博文
《金融时间序列预测》:第2章:金融时间序列的R表示
||
【下面是Word粘贴过来的内容】
第2章 金融时间序列的R表示
时间序列(Timeseries)是指将某种现象某一个统计指标在不同时间上的各个数值,按时间先后顺序排列而形成的序列。
时间序列分析(Timeseries analysis)是一种动态数据处理的统计方法。该方法基于随机过程理论和数理统计学方法,研究随机数据序列所遵从的统计规律,以用于解决实际问题。在第二次世界大战前,多用于经济预测。二次大战中和战后,在军事科学、空间科学、气象预报和工业自动化等部门的应用更加广泛。
本章介绍时间序列数据在R中的基本表示、处理及可视化方法,为后继的金融时间序列预测计算做准备。
时间序列数据是按时间排序的数据采样。作为一个简单的例子,我们先来看看比特币生产数量的变化。
【附注:】
如果您不太清楚比特币,这里附一个百度百科的简单说明:
比特币(BitCoin)的概念最初由中本聪在2009年提出,根据中本聪的思路设计发布的开源软件以及建构其上的P2P网络。比特币是一种P2P形式的数字货币。点对点的传输意味着一个去中心化的支付系统。
再来一段八卦:
比特币的开发者兼创始者,是一位1949年出生的日裔美国人。他爱好收集火车模型,职业生涯中有多处保密,曾为大型企业还有美工军方执行保密的工作。2008年中本聪在互联网上一个讨论信息加密的邮件组中发表了一篇文章,勾画了比特币系统的基本框架。2009年他为该系统建立了一个开放源代码项目(opensource project),正式宣告了比特币的诞生。2010年12月12日当比特币渐成气候时,他却悄然离去,从互联网上销声匿迹。
有多种方法可以从数据源输入时间序列数据给我们使用。最基本的方法是从硬盘的文件里读出。例如,假设我们的数据文件名为“比特币生产数目TOUTV.csv”,其内容为从09年1月开始到13年10月的比特币生产数目,用表格的形式表示为:
表格2‑1比特币生产数目
Date | Value |
2013/10/22 | 1159699 |
2013/10/21 | 979061.4 |
2013/10/20 | 691056.5 |
2013/10/19 | 1066913 |
2013/10/18 | 880504.6 |
2013/10/17 | 912009.4 |
2013/10/16 | 1024516 |
上面的表格仅仅列出了最开始的几行,后面的数据都省略了。这是一个CSV文件,即“逗号分隔的值(comma-separatedvalues)”,其形式为:
Date,Value
2013-10-22,1159699.0084891
2013-10-21,979061.3851226
2013-10-20,691056.4816408
2013-10-19,1066912.8245079
2013-10-18,880504.60423908
对于CSV格式的数据文件,最简单的数据输入方法是使用read.csv()函数(假设我们的数据文件保存在E盘根目录下):
> x=read.csv("E:/比特币生产数目TOUTV.csv")
> x
Date Value
1 2013-10-22 1159699.0
2 2013-10-21 979061.4
3 2013-10-20 691056.5
4 2013-10-19 1066912.8
5 2013-10-18 880504.6
……
1749 2009-01-04 0.00
1750 2009-01-03 50.00
很显然,read.csv()函数根据给定的CSV文件的结构,和第一行的标题,将数据按两列读入,第一列的名字就是“Date”,第二列的名字为“Value”。两列数据构成一个矩形的数据结构,这种数据结构在R语言里面被称之为“数据框”(dataframe);我们可以通过数据框名和列名来引用某个单独的列,例如,x$Date可代表第一列,x$Value代表第二列;参见下面的例释:
> x$Date
[1] 2013-10-22 2013-10-21 2013-10-202013-10-19 2013-10-18
[6] 2013-10-17 2013-10-16 2013-10-152013-10-14 2013-10-13
……
[1746] 2009-01-072009-01-06 2009-01-05 2009-01-04 2009-01-03
1750 Levels:2009-01-03 2009-01-04 2009-01-05 ... 2013-10-22
> x$Value
[1] 1159699.01 979061.39 691056.48 1066912.82
[5] 880504.60 912009.37 1024516.32 822209.77
……
[1745] 0.00 0.00 0.00 0.00
[1749] 0.00 50.00
我们将在下一节再详细讨论数据框,现在只需要知道这么多就可以了。如果希望将比特币生产数目随时间的数量变化绘制成图形,可以输入下面命令:
> plot(x$Value,type="l", ylab="", xlab="")
可以注意到,上面的指令中多了以前没有见过的两个参数:xlab和ylab;这两个参数实际上很容易理解,他们分别是x轴和y轴的文本标签。因为这个图比较大,加上标签以后更难以在一张页面上显示清楚,所以我们将这两个参数置为空(即"")。绘图的效果参见图表2‑1。
