博文
“以火攻火”——使用大型语言模型(LLMs)对抗LLM幻觉
|
“以火攻火”——使用大型语言模型(LLMs)对抗LLM幻觉
通过将一个LLM的输出分组为语义相似的集群,可以减少其产生的错误数量。值得注意的是,这项任务可以由第二个LLM执行,而该方法的有效性可由第三个LLM评估。
由大型语言模型(LLMs)驱动的文本生成系统受到了忙碌的高管和程序员的热烈欢迎,因为它们通过自然的对话界面提供了对广泛知识的轻松访问。科学家也被吸引去使用和评估LLMs——在药物发现、材料设计以及证明数学定理中找到了它们的应用。这类用途的一个关键问题是“幻觉”问题,即LLM对一个问题(或提示)的回答看似是一个合理的答案,但实际上是事实错误或不相关的。幻觉产生的频率以及在何种情况下产生仍有待确定,但很明显它们经常发生,如果不被检测出来,可能会导致错误甚至伤害。在《自然》杂志上的一篇论文中,Farquhar等人通过开发一种检测特定子类幻觉的方法来解决这个问题,这种幻觉被称为虚构。
虚构是一种由于与提示无关的内部因素而不可预测地从LLM中出现的幻觉。作者专注于测量LLM对提示的响应的不确定性,使用的假设是高不确定性表明了虚构。他们通过计算一个称为熵的量来估计这种不确定性,这可以被看作是模型生成的可能输出的随机性。然而,Farquhar等人在意义的层面上而非单词层面上测量了不确定性——通过设计一种基于LLM确定的相似性的“语义”熵度量。然后,他们使用第三个LLM来评估响应的准确性。简而言之,他们的方法相当于以火攻火:作者提出,LLMs可以成为控制LLMs策略的一个组成部分。
使用统计语言模型捕捉意义的想法并不新鲜。1957年,英国语言学家John Firth声称,“你可以通过它所保持的公司来认识一个词”,这激发了一系列旨在通过共享上下文的表示来近似意义的计算语言学研究。这一研究的一个分支将句子视为单词(行)和上下文(列)的数学矩阵,使得可以根据它们在“语义空间”中的距离来确定两个词之间的相似度。这项工作进而导致了现代词汇知识表示模型的发展,最终促成了OpenAI的ChatGPT和Google DeepMind的Gemini背后的LLMs。
LLMs的有效性源于对数十亿个例句、段落和文档中共现词汇的建模,以及高保真地捕捉这些词汇如何组合在一起的统计模式。这些模型提供了计算语义关系的数学工具。关于这些模型是否真正捕捉到意义或在任何认识论或认知意义上理解语言存在很多争议,鉴于它们缺乏对交际意图的意识或与现实世界对象和影响的联系。
然而,很明显这些模型在一系列涉及某种理解的复杂语言处理任务中表现良好。其中一个任务是文本蕴含,即一个人或模型确定是否可以从一个陈述中推断出另一个陈述。例如,文本“Pat购买了一辆车”意味着“Pat拥有一辆车”这个短语是正确的,而文本“Pat乘坐了一辆车”则不是。
