博文
2013年以前的PM2.5数据缺失怎么办? 机器学习“算”出来 | NSR
||
自2013 年起,生态环境部建立了地基监测站点,开始对细颗粒物(PM2.5)污染进行业务观测。但是,此前的历史数据难以获取,导致长序列PM2.5数据缺失,为认识中国PM2.5长期变化带来了挑战。
为解决这一问题,中国气象科学研究院张小曳团队基于国家级地面气象观测网,抽取空间特征并结合先进的机器学习技术LightGBM,构建了考虑空间气象效应的高性能机器学习模型,能够获取1960年代以来的长序列PM2.5历史数据集。该数据集将对理解气溶胶长期变化趋势、环境和气候影响以及通过同化到化学-天气耦合模型中构建长期再分析数据具有重要价值。

建模:气象数据+空间特征
目前,已经存在基于卫星气溶胶光学厚度(AOD)来估算PM2.5的方法,但卫星数据中存在大量缺失值、采样频率低且整体预测能力不高,估算结果在很大程度上受到了影响。
与卫星数据相比,地面气象观测具有序列时间长、时间分辨率高、数据完整性好等优势。在我国,中国气象局的国家级气象观测网始建于20世纪50年代,能够连续观测逐小时的温、压、风、湿等气象数据。1960年后国家级观测站数量超过2000个,而后稳定在2450个左右,此外,还有超过6万个区域观测站。因此,如果能够利用这些地面气象数据来估算我国的历史PM2.5数据,可能会取得更好的效果。
