博文
范剑青综述:大数据分析面临的机遇与挑战 | NSR
|||
由美国普林斯顿大学范剑青教授作为通讯作者撰写的综述文章 “Challenges of Big Data analysis”(译名:大数据分析面临的机遇与挑战)已在 National Science Review(NSR)(《国家科学评论》)2014年第2期发表。
大数据分析给现代社会带来了新的机遇与挑战。一方面,与传统研究侧重于揭示事物的共性不同,大数据研究将有助于人们发现事物的个体特性,并针对每一个体的特性给出个体化的解决方案。同时,大数据研究也将使人们能够从大量个体的差异变化中,揭示其中存在的难以察觉的规律。另一方面,大数据的海量样本规模和高维数特征也引入以下显著特性:数据搜集的偏差性、数据产生的异母体性、计算成本、噪音的累积叠加、假关联性、外生性,以及测量误差等等。为了应对这些挑战,需要引入新的计算和统计方法。
这篇文章综述了大数据的几个独有的特点及其对统计分析和计算体系结构的影响。首先,从计算的角度来看,大数据提供的数据量巨大,这会给实施统计计算和最后完成统计估算和检验带来问题。比如,对于一个列数上百万的矩阵,一次简单的矩阵求逆操作在计算上都是困难的。该文概括性地介绍了Hadoop分布式文件系统、MapReduce编程模型、云计算、凸优化算法,以及随机投影技术,以解决海量数据的计算问题。其次,从统计分析的角度来看,大数据经常包含被抽样个体的大量特征信息,即样本的个异性和高维性。个异性和高维性给统计分析与计算带来诸多问题,包括异母体、噪音累积、假相关、内生性。以假相关性为例,高维数会增加发现欺骗性关联的风险。比如,在人类基因表达数据分析中,学者可能会认为第八对染色体上的某个重要致癌基因(MYC)和Y染色体性别决定基因(SRY)有很强的相关性。但是,这可能仅仅是因为考虑的基因数目太高,以至于有些高相关性的出现只是偶然事件。
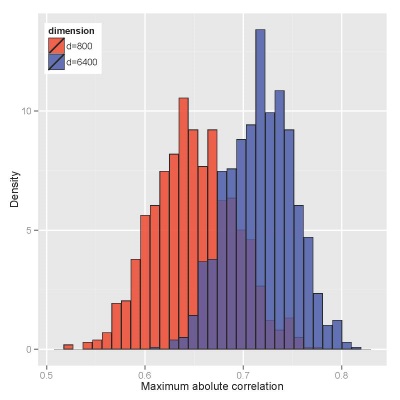
图 1. 800个(红色)和6400个(蓝色)独立的标准正态分布中,第1个与其余4个变量的最大相关系数的统计分布(n=60)。观察可知,假相关系数相当大。
该文也为大数据分析提供了新的展望。以高维数据下的统计推断为例,文中给出了高致信区间内的最稀疏解的一般解,并指出许多传统的理论所基于的外生性假设是不正确的,尤其可能导致错误的统计推断,并得出错误的科学结论。以内生性问题为例,范剑青教授和他的合作者指出,线性回归模型中的外生性假设在高维数下很可能是不正确的:当考虑的回归变量数目很大时,其中的一些回归量(自变量)很有可能和模型的误差项相关。他们发现,当内生性问题存在时,流行的高维回归方法(诸如lasso和SCAD)的估计值不具有相合性,即:随着样本数变大,估计量和母群体参数的差异不会趋近于零。本文介绍了一种新的、基于广义矩与高维回归的方法。这个方法可以克服内生性问题,并给出具有一致性的估计量。
综述原文详见 National Science Review 网站:
COMPUTER SCIENCE
Jianqing Fan, Fang Han,and Han Liu
Challenges of Big Data analysis
Natl Sci Rev (June 2014) 1 (2): 293-314 doi:10.1093/nsr/nwt032
https://blog.sciencenet.cn/blog-528739-817041.html
上一篇:呦呦鹿鸣——燕国公主眼里的霸国
下一篇:美丽化学 〡美杜莎化学──石头的蝴蝶