博文
物美价廉:GROMACS 2018在GPU节点上的使用
|
原文 More bang for your buck: Improved use of GPU nodes for GROMACS 2018, DOI: 10.1002/jcc.26011
2019-08-28 16:47:25 翻译: 刘玉杰; 校对: 李继存
摘要
我们确定了在Linux计算集群上, GROMACS 2018程序运行分子动力学(MD)模拟的最佳硬件. 因此, 我们在各种计算节点上对GROMACS性能进行了基准测试, 并将其与节点成本联系起来, 其中的成本可能也包括能源和冷却成本. 与我们早先使用GROMACS 4.6在2014年的硬件上进行的调查一致, 消费级GPU节点的性价比远高于CPU节点. 然而, 在GROMACS 2018中, CPU到GPU处理能力的最佳平衡更多地转向了GPU. 因此, 与针对旧GROMACS版本优化的节点相比, 针对GROMACS 2018及更高版本进行优化的节点具有更高的性价比. 而且, 向GPU处理的转移使得使用新GPU升级旧节点变得更便宜, 得到的性能与相近的全新硬件基本相同.
引言
分子动力学(MD)模拟是一种成熟的计算工具, 用于从物理学的角度, 在原子水平上研究和理解生物分子的功能. 一个溶剂化分子的模拟系统可以由数千到数百万个原子组成, 具体取决于它是一个小的蛋白质还是像核糖体[1]或病毒外壳[2]这样大的复合物. 为了在生物相关的时间尺度上得出原子运动的时间演化, 需要计算数百万个时间步. 为了得到具有统计学意义的结果, 此过程通常要在不同起始条件下重复多次. 因此, 研究单个生物分子系统就很容易占用多个现代计算节点, 运行数周, 而一个进行MD计算的典型研究小组的所有模拟项目需要一个中型计算集群不间断地运行.
无论所需的集群硬件是由使用它的部门购买, 还是使用高性能计算(HPC)中心的服务, 最终必须有人决定购买什么. 这个决定并不简单, 因为可用的硬件是多种多样的. 节点具体应该如何? 节点是应该拥有多个弱计算核心, 还是拥有较少的强计算核心? 多套节点是否比单套节点更好? 每个GPU需要多少个CPU核心? 哪种GPU类型是最佳的? 内存与节点间的连接呢?
专为不同软件应用设计的全方位集群节点通常包含高端CPU, 具有双精度浮点性能很高的GPU, 大的内存和昂贵的互连. 同时满足这些需求的结果是每个应用程序的计算性能与节点价格的比值非常低. 我们的方法完全相反: 通过具体化来实现成本效益的最大化. 我们只关心一种特定的应用, 即MD, 并寻找在固定预算下能够获得最高模拟吞吐量的硬件, 这是通过在硬件的使用寿命内能够产生的轨迹的总长度来衡量的.
可用于生物分子模拟的MD代码有很多, 其中包括ACEMD[3], Amber[4], CHARMM[5], Desmond[6], LAMMPS[7], NAMD[8], OpenMM[9]和GROMACS[10]. 我们使用GROMACS, 因为它是最快的MD引擎之一, 使用广泛且免费.
我们的基本问题是: 在预算固定的情况下, 我们如何才能产生尽可能多的MD轨迹? 因此, 我们测量典型生物分子MD体系的模拟性能并确定相应的总硬件价格. 我们并没有针对当前的可用硬件进行全面评估, 我们仅仅是为了发现具有卓越性价比的硬件, 这是本研究中使用的效率指标, 用于GROMACS 2018版本的MD代码.
