博文
AI需要向人类婴儿学习学习
|
AI需要向人类婴儿学习学习
人工智能本质是机器的学习能力,但人类的学习能力是非常高效的,特别是人类婴儿在语言等方面的学习能力,可能需要好好研究。如果能掌握了这种能力,AI在学习效率方面可能会有一个巨大的进步。
人工智能 (AI) 的当前进展似乎正在将科学转变为科幻小说,因为大数据机器学习模型正在接近并在某些方面超越了人类的能力。但这样的模型是在大量数据上训练的。Vong 等人1通过使用一个婴儿的 61 小时真实生活经历来展示多模态学习模型的效率,代表人类提出了挑战。
Can lessons from infants solve the problems of data-greedy AI? (nature.com)
训练数据由头戴式摄像头捕获,作为 6 个月至 25 个月大之间的多个简短样本。这是语言学习开始时词汇量快速扩展的时期。来自头部摄像头的视频片段和成年人与婴儿交谈的记录被输入到作者的模型中,该模型使用“对比”方法进行视觉和语言学习。
对比学习是机器学习中广泛使用的方法2.它涉及将成对的训练样本输入到算法中,并带有一个标签,指示两个样本的相似性。两个项目属于同一类别的证据会改变模型参数,使这些项目在所有配对的学习表示空间中更加相似。相反的证据会改变模型参数,这些参数定义了将项目分开的空间。
Vong及其同事的模型将对比表征学习与联想学习相结合,即话语和图像之间的学习联系。它通过使用一种模态中的学习表征作为另一种模态的教学信号(用于增加或减少对的相似性)来做到这一点。这样,由于文本和图像的共现,学习是自我监督的。这是诺贝尔奖获得者杰拉尔德·埃德尔曼(Gerald Edelman)首次提出的跨不同神经系统(例如大脑的视觉和语言处理部分)的双向学习信号交换的一种形式3并称为重新进入。
重入信号是一种潜在的强大自监督学习形式,因为来自一个神经系统的教学信号会随着另一个系统驱动的学习而变化(图 1)。由于不同表征组件的同时协调,具有再入的多模态模型可以快速学习,正如 Vong 及其同事的模型所证明的那样。
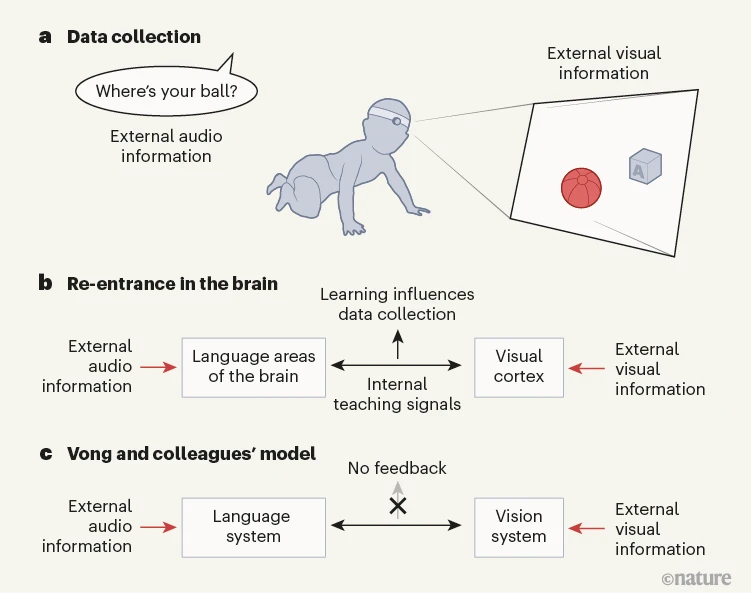
图 1 |自我监督学习。 a, Vong 等人使用一个戴着传感器的婴儿日常生活中的音频和视频记录来训练人工智能模型来学习语言。图像和文字的并存使训练过程成为“自我监督”,这意味着它只需要内部教学信号。b,这让人想起重新进入,这是不同神经系统之间教学信号的不断交换,例如视觉系统和语言发展的大脑区域。重新进入允许大脑通过主动选择和创建感觉事件来收集与其当前学习状态相关的数据。c,作者的模型不包括这种反馈,但他们的模型使用的数据可能仍然反映了婴儿生成的数据结构的某些属性,这些属性有利于模型的学习能力。
婴儿的日常经历对于任何学习算法来说都是具有挑战性的。众所周知,对象和同时出现的单词会产生嘈杂的数据,从而导致许多虚假配对4.此外,儿童听到的语言中物体名称的存在非常稀少。例如,“篮子”这个词(25个月大之前的孩子就能理解)在一个600万字的语料库中只出现了8次5父母在与孩子交谈时使用的语言。尽管如此,幼儿学习对象名称并立即将这些名称推广到以前从未见过的实例。作者的模型是用以儿童为中心的数据训练的,也做了同样的事情。模型的重新进入为解释婴儿的快速学习和泛化提供了潜在的理论路径。
Vong 等人将他们的贡献描述为证明可以从少量稀疏和嘈杂的训练数据中学习对象名称和视觉类别。当然,婴儿已经提供了这个证明。关键问题是作者的模型告诉我们如何实现这一点。该模型的成功很可能反映了可重入信号的计算能力,尽管尚未证明这一点。我认为该模型的成功也可能取决于婴儿佩戴的头部摄像头拍摄的图像的时间和空间统计数据;这也尚未确定。其他研究表明,使用婴儿以自我为中心的图像进行训练优于使用其他数据集进行训练,包括以成人自我为中心的体验6,7.