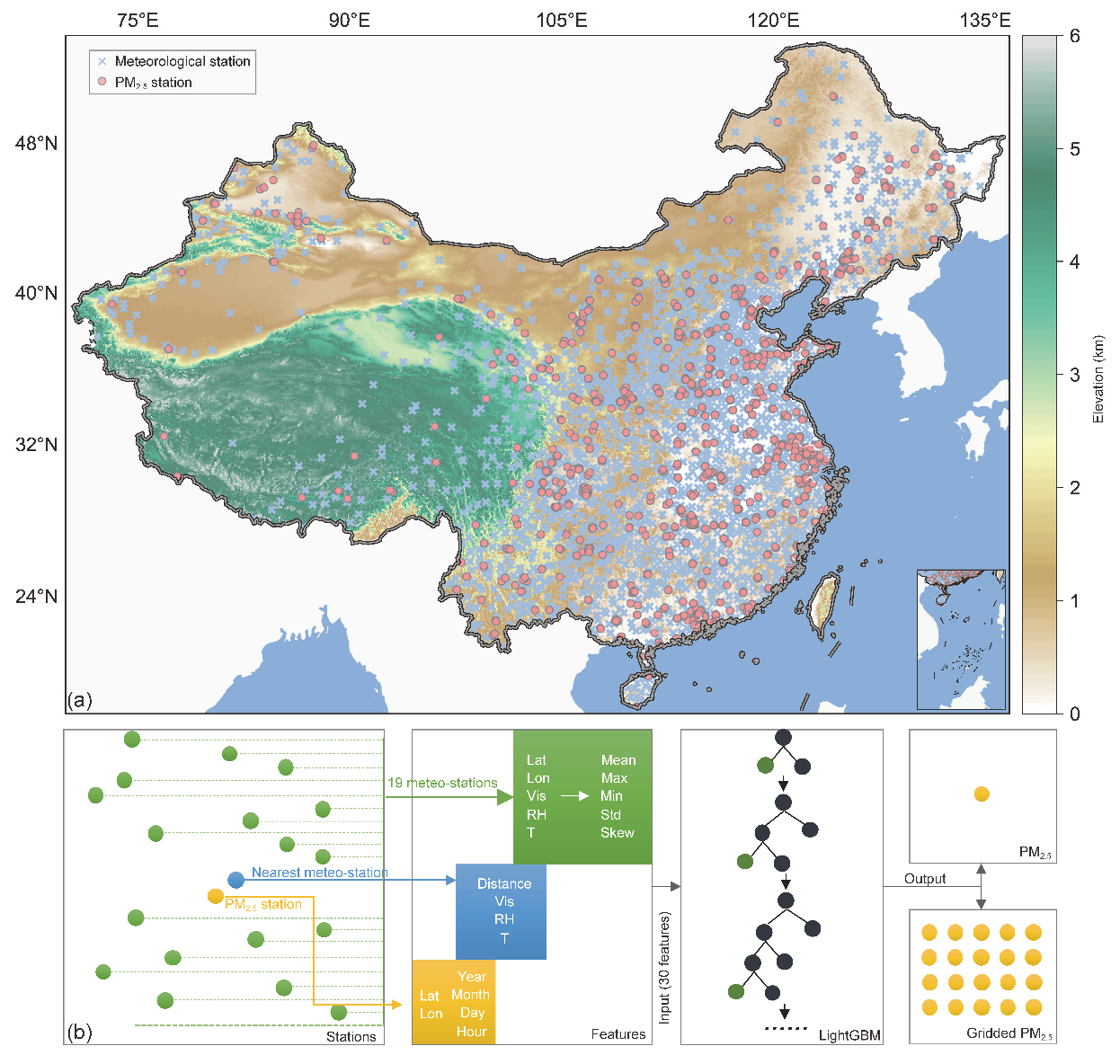
要建立反演PM2.5历史数据的机器学习模型,我们应该以哪些数据作为输入的“已知条件”呢?
首先是气象要素。现有研究表明,如果在一段时间内排放水平基本稳定,那么不利的气象条件将成为控制PM2.5污染形成、加剧和消散的关键因素。因此通过温、压、风、湿等气象要素来反演PM2.5在理论上是可行的。
其次是能见度数据。由于PM2.5会显著影响能见度,因此引入能见度能够在一定程度上反推PM2.5在不同时间尺度的变化。
此外,还有空间效应。对于单个环境监测站点,其PM2.5浓度不仅与最近气象站的观测要素密切相关,还会因输送等过程受到周边气象条件的影响。
综合上述思考,研究人员选取了最近站点的气象要素,并从周边19个气象站中提取了5个变量,包括纬度、经度、能见度、温度和相对湿度,对于每个变量依次计算出平均值、最大值、最小值、标准差和偏度值,分别将其作为特征用于构建模型。
最后,研究人员将超过三千万条的2016-2018年逐小时数据用于模型训练,并将超过一千万条的2019年数据用于模型评估。
