博文
对于共轭梯度最优化方法的一些认识
||
共轭梯度法最初由Hesteness和Stiefel于1952年为求解线性方程组而提出的。后来,人们把这种方法用于求解无约束最优化问题,使之成为一种重要的最优化方法。
Fletcher-Reeves共轭梯度法,简称FR法。
共轭梯度法的基本思想是把共轭性与最速下降方法相结合,利用已知点处的梯度构造一组共轭方向,并沿这组方向进行搜素,求出目标函数的极小点。根据共轭方向基本性质,这种方法具有二次终止性。
对于二次凸函数的共轭梯度法:
min f(x) = 1/2 xTAx + bTx + c,
其中x∈ Rn,A是对称正定矩阵,c是常数。
具体求解方法如下:
首先,任意给定一个初始点x(1),计算出目标函数f(x)在这点的梯度,若||g1|| = 0,则停止计算;否则,令
d(1) = -▽f(x(1)) = -g1。
沿方向d(1)搜索,得到点x(2)。计算在x(2)处的梯度,若||g2|| ≠ 0,则利用-g2和d(1)构造第2个搜索方向d(2),在沿d(2)搜索。
一般地,若已知点x(k)和搜索方向d(k),则从x(k)出发,沿d(k)进行搜索,得到
x(k+1) = x(k) + λkd(k) ,
其中步长λk满足
f(x(k) + λkd(k)) = min f(x(k)+λd(k))。
此时可求出λk的显示表达

计算f(x)在x(k+1)处的梯度。若||gk+1|| = 0,则停止计算;否则,用-gk+1和d(k)构造下一个搜索方向d(k+1),并使d(k+1)和d(k)关于A共轭。按此设想,令
d(k+1) = -gk+1 + βkd(k),
上式两端左乘d(k)TA,并令
d(k)TAd(k+1) = -d(k)TAgk+1 + βkd(k)TAd(k) = 0,
由此得到
βk = d(k)TAgk+1 / d(k)TAd(k)。
再从x(k+1)出发,沿方向d(k+1)搜索。
在FR法中,初始搜索方向必须取最速下降方向,这一点决不可忽视。因子βk可以简化为:βk = ||gk+1||2 / ||gk||2。
The algorithm is detailed below for solving Ax = b where A is a real, symmetric, positive-definite matrix. The input vector x0 can be an approximate initial solution or 0.
 #x0为初始值向量
#x0为初始值向量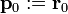


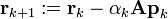

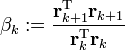

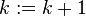
To illustrate the conjugate gradient method, we will complete a simple example.
Considering the linear system Ax = b given by

we will perform two steps of the conjugate gradient method beginning with the initial guess

in order to find an approximate solution to the system.
[edit]SolutionOur first step is to calculate the residual vector r0 associated with x0. This residual is computed from the formula r0 =b - Ax0, and in our case is equal to
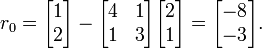
Since this is the first iteration, we will use the residual vector r0 as our initial search direction p0; the method of selecting pk will change in further iterations.
We now compute the scalar α0 using the relationship
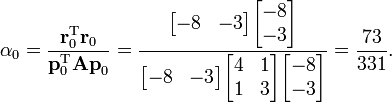
We can now compute x1 using the formula
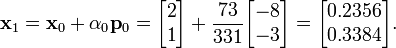
This result completes the first iteration, the result being an "improved" approximate solution to the system, x1. We may now move on and compute the next residual vector r1 using the formula

Our next step in the process is to compute the scalar β0 that will eventually be used to determine the next search direction p1.
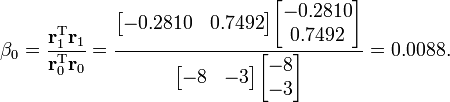
Now, using this scalar β0, we can compute the next search direction p1 using the relationship

We now compute the scalar α1 using our newly-acquired p1 using the same method as that used for α0.

Finally, we find x2 using the same method as that used to find x1.
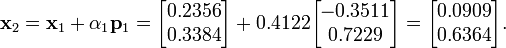
The result, x2, is a "better" approximation to the system's solution than x1 and x0. If exact arithmetic were to be used in this example instead of limited-precision, then the exact solution would theoretically have been reached after n = 2 iterations (n being the order of the system).
共轭梯度法在R中的实现
在R的stats包中有个函数optim()可以实现该算法。该函数的使用如下:
optim(par, fn, gr = NULL, ...,
method = c("Nelder-Mead", "BFGS", "CG", "L-BFGS-B", "SANN"),
lower = -Inf, upper = Inf,
control = list(), hessian = FALSE)
参考自:
1 Wiki http://en.wikipedia.org/wiki/Conjugate_gradient_method
2 http://www.cnblogs.com/yangxi/archive/2011/10/20/2219408.html
3 CRAN
https://blog.sciencenet.cn/blog-54276-569356.html
上一篇:perl中十进制和16进制的转换
下一篇:R中用于排序的几个函数