人类发育科学领域越来越多的工作使用可穿戴传感器在日常生活的规模上捕捉和量化婴儿和儿童体验的统计数据8.这项研究不是从人工智能的角度进行的,但人工智能研究人员关注可能是明智的。儿童真实世界经历的统计数据有一些有趣的方面7,9包括由运动发展和学习本身的进步创造的有序的经验课程。此外,婴儿实例化了爱德曼的完整再入模型。在每一刻,孩子们都会从他们看的地方、他们触摸的东西和他们所做的事情中选择、引出和创造多模态输入。这种选择取决于多模态神经系统中的瞬时激活表征,将即时数据样本与学习者的当前内部状态联系起来10.
所有学习系统的核心问题是,在庞大而复杂的模型参数空间中,学习者如何找到最佳或接近最优的解决方案。大数据模型的运行假设是,给定足够的数据,足够强大的学习者将找到最佳解决方案;在模型有权访问所有数据的限制中,这可能是真的。然而,在实践中,有许多类别的学习问题没有足够的数据、没有足够的时间或没有足够的计算能力。
在婴儿中显而易见的高效学习可能是自然经验的多模态统计和婴儿积极参与这些数据收集的直接结果。这是一个猜想:即使是像Vong及其同事的模型这样的被动学习者也可能从以婴儿自我为中心的训练数据中受益,因为多模态统计限制了搜索路径。如果是这样的话,数据贪婪的人工智能的许多问题可以通过确定并利用婴儿经验的自然统计数据来缓解。
Grounded language acquisition through the eyes and ears of a single child | Science
论文摘要:从大约 6 到 9 个月大开始,孩子们开始习得他们的第一个单词,将口语与视觉对应物联系起来。这些知识中有多少是从具有相对通用学习机制的感官输入中学习的,有多少需要更强的归纳偏见?使用一名 6 至 25 个月大儿童的纵向头戴式摄像机记录,我们在 61 小时的相关视觉语言数据流上训练了一个相对通用的神经网络,学习了基于特征的表示和跨模态关联。我们的模型获取了儿童日常经验中存在的许多单词指涉映射,实现了对新视觉指涉的零样本泛化,并调整了其视觉和语言概念系统。这些结果表明,通过一个孩子的输入,如何通过联合表征和联想学习来学习扎根词义的关键方面。
编辑看法:幼儿如何学会将新单词与特定对象或视觉表示的概念联系起来?这个在早期语言习得中引起激烈争论的问题传统上是在实验室中研究的,将可推广性限制在现实世界中。Vong 等人。以前所未有的纵向方式调查了这个问题,使用来自一个孩子在自然主义环境中的第一人称经历的头戴式视频记录。通过应用机器学习,他们引入了儿童对比学习视图(CVCL)模型,将与说出的单词同时出现的视频帧配对,并将图像和单词嵌入到共享的表征空间中。CVCL 表示从一个概念(例如,谜题)到不同的子集群(动物与字母谜题)的视觉相似事物的集合。它结合了联想和表征学习,填补了语言习得研究和理论的空白。
https://blog.sciencenet.cn/blog-41174-1425910.html
上一篇:高压氧对心血管的效应
下一篇:人工智能时代,优先考虑人类能动性