Farquhar等人利用LLMs识别蕴含的能力来检测虚构。为此,作者取了一个LLM的输出,并将其输入到第二个负责计算“语义等价”——确定两个陈述是否相互蕴含的LLM中(图1)。第二个LLM本质上检测了同义替换,并返回了包含来自第一个LLM的语义等价输出的一组集群。Farquhar等人展示了与这些集群相关的不确定性(语义熵)是第一个LLM不确定性的一个更有效的估计,比标准的基于单词的熵更有效。这意味着即使第二个LLM对语义等价的计算不是完美的,它仍然是有帮助的。
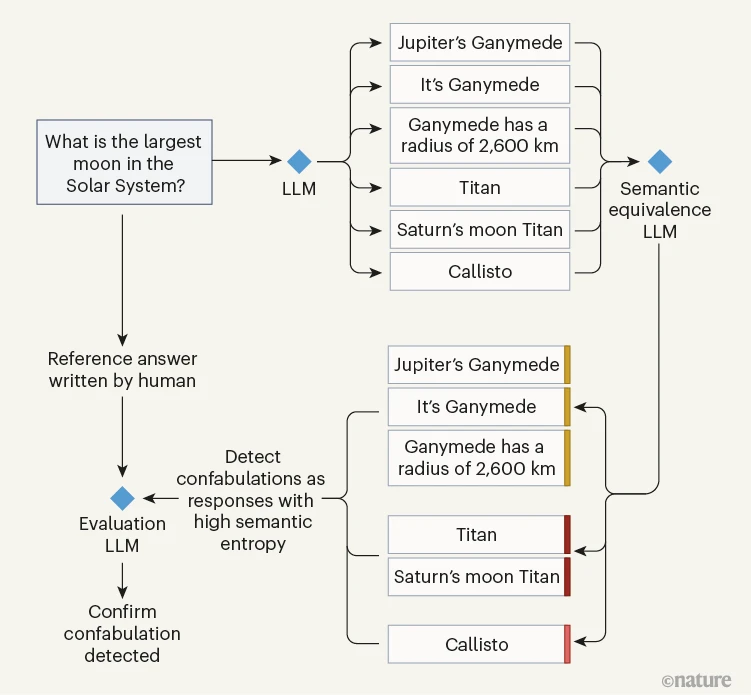
图1 | 检测LLM虚构的策略。大型语言模型(LLMs)可能会产生虚构,这是一种事实上不正确的输出类型。Farquhar等人开发了一种使用LLMs来检测此类错误的方法。一个LLM产生了待评估的输出。作者使用了第二个“语义等价”LLM,根据第一个LLM产生的可能输出的语义相似性对其进行分组,然后计算了一个称为语义熵的不确定性度量,以识别似乎为虚构的响应。通过将第一个LLM的响应与人类编写的参考答案进行比较以确定其正确性,第三个LLM被用来评估该方法的有效性。
作者通过使用第三个LLM来判断第一个LLM的响应是否与由人类编写的参考答案匹配,从而评估了他们的方法。该团队通过进行实验表明这是一个合理的评估策略,在实验中要求人类判断100对模型输出和人类答案的等价性。实验结果表明,两个人类之间的相互一致程度大致与他们与GPT-4的一致程度相同。尽管如此,依赖于这种基于LLM的方法凸显了在意义等价层面上评估自然语言处理系统性能的一个更广泛挑战。
传统的文本比较指标(例如,那些用于机器翻译任务的指标)很容易失败,并且对词汇选择敏感。它们与人类关于文本等价性的直觉只有微弱的对应关系。有效评估系统输出与参考答案匹配程度本身需要测量意义层面的等价性而非单词层面的匹配,这正是Farquar等人成功做到的。然而,使用LLM来评估基于LLM的方法似乎有些循环论证,可能会有偏见。
检测虚构的任务与其他正在积极研究的问题有关,包括在学术诚信的背景下检测LLM生成的内容,以及通过改写现有文本来检测剽窃。它还与旨在揭露错误信息的研究有关,如假新闻或涉及为欺骗目的故意创建虚假内容的信息操纵。人们可以使用LLM通过精心规划的提示策略来创建重新措辞、误导性或捏造的内容。尽管这与驱动虚构的那种内部模型不确定性不同,但探索Farquhar及其同事的语义熵度量是否也可以用来解决这个问题将是有趣的。
通过进一步实验LLM的集成体,还可以改善LLM输出的鲁棒性,通过有针对性地部署单个LLM来评估输出的特定方面。在这个过程中,研究人员将需要解决这种方法是否真正控制了LLM的输出,或是否无意中通过叠加多个容易产生幻觉和不可预测错误的系统而助长了问题。
https://blog.sciencenet.cn/blog-41174-1439346.html
上一篇:150年的困惑,鱼类听觉的解决方案《自然》
下一篇:GLP-1激动剂提高生育能力?