模型效果:优于已有模型
研究人员使用十折交叉验证方法,验证了这个模型的准确性。十折交叉验证是机器学习中参数调优和模型验证的常用方法,即将训练数据集分成十份,轮流将其中9份作为训练数据,另1份作为测试数据,每次试验都会得出相应的评价值,最后求其均值,作为对模型准确性的估计。
十折交叉验证结果表明,该模型的逐小时PM2.5观测值与估计值的决定系数(R2)和均方根误差(RMSE)分别为0.80和19.80 μg m-3。在更大的日、月、年时间尺度上,模型的表现更为出色,R2值分别增加到0.89、0.94和0.98,RMSE值分别降低到12.78 μg m-3、6.78 μg m-3和2.16 μg m-3。
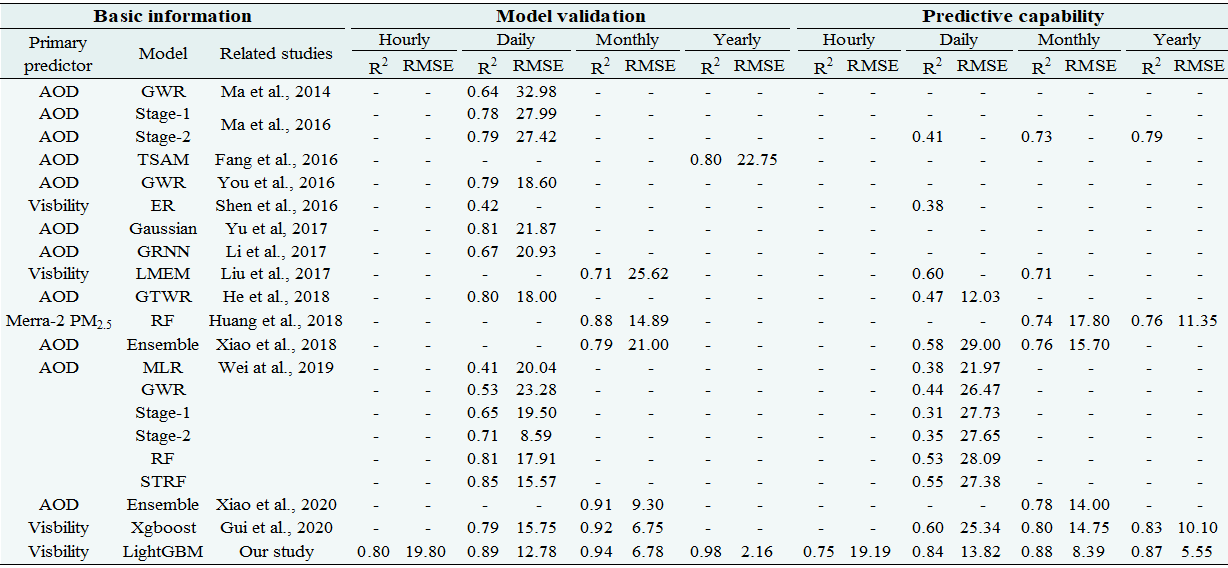
研究人员还将交叉验证的评分与其他模型进行了比较。如下表所示,该模型从日到年尺度都优于其他模型,其小时尺度R2(0.80)甚至优于其他大多数模型日尺度R2(0.41~0.85)。
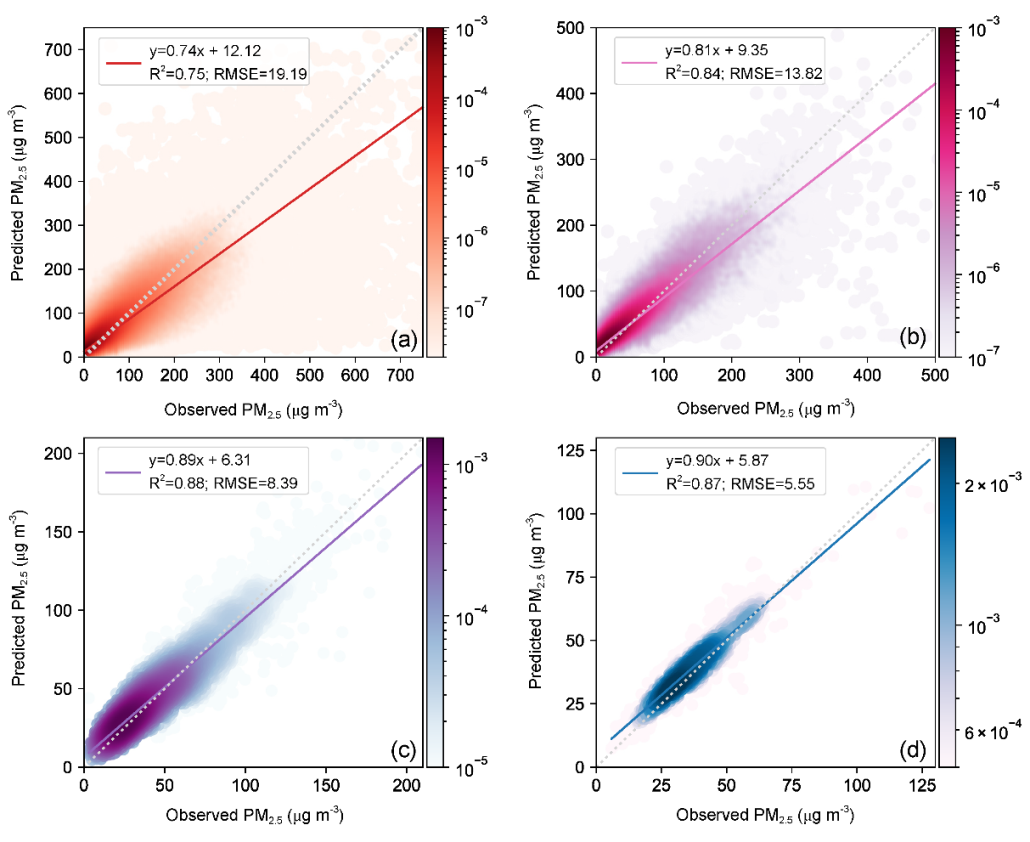