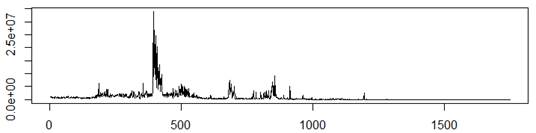
图表2‑1比特币的生产数量
出了从本地文件系统(例如硬盘)中读取数据外,也可以直接从Internet上面读取。例如,我们还将上面的数据文件放到了Google Code里面,因此,可以从Google Code的项目库中直接读取:
>y=read.csv("https://r-finance-forecast-practice-book.googlecode.com/svn/TOUTV.csv")
其结果是完全一样的。当然,你必须保证能访问Google Code——这可能不是在所有时刻都有效的;在你不能访问Google的时候,你会得到类似下面的错误信息:
Error in file(file,"rt") : cannot open the connection
In addition: Warningmessage:
In file(file,"rt") : InternetOpenUrl failed: '无法与服务器建立连接'
实际上,除了read.csv()外,R还有其它几个类似的函数用于从文本格式的数据文件中读取数据。在R的控制台(console)窗口,键入?read.csv,即可获得关于这类函数的帮助。这几个类似的函数包括:
read.csv(file, header= TRUE, sep = ",", quote = "\"",
dec = ".", fill = TRUE,comment.char = "", ...)
read.csv2(file, header= TRUE, sep = ";", quote = "\"",
dec = ",", fill = TRUE,comment.char = "", ...)
read.delim(file,header = TRUE, sep = "\t", quote = "\"",
dec = ".", fill = TRUE,comment.char = "", ...)
read.delim2(file,header = TRUE, sep = "\t", quote = "\"",
dec = ",", fill = TRUE,comment.char = "", ...)
观察一下这几个函数的异同,我们可以发现,他们的差别仅仅在于默认的数据分隔符、小数点符号不同,其它参数都相同。实际使用中,可以根据数据文件的具体格式选用。实际上,也可以使用其中一种代替其它的函数,只要明确传递特定的参数即可。例如,带sep函数的read.csv(file,sep= ";", …),指定使用分号做数据分隔符,等同于不带sep参数的read.csv2(file,…)。
最后,我们看看互联网时代的R包还可以做些什么。
有一个用于量化投资的R包,叫做quantmod;安装和加载quantmod的过程如下:
>install.packages("quantmod", lib="D:/Program Files/R/R-3.0.1/library")
trying URL'http://cran.rstudio.com/bin/windows/contrib/3.0/quantmod_0.4-0.zip'
Content type'application/zip' length 443166 bytes (432 Kb)
opened URL
downloaded 432 Kb
package ‘quantmod’successfully unpacked and MD5 sums checked
……
>library("quantmod")
Version 0.4-0 includednew data defaults. See ?getSymbols.
Warning message:
程辑包‘quantmod’是用R版本3.0.3来建造的
上面指令信息中,install.packages()命令用于安装quantmod,而library()指令用于将quantmod调入内存。顺便说一句,上面信息中的“程辑包”就是R包,不知道为什么负责R汉化信息的人会发明这样一个“奇特新名字”。
好了,quantmod加载以后,我们就可以是使用getSymbols()函数了。
注意——现在是见证奇迹的时刻了:
>getSymbols("TSLA")
[1] "TSLA"
> TSLA
TSLA.Open TSLA.High TSLA.LowTSLA.Close TSLA.Volume TSLA.Adjusted
2010-06-29 19.00 25.00 17.54 23.89 18766300 23.89
2010-06-30 25.79 30.42 23.30 23.83 17187100 23.83
2010-07-01 25.00 25.92 20.27 21.96 8218800 21.96
……
2014-07-15 226.73 227.65 218.10 219.58 5718500 219.58
2014-07-16 221.82 224.80 216.82 217.16 4044500 217.16
2014-07-17 216.16 220.55 213.60 215.40 4649400 215.40
这就是大名鼎鼎的特斯拉电动车的股票数据!