由于我们的研究优先考虑生成轨迹的效率和总吞吐量(假设有大量并发模拟), 因此我们不考虑生成单个轨迹尽可能快的用例. 而后者也可能很重要, 例如, 在探索性研究中, 更快的模拟需要很强的标度行为, 这总是要付出代价的, 因为模拟速度和并行效率之间具有内在的权衡. 同时, 运行大量的独立或耦合不强的模拟是一个广泛使用并日益重要的用例. 由于模拟性能的不断提高, 许多优化过的MD代码(如GROMACS)即使没有大规模并行化, 轨迹的生成速率也很高. 此外, 以前需要生成很长轨迹的问题现如今通常借助系综方法, 使用大量更短的轨迹来替代[11-15]. 因此, 具有单个快速互连的大型计算资源通常并不是必须的. 相反, 在这些实例中, 理想硬件是具有快速”孤岛”并且相互间具有更适度的互连. 事实上, 在这样的机器上, 某些情况下可以获得很快或更快的结果, 更重要的是, 可以获得更具成本效益的结果. 在我们的案例中, 考虑到当前的硬件限制和软件特性, 出于最终效率的原因, 快速”孤岛”由一组CPU核心和单个GPU表示.
除了性价比之外, 在评估系统时, 我们还考虑到以下两个标准: (1) 能耗, 因为它是轨迹成本的最大来源之一; (2) 机架空间, 这在任何服务器机房都是有限的. 在本文的一个章节中我们单独介绍了能耗, 而我们的硬件预选则隐含地考虑了空间要求; 对要考虑的服务器节点, 我们要求机架空间中的平均堆积密度至少为每高度单位U一个GPU: 具有4个GPU的4U服务器符合标准.
在使用GROMACS 4.6和2014年硬件的早期调查中[16], 我们发现优化的集群的模拟吞吐量通常是传统集群的两到三倍. 自2014年以来, 硬件一直不断发展, 并且以及对基本算法经进行了改进. 因此, 使用两个完全相同的MD测试系统, 我们更新原先的调查结果, 向读者指出对GROMACS 2018而言能获得最佳性价比的当前硬件[10, 17].
我们专注于硬件评估而不是如何优化GROMACS的性能, 因为对后者已经进行了广泛的讨论[16]. 如果没有额外说明, 我们原始论文中给出的大多数性能建议仍然有效. 有关特定GROMACS版本的特殊说明, 请参见在线用户指南中 Getting good performance from mdrun 这一部分。
GROMACS负载分配方案
GROMACS使用各种机制对可用资源上的计算工作进行并行化, 以便能获得最佳的硬件性能[10, 18]. 共享MD体系计算的进程(称为rank)是通过消息传递接口(MPI)库进行通信的, 每个rank可以包含多个OpenMP线程. 如果可以, 每个rank可以有选择地在GPU上计算库仑和范德华相互作用(对势)的短程部分; 这个过程称为卸载, 如图5所示. 库仑相互作用的长程部分使用粒子网格Ewald(PME)方法[19]进行计算, 该方法可以只使用一部分rank进行以提高并行效率. 从2018版开始, PME也可以卸载到单个GPU上进行. 在并行化层次结构最低的级别上, 几乎所有对性能敏感的代码都利用了SIMD(单指令多数据)并行性.
2014年调查总结
为了说明过去五年中在实现方面和硬件方面的进步, 我们总结了先前调查的以下要点.
在我们最初的调查中[16], 对由12个CPU和13个GPU型号构成的超过50种不同的节点配置, 我们确定了硬件价格和GROMACS 4.6的性能. 特别是, 我们将消费级GPU与专业GPU进行了比较. 像NVIDIA的Tesla和Quadro型号的专业GPU通常用于计算机辅助设计, 计算机图像生成以及HPC. 消费级GPU, 如GeForce系列, 主要用于游戏. 它们便宜得多(最高差价达1000欧元, 而专业卡则高达几千欧元), 而且缺乏专业型号所提供的一些功能, 如内存和双精度浮点性能.