为了检验模型的预测能力,研究人员将模型预测的2019年PM2.5数值和观测的实际数值进行了比较。结果表明,在小时(R2=0.75)、日(R2=0.84)、月(R2=0.88)年(R2=0.87)时间尺度上,该模型都能够以前所未有的预测能力准确估算PM2.5质量浓度。与上表中的其他模型相比,该文的模型不仅可以对PM2.5进行逐小时预测,在日、月、年尺度的预测能力上也都展示出相当大的优势,而这些优势主要来自于空间气象效应的引入。
为了评估模型在我国不同地区的预测能力,研究人员绘制了小时尺度R2的空间分布(下图)。在下图中,研究人员选择了5个重点污染区域进行着重分析,包括(1)华北平原和关中平原;(2)长三角地区和长江中下游的两湖流域;(3)珠三角地区;(4)四川盆地;和(5)东北平原。
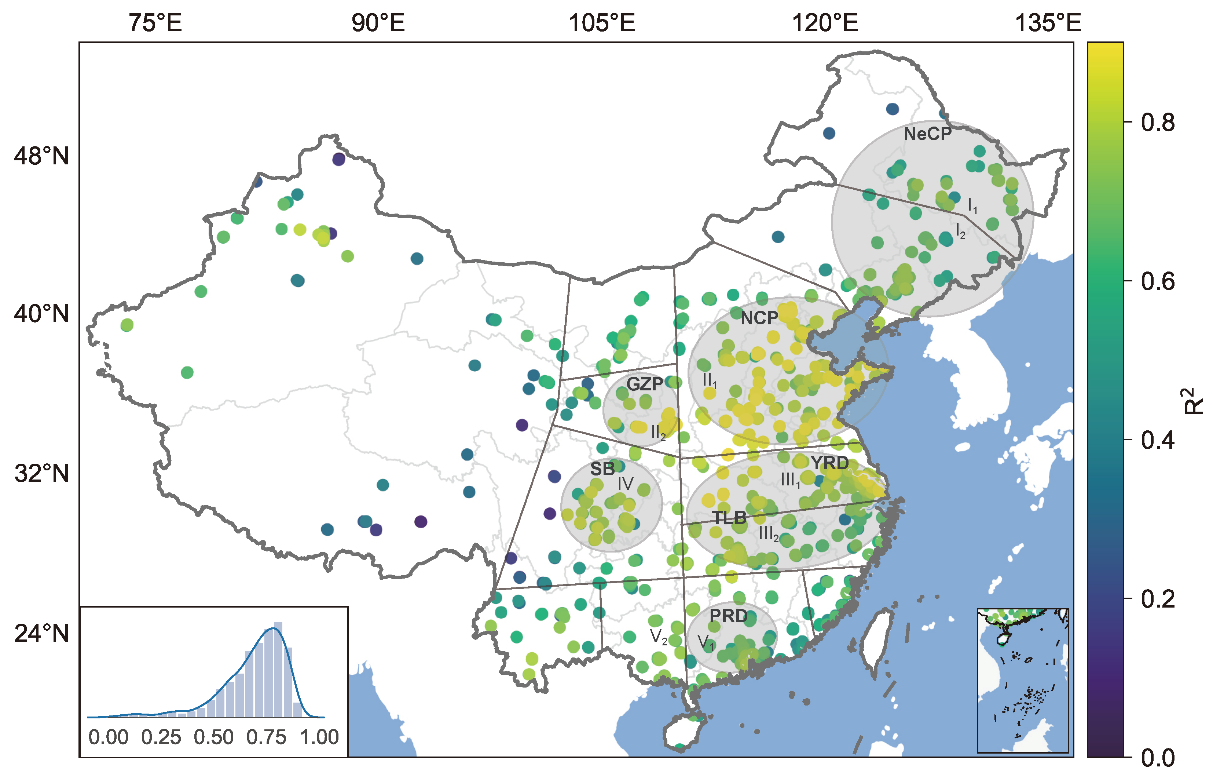
结果发现,该模型在以上 5 个地区均具有较好的预测能力, 特别是在污染较重的地区。在这些地区中,模型对华北平原PM2.5的预测能力最为突出,R2普遍大于0.80,在关中平原对PM2.5的预测也表现出较高的准确性,R2超过0.80。在四川盆地由于常年多云,AOD缺失超过70%,但地面观测不受影响,模型呈现出可靠的预测性能,R2约为0.75。在长三角和四川盆地,R2值在0.65和0.90之间波动,但在大多数情况下仍超过0.80。