然后另一个简单指令就可以绘制出它的开盘价的走势图:
>plot(TSLA$TSLA.Open)
绘图效果参见图表2‑2。
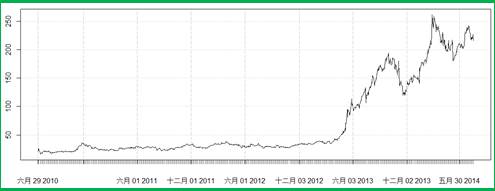
图表2‑2特斯拉电动车股票数据
R包quantmod用于快速的量化投资模型的建立和测算。感兴趣的读者可进一步参考http://www.quantmod.com/,我们在本书的最后(第12章:
R量化投资初步)也会给出一个简要的介绍,等不及的读者可以直接跳到最后阅读。
前面说到,使用read.csv()函数从CSV文件读入的矩形数据结构,在R中被称之为“数据框”(data.frame),可以使用类似矩阵的方式访问其中的元素。因为数据框是R中的一种非常重要的数据类型,因此在本章我们要对数据框做更为详细的说明。
为了说清楚数据框,首先要了解R中的“列表”(list)数据类型。
列表是一个对象集合,其元素由序号(下标)区分,各元素的类型可以是任意类型的数据对象,甚至可以是另一个列表。列表可以使用list()函数构造,例如:
> rec <-list(name="李明", age=20,scores=c(85, 76, 90) )
> rec
$name
[1] "李明"
$age
[1] 20
$scores
[1] 85 76 90
> rec$age #使用名称引用
[1] 20
> rec$scores
[1] 85 76 90
> rec[1] #使用下标引用,返回一个子列表(注意啊!)
$name
[1] "李明"
> rec[[3]] #使用双重下标引用,返回元素值
[1] 85 76 90
在上面的例子里面,名为rec的列表包含三个元素,分别命名为“name”、“age”和“scores”;我们可以通过元素的名字来引用它(例如rec$name),也可以使用“列表名[[下标]]”的格式引用(例如rec[[1]])。
注意:上面没有写错哦,是双重方括号。
我们可以使用下面的指令来判断一下rec$name和rec[[1]]是否真的“等同”:
>rec[[1]]==rec$name
[1] TRUE
上面指令中,“==”(两个等号哟)是一个比较运算,表示我们要求R比较一下两边的值。R的输出结果为“真”(TRUE),即两种表示是有相同的值的。
有时候我们可能会混用两种表示方式;例如:
> rec[[3]][2] #取出第3个元素(是一个向量)里面的第二个值
[1] 76
> rec[["scores"]][2]#取出score元素中的第2个值
[1] 76
在上面最后的例子中,我们使用元素名代替双方括号内的下标值;而最后的[2]则表示,在rec[["scores"]]这个元素(它又是一个包含三个元素的向量)中取出第二个元素。
注意:列表数据和“向量”类型的数据有所不同的是,引用列表元素时不能使用范围下标,即不能单次引用多个元素;例如,下面的写法是不对的:
> rec[[1:2]]
Error in rec[[1:2]] :subscript out of bounds
有读者可能会争辩道:我试了试rec[1:2]的写法,也是可以的啊!见下:
> rec[1:2]
$name
[1] "李明"
$age
[1] 20
正确的解释是:
单重方括号的含义和双重方括号完全不同:双重方括号是“取出列表其中某个元素”,其结果的数据类型和被取出的元素一致;单重方括号的意义是“取出一个子列表”,其数据类型仍为“list”。
R是一种非常灵活的语言;这个特点在列表上也有很突出的体现。例如:在不引起歧义的时候,可以使用简化的元素名来引用一个元素:
> rec$score
[1] 85 76 90
> rec$sc
[1] 85 76 90
> rec$s
[1] 85 76 90
> rec$s==rec$scores
[1] TRUE TRUE TRUE
当然,在写R脚本程序的时候,还是不建议大家这样来简化,因为这样做虽然减少了几次敲键,但是降低了程序的可读性,不是一个好习惯。
列表处理的灵活性还体现在:你可以随心所欲地对元素重新赋值,或者扩充:
> rec$age=22
>rec$sex="Female"
> rec
$name
[1] "李明"
$age
[1] 22
$scores
[1] 85 76 90
$sex
[1] "Female"
上面第一条指令修改了age元素,第二条指令新增了一个名为“sex”的元素。
多个list对象还可以使用c()函数连接起来构成一个新的列表;例如,下面的指令取出rec的一个子列表,然后和另一个只有一个元素的列表合并,赋值到一个新的变量:
