博文
文本挖掘实践小体会(二)
||
说到文本挖掘,python是不得不提的部分,python有一个自然语言工具包叫gensim,里面实现了很多功能如去停用词、词干提取、词性标注,同时可以很方便地将文档转化为向量,同时它也实现了LDA、LSA、TF_IDF等模型,确实是文本挖掘的利器,不过遗憾的是,我对python不熟,虽然我不认为学习一门计算机语言需要多长时间,但gensim依赖于NumPy和SciPy两大科学计算工具包开发,这两个工具包里的数据结构,我一时半会没摸透,外加赶毕业论文时间紧迫,对gensim的使用仅仅停留在跑了一遍演示代码,以后再没使用。直到上周,无疑中看到python调用Java的![]() 5种方法,我忍不住心怀好奇,干嘛不用Java调用gensim函数,实现文本挖掘?或者更进一步,做一个文本挖掘软件,使用Java做一个界面,底层分析使用gensim,以后分析文本直接点击下按键即可?这件事情可以做,只是我生性懒散,没到时间节点绝不轻易动手,这个软件年底能否完工?
5种方法,我忍不住心怀好奇,干嘛不用Java调用gensim函数,实现文本挖掘?或者更进一步,做一个文本挖掘软件,使用Java做一个界面,底层分析使用gensim,以后分析文本直接点击下按键即可?这件事情可以做,只是我生性懒散,没到时间节点绝不轻易动手,这个软件年底能否完工?
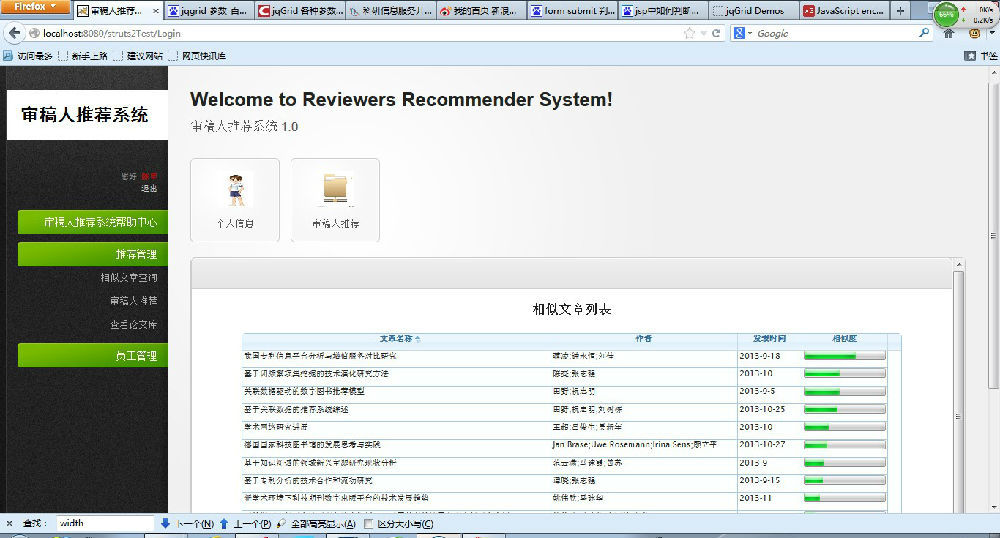
再说下文本挖掘的降维、相似度计算等操作。去年9月份国家科学图书馆举办了一届开放创新大赛,要求基于公开的科研数据做应用软件,我做了一个基于LSI模型的期刊审稿人推荐系统,做这个系统出发点就是,根据审稿人之前发表的文章内容以及文章被引频次,判断这个审稿人的研究领域和学术造诣,当编辑部新接到一篇文章后,该系统计算下这篇文章和各个审稿人熟悉领域的相似度,然后创建一个基于相似度和审稿人文章被引频次的综合指标,计算这篇文章与各个审稿人的匹配度。做法也很简单,编写LSI模型代码,创建匹配度指标等等。平台测试时候,我从国家科学图书馆机构知识库中爬取将近4000份论文,占用大约2G存储空间。接下来就是训练模型了,这中间有两处并不好搞,所谓不好搞是说内存易溢出且耗费时间,第一是关键词抽取,具体原因见前文,第二是文档_关键词矩阵的SVD拆分,我将关键词再三精简,最终得到矩阵的规模 [29676][3893],仅仅这个矩阵(double类型)就占用800多兆内存,再加上其他开销,一跑程序必然内存溢出,另外是SVD拆分,我先拆分了个1万*800的矩阵,耗时将近1个小时,按照谷歌搜索结果,SVD拆分的时间复杂度是n^3,也就是说,我想拆分[29676][3893]矩阵需要照着3375个小时做打算,哦对了,我使用Jama包进行SVD拆分,后来一个师弟说用matlab就会很快,其实我之前试过,时间相差不大。
由此我想到LSI模型的升级版本PLSI,它使用概率的方法获取潜在语义空间,也即主题,或者说SVD拆分(X = UDV')中的V',在国内学者赞赏PLSI方法诸多先进之处时,我觉得这种方法最直接的贡献在于运算量减少,它让在一台笔记本上进行主题分析变得可行,不过虽然说它大大降低了计算量,但其实PLSI以及它的升级版本LDA的运算量并不小。另外关于PLSI方法,虽然我看完几篇论文后对外表示看懂了,但顶不住周围人三句问,这种算法的东西,终究还需要自己实现一遍,至少过一遍代码,才能了解的更深入一些,至少对我是这样。so三个月前,我决定重写一遍PLSA代码,不过生性懒散,现在还没开始。
https://blog.sciencenet.cn/blog-724521-809722.html
上一篇:文本挖掘实践小体会(一)
下一篇:我什么时候能摇到北京车号?