我们的两个主要基准系统(我们在本研究中继续使用), 第一个含有一个80 k原子的膜蛋白, 嵌入脂质双层中, 周围是水和离子(MEM); 第二个含有一个2 M原子的核糖体, 以及水和离子(RIB). 具体细节请参见表1. 对每个硬件配置, 我们通过扫描并行化的参数, 如MPI rank数, OpenMP线程数和单独PME rank数, 确定了每个系统运行单个模拟的最快设置.
| MD体系 | MEM[20] | RIB[1] | VES[21] | BIG |
|---|---|---|---|---|
| 粒子数 | 81,743 | 2,136,412 | 72,076 | 2,094,812 |
| 体系尺寸(nm) | 10.8×10.2×9.6 | 31.233 | 22.2×20.9×18.4 | 142.4×142.4×11.3 |
| 时间步长(fs) | 2 | 4 | 30 | 20 |
| 截断半径(nm) | 1.0 | 1.0 | 1.1 | 1.1 |
| PME网格间距(nm) | 0.12 | 0.135 | – | – |
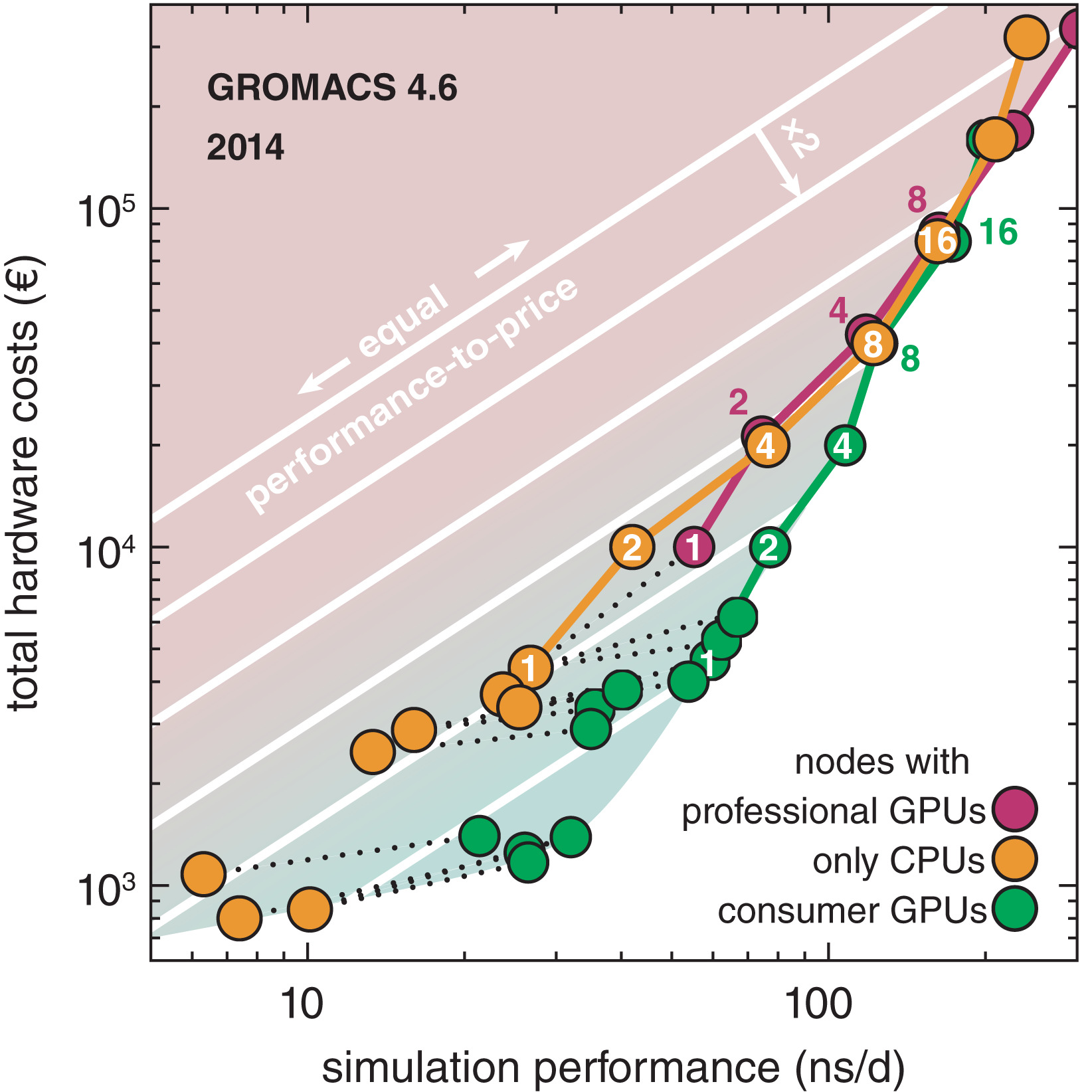
图1: 我们以前调查的摘要, 节点基于2014年的可用硬件, 使用GROMACS 4.6进行测试[16]. 三种不同类型节点的硬件成本与MEM基准性能(圆)的比较: 纯CPU节点(橙色), 具有专业Tesla GPU的节点(紫色)和具有消费级GeForce GPU的节点(绿色). 虚线将GPU节点与其CPU连接起来. 由彩色线连接的圆圈表示由该节点类型构建的集群, 圆圈中的数字表示这些节点中有多少参与了基准测试. 白线是具有相等性价比的等值线. 从一个等值线向下移动到下一个等值线性价比会变为原来的2倍(红色阴影区域=低性价比, 绿色阴影区域=高性价比)
我们从调查中得出的结论(图1)是, 只含单个CPU的节点和具有专业GPU的节点具有相对较低的性价比, 而消费级GPU的性价比可以提高到原来的2到3倍. 为节点增加第一个消费级GPU会极大地提供性价比, 而增加过多的GPU会降低性价比(例如, 以前论文的图6中将带有2个E5-2680v2的节点与具有2个和4个GTX980 GPU的节点进行了比较).
在多个节点上进行并行化以提高性能会导致性价比急剧下降(图1, 右上角). 因此, 对于总采样量比单个轨迹长度更重要的项目, 建议运行多个单节点模拟, 而不是运行一些多节点模拟.