> d = c(rec[2],list(qq=33221122))
> d
$age
[1] 22
[1] 33221122
有了列表的基础知识,我们就可以开始详细讲解数据框了。
数据框是R语言中类似矩阵的一种数据结构,但矩阵的各列可以是不同类型的数据。数据框的每列是一个变量,每行是一个观测,像极了我们最最常见的“成绩单”。
数据框可以用data.frame()函数生成,其用法与list()函数相同。例如:
> staff <-data.frame(name=c("张三", "李四","王五"), age=c(21, 24,20),height=c(181, 167, 176))
> staff
name age height
1 张三 21 181
2 李四 24 167
3 王五 20 176
上面是一个有3列(即3个变量)的数据框。
换一个比较规范的说法是:数据框是一种特殊的列表对象,各列表成员必须是向量(数值型、字符型、逻辑型)、因子、数值型矩阵、列表,或其它数据框,其中:
n 向量、因子成员为数据框提供一个变量;
u 如果向量不是数值型的,则会被强制转换为因子;
n 矩阵、列表、数据框这样的成员为新数据框提供了和其列数、成员数、变量数相同个数的变量。
n 作为数据框变量的向量、因子或矩阵必须具有相同的长度(行数)。
上面提到的数据类型中,“因子”(factor)表示分类变量,不能用来计算而只能用来分类或者计数;在以后用到的时候我们在做更具体的讲解。
对上面这些教条我们现在不作过多解释(有点诘屈聱牙);一般可以把数据框看作是一种推广了的矩阵,它可以用矩阵形式显示,也可以用对矩阵的下标引用的方法来引用其元素或子集。下面是对数据框的变量(列)的引用的两种形式(别忘了数据框是一个列表):
> staff[[1]]
[1] 张三李四王五
Levels: 李四王五张三
> class(staff[[1]])
[1] "factor"
> staff$name
[1] 张三李四王五
Levels: 李四王五张三
> staff[[2]]
[1] 21 24 20
> class(staff[[2]])
> staff$age
[1] 21 24 20
上面我们使用class()函数来显示参数的数据类型。
如果使用单括号,则取出的数据类型是一个子数据框:
> staff[1]
name
1 张三
2 李四
3 王五
> class(staff[1])
[1]"data.frame"
> staff[2]
age
1 21
2 24
3 20
> class(staff[2])
[1]"data.frame"
如果使用双下标的形式,表示我们要取出数据框中的单个矩阵元素,下标引用方法和数学里面的矩阵元素下标一样,是“[行,列]”的形式。
> staff[2,1]
[1] 李四
Levels: 李四王五张三
> class(staff[2,1])
[1] "factor"
> staff[2,2]
[1] 24
> class(staff[2,2])
[1]"numeric"
> staff[2,3]
[1] 167
> class(staff[2,3])
[1]"numeric"
我们还可以在单括号内使用范围型坐标;仔细读读下面的例子,看看范围型坐标是如何定为数据元素的区域的:
> staff
name age height
1 张三 21 181
2 李四 24 167
3 王五 20 176
> staff[1:2, 2:3]
age height
1 21 181
2 24 167
>class(staff[1:2,2:3])
[1]"data.frame"
最后,我们要说说数据框的“变量名”和“行名”。变量名就是列名,由属性names定义,此属性一定是非空的。行名用rownames属性定义。如:
> names(staff)
[1]"name" "age" "height"
> rownames(staff)
[1] "1""2" "3"
数据框的主要用途是保存数据分析建模所需要的数据,因此有着特殊的重要性。在使用数据框的变量时,虽然我们可以使用“数据框名$变量名”的记法,但是,这样使用比较麻烦,R语言提供了attach()函数可以把数据框“连接”到当前的名字空间(namespace,即数据变量存储区)内,以方便对数据框变量的引用;例如:
> attach(staff)
> age
[1] 21 24 20
> c=age+10
> c
[1] 31 34 30