在东北平原和珠三角地区,R2值在0.70左右波动。进一步的分析表明,这5个区域R2的区域差异受污染水平、相对湿度、气象站分布等3个因素影响。
总之,该文构建的模型具有良好的准确性和预测能力,由此获得的历史PM2.5数据集也将会较为准确。
除了补足历史数据,这个模型还能做什么?
目前,我国PM2.5站点的空间分布不均,大部分都位于中东部城市地区。相比之下,气象站的分布较为均匀,且密度较高。因此,这个模型还能使用气象站数据,构建出高时间分辨率的密集PM2.5格点网络。研究人员以华北地区为例,呈现了PM2.5站点观测和预测PM2.5网络的分布情况(下图a,b)。可以看到,网格化PM2.5与观测的PM2.5浓度准确对应,并提供了更详细的空间分布信息。
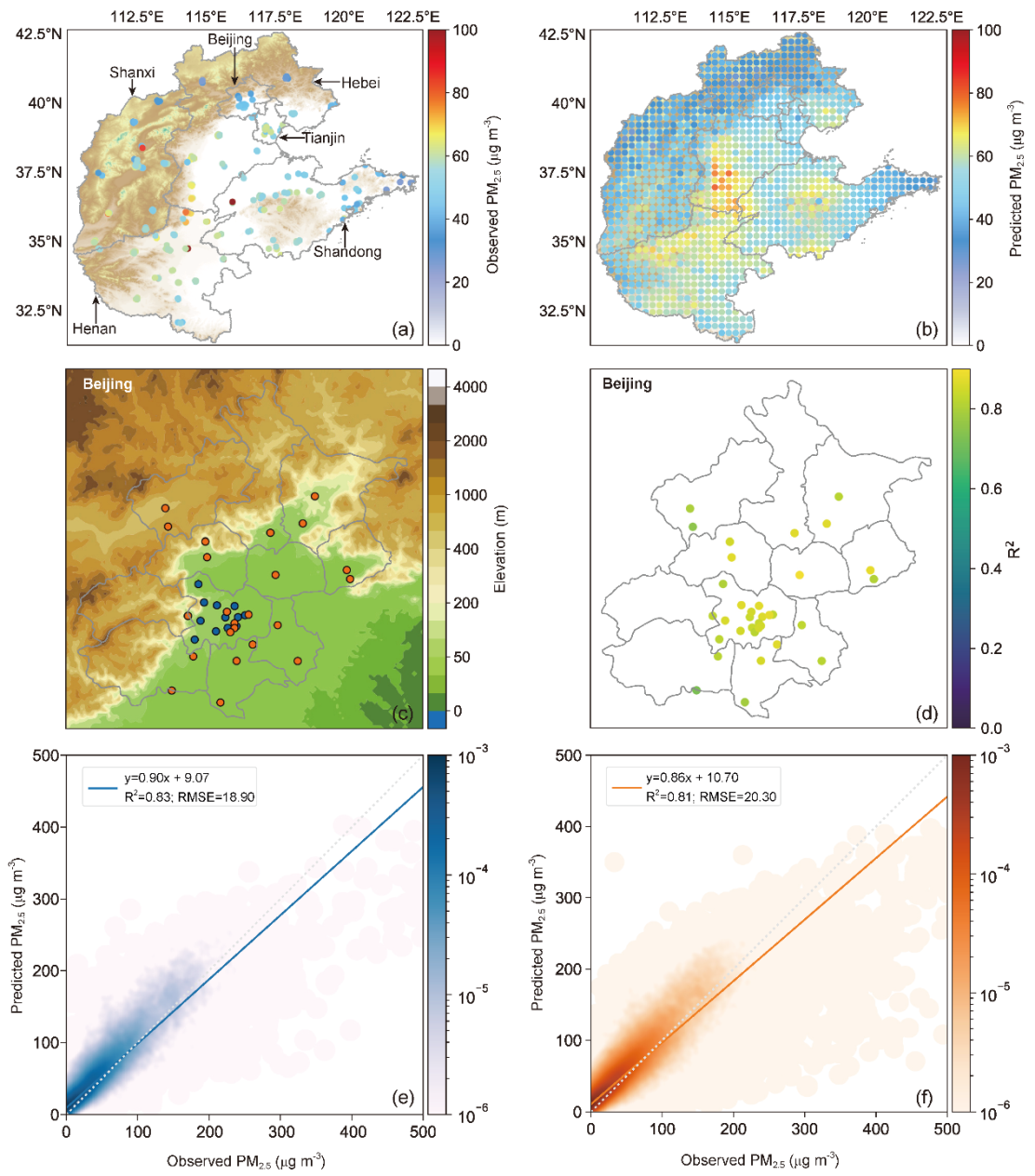
为了进一步验证观测站点外的格点PM2.5浓度的准确性,研究人员选取了23个未在模型训练中使用的PM2.5区域站(上图c),通过模型预测这些站点的PM2.5小时浓度,并与2019年的PM2.5观测值进行对比。如上图d所示,在23个区域站中,有22个区域站的R2值超过0.75,并且在国家站和区域站之间没有表现出显著差异。对于所有23个区域站的PM2.5小时浓度,R2和RMSE分别为0.81和20.30,仅比12个国家站的R2和RMSE(R2=0.83,RMSE=18.90)稍弱(上图e,f)。这些结果表明,该模型能够很好地预测训练站范围内外地点的PM2.5浓度,网格化PM2.5的准确性值得信任。
上述成果发表于《国家科学评论》(National Science Review,NSR)中国气象科学研究院博士研究生仲峻霆为该论文第一作者,中国气象科学院张小曳院士和桂柯博士为共同通讯作者,合作作者还包括王亚强研究员、车慧正研究员、孙俊英研究员、张养梅研究员、沈小静博士、张磊博士和博士研究生张文杰。
文章信息:[点击下方链接可阅读原文]
Robust prediction of hourly PM2.5 from meteorological data using LightGBM
https://doi.org/10.1093/nsr/nwaa307

https://blog.sciencenet.cn/blog-528739-1268267.html
上一篇:载流子注入平衡助力钙钛矿QLED外量子效率突破21% | Science Bulletin
下一篇:痛的领悟