持续干预)。
这比传统的“对不对、像不像”更接近歌唱的生成本质。
这一方法论与传统声乐教学并非对立关系:传统的部件化训练在建立基础协调时仍然必要,但需要在更高层级上被整合进系统观,避免陷入“见树不见林”的局部优化陷阱。
七、结语:人为什么不满足于发声,而要歌唱?
如果必须用一句话概括,我更愿意这样理解歌唱的逻辑原点:
歌唱是人类为了超越纯粹信息传递,而将情感、身体、时间与共同体组织为可听形式的一种原初冲动。
它不只是音乐文明中的一种技术,也不只是舞台艺术中的表演形式。
它更深地扎根于人的存在结构之中:
当语言不足以承载经验,当情感需要被延展,当身体需要通过声音确认自身,当个体需要与他者进入同一时间——歌唱便出现了。
因此,歌唱的原点,最终触及的是这样一个问题:
人类为什么不满足于“发声”,而要“歌唱”?
也许正是在这里,歌唱显露出它最深的意义:
它使声音超越了纯粹的工具性,而成为生命自身的一种可听见的显现。
延伸思考
本文提出的“歌唱逻辑原点”观点,还可以在以下方向深化:
1. 神经科学视角:歌唱时大脑的整合机制与语言、音乐、情感系统的交互;
2. 跨文化比较:不同文化传统中“歌唱性”的界定差异及其共通的生成机制;
3. 计算建模:能否建立基于复杂系统理论的歌唱生成模型;
4. 教育实践:如何将系统观转化为可操作的教学范式。
这些都值得进一步探讨。
参考文献
[1]Blacking, J. (1973). How Musical Is Man? University of Washington Press.
[2]Peretz, I., & Coltheart, M. (2003). Modularity of music processing. Nature Neuroscience, 6(7), 688-691.
欢迎讨论
读完这篇文章,您有什么思考?欢迎在评论区分享:
1. 您认为还有哪些人类行为具有类似的“逻辑原点”?(如舞蹈、绘画、写作……)
2. 从复杂系统角度看,您所从事的领域有哪些“涌现现象”?
3. 如果您是声乐教师或学习者,“动态闭环”模型对您有何启发?
作者邮箱:963153628@qq.com(如需深入交流)
https://blog.sciencenet.cn/blog-312-1529220.html
上一篇:声乐发声研究:知识碎片化已久,复杂系统理论能否实现范式突破?
下一篇:为什么AI歌声能打动人,却未必“拥有情感”?