上面的例子中,由于staff已经连接入当前的名字空间,因此可以通过age直接引用其age变量。
如果我们还希望扩充数据框,和对列表的处理方式一样,可以直接对要新增的变量(列)赋值即可:
> staff$futureAge=c
> staff
name age height futureAge
1 张三 21 181 31
2 李四 24 167 34
3 王五 20 176 30
如果需要取消连接,只要调用detach()即可。
小窍门:经常念叨一下:“数据框就是一个列表”,可能会帮你记住上面说的各种引用方法。
上面我们简要描述了和时间序列相关的R的两种数据结构:列表和数据框。实际上,R附加包里面还定义有多种更为复杂的时间序列类型的数据结构,其中比较常用的一种,定义于在stats包中,我们在对矩阵做一个简单介绍再对它做讲述。
矩阵式R中的基本数据对象之一,用于表示和代数中的“矩阵”类似的数据;其创建函数就是matrix():
matrix(data = NA, nrow= 1, ncol = 1, byrow = FALSE, dimnames = NULL)
一个简单的例子:使用4个数构成一个矩阵,观察一下行数和列数是由什么参数确定的:
>matrix(list(1,2,3,4))
[,1]
[1,] 1
[2,] 2
[3,] 3
[4,] 4
> matrix(list(1,2,3,4),nrow=2)
[,1] [,2]
[1,] 1 3
[2,] 2 4
>matrix(list(1,2,3,4),nrow=2,dimnames=list(c("row1","row2"),c("col1","col2")))
col1 col2
row1 1 3
row2 2 4
从上面的例子可以看出,如果没有指定行和列的名称,R直接使用类似“[1,]”这样的表达来表示矩阵的行,及类似“[,1]”的形式来表示列;而如果需要指定列名和行名,则必须使用一个有2个元素的list做dimnames参数,并在每个元素中包含所有的名称。另外,我们可以使用上面的方式来引用矩阵的行或列,即a[1,]表示第1行,而a[,2]表示第2列等:
> #设a是一个2*2矩阵
> a
col1 col2
row1 1 3
row2 2 4
> a[1,]
$col1
[1] 1
$col2
[1] 3
> a[,2]
$row1
[1] 3
$row2
[1] 4
下面我们看看ts数据类型。
R语言中时间序列数据结构的最基本类型是ts类型(它的“class”属性就是“ts”),定义在stats包;这是一种等时间间隔采样的数据,并且至少包括一个采样点;另外,ts类型对数值型数据的支持较好,而对非数值型数据支持较差。
ts()函数用于创建一个时间序列对象,其语法格式为:
ts(data = NA, start =1, end = numeric(), frequency = 1,
deltat = 1, ts.eps =getOption("ts.eps"), class = , names = )
ts()函数使用一个数值型向量或矩阵(由上面的“data”参数指定)来创建一个时间序列对象。
start和end参数指定采样的起始时间和结束时间;可以使用两个数字组成的向量来表示一个自然时间单位上的起始时间,例如,下面的c(1959, 2)表示1959年第2季度:
> a=ts(1:10,frequency = 4, start = c(1959, 2)) # 2nd Quarter of 1959
> class(a)
[1] "ts"
Qtr1 Qtr2 Qtr3 Qtr4
1959 1 2 3
1960 4 5 6 7
1961 8 9 10
frequency参数表示在指定的单位时间上的采样频率。上面例子中frequency是4,表示在一个年度(有start指定的时间单位)上有4个观测值。所有data参数所指定的数据,将按照start、end、frequency等参数指定的时间和采样方式排列成为一个时间序列数据对象。
作为一个被广泛引用的例子,我们看看一家位于昆士兰海滨度假圣地的纪念品商店从 1987到1993年的每月销售数据;该数据文件最早见于Wheelwright andHyndman 1998年出版的《Forecast: Methods andApplications》,其网址在:
http://robjhyndman.com/tsdldata/data/fancy.dat
我们用该数据来演示一下ts对象的应用方法:
> souvenir <-scan("数据/fancy.dat.txt")