2014-2018年硬件和软件的发展
硬件的发展
在过去五年中, GPU的计算能力显著提高(比较表2和图2). 最近的NVIDIA Turing架构GPU比我们在2014年测试的Kepler和Maxwell领先两到三代, 并且在此期间将单精度(SP)浮点性能提高到原来的三倍多. 这得益于半导体制造技术的飞跃, 将Kepler和Maxwell使用的28 nm晶体管工艺缩小到Volta和Turing的12 nm, 并使晶体管数量增加到五倍以上. 相比之下, 在同一时期, CPU制造从22纳米向14纳米迈进了一小步. 然而, 基于GPU的高效MD应用程序的性能在某些情况下甚至比单纯浮点性能所表明的好得多, 这得益于微体系结构的改进, 使得GPU更高效, 因此更适合于通用计算. 例如, 考虑受计算限制的非键对相互作用内核的性能(图3, 上). 早期GPU产品吞吐量的增长, 如从Tesla K40到Quadro M6000再到Quadro P6000, 可以很好地反映FLOP速率的增长(两者大约为1.9倍), Tesla V100显示了1.7倍的性能, 而SP FLOP速率的增益只有1.1倍(见图2和3中的紫色条). 与上述具有类似最大额定功率的专业GPU不同, 比较消费级GPU并没有那么简单. 然而, 在将Pascal GTX 1080Ti与Turing RTX 2080 GPU进行对比时, 类似的模式仍然很明显. 尽管FLOP大约降低了10%, 最大额定功率也会降低10%, 2080在非键和PME计算中分别快40%和29%. 在两代GPU中, 我们观察到使用GPU卸载的GROMACS计算内核, 计算非键对势相互作用和PME静电力的性能分别提高到6倍和4倍. 相比之下, 虽然CPU的理论FLOP速率的增加与GPU类似, 但微架构的改进, 如更宽的AVX512 SIMD指令集, 仅仅相对适度的提高了应用程序的性能, 即使对完全SIMD优化的代码(如GROMACS)也是如此.
| 类型 | 制造商 | 架构 | 计算单元 | Base-boost频率(MHz) | SP TFLOPS | ≈净价( |
|---|
https://blog.sciencenet.cn/blog-548663-1195694.html
上一篇:吴伟:auto-martini的安装和使用简介
下一篇:猜想的终结