# 或直接使用souvenir<- scan("http://robjhyndman.com/tsdldata/data/fancy.dat")
Read 84 items
> class(souvenir)
[1]"numeric"
>souvenirtimeseries <- ts(souvenir, frequency=12, start=c(1987,1))
>souvenirtimeseries
Jan Feb Mar Apr May Jun
1987 1664.81 2397.53 2840.71 3547.29 3752.96 3714.74
1988 2499.81 5198.24 7225.14 4806.03 5900.88 4951.34
1989 4717.02 5702.63 9957.58 5304.78 6492.43 6630.80
1990 5921.10 5814.58 12421.25 6369.77 7609.12 7224.75
1991 4826.64 6470.23 9638.77 8821.17 8722.37 10209.48
1992 7615.03 9849.69 14558.40 11587.33 9332.56 13082.09
1993 10243.24 11266.88 21826.84 17357.33 15997.79 18601.53
Jul Aug Sep Oct Nov Dec
1987 4349.61 3566.34 5021.82 6423.48 7600.60 19756.21
1988 6179.12 4752.15 5496.43 5835.10 12600.08 28541.72
1989 7349.62 8176.62 8573.17 9690.50 15151.84 34061.01
1990 8121.22 7979.25 8093.06 8476.70 17914.66 30114.41
1991 11276.55 12552.22 11637.39 13606.89 21822.11 45060.69
1992 16732.78 19888.61 23933.38 25391.35 36024.80 80721.71
1993 26155.15 28586.52 30505.41 30821.33 46634.38 104660.67
上面的第一个指令是使用scan()函数读取数据;scan()函数的作用是从数据文件中读入数据构成一个向量(或列表);数据文件可以位于本地文件系统中,也可以位于网络上。正如我们在第二条指令中看到的那样,读入的数据构成了一个数值型的向量。然后使用ts()函数将该向量转化成为一个ts类对象,由start指定数据的起始时间,frequency指定每年的采样数,这样系统可以自动地确定后继数据的时间属性。
附注:我们也可以在上面第一步使用已经熟悉的read.csv()函数来读入数据,效果是一样的。
下面我们来对souvenirtimeseries绘图。
> plot(souvenirtimeseries)
>plot.ts(souvenirtimeseries)
上面两条指令对当前的souvenirtimeseries这个简单的数据对象来说,似乎效果是一样的,只是后者(plot.ts())针对时间序列数据有着更为强大的功能,例如,同时进行多个序列的绘制等;我们暂按下不表J。绘图结果如图表2‑3所示。

图表2‑3时间序列对象souvenirtimeseries绘图
从上图中可以看出,souvenirtimeseries存在季节性模式,即在每年的年底都有波峰,并且这个波峰有逐年增大的趋势。如果这种季节模式的幅度比较稳定,则比较容易进行数学处理,因此,我们对该序列进行对数变换:
>logsouvenirtimeseries <- log(souvenirtimeseries)
>plot(logsouvenirtimeseries)
变换后的绘图效果为:

图表2‑4对数变换后的图形,波动幅度基本相近
从上图可以看出,变换后的序列,有着近似等幅的波动特征,这样的模式为我们对该序列的未来值进行预测提供了依据。
下章我们开始介绍时间序列分析的基本方法。
https://blog.sciencenet.cn/blog-577790-829964.html
上一篇:《金融时间序列预测》:第1章:R语言的闪电入门 及配套代码下载
下一篇:《金融时间序列预测》:第12章:R量化投资初步 及配套代码