博文
VASP 6.1.0 Hybrid openMPI/openMP parallelization(混合并行)学习体会
||
VASP 6.1.0发布了,其中有一项重要的升级是支持OpenMP和openMPI混编。
这就要从硬件和软件两方面来理解这个问题,vaspwiki给出了一个解释[1]。

大体的意思是这样,我们现在使用集群来并行计算,首先选择了n个节点,然后每个节点又选择了m个核,就构成了我们实际使用的总核数为T=n*m。这就牵涉到两个通讯过程,一个是单个节点内m个核之间的信息通讯,另外一个就是n个节点之间的通讯。既然是信息通讯,就需要一个协议,这是所谓的MPI和openMP。这个已经很多讨论了,引用一下[2]:
MPI(MPI是一个标准,有不同的具体实现,比如MPICH等)是多主机联网协作进行并行计算的工具,当然也可以用于单主机上多核/多CPU的并行计算,不过效率低。它能协调多台主机间的并行计算,因此并行规模上的可伸缩性很强,能在从个人电脑到世界TOP10的超级计算机上使用。缺点是使用进程间通信的方式协调并行计算,这导致并行效率较低、内存开销大、不直观、编程麻烦。
OpenMP是针对单主机上多核/多CPU并行计算而设计的工具,换句话说,OpenMP更适合单台计算机共享内存结构上的并行计算。由于使用线程间共享内存的方式协调并行计算,它在多核/多CPU结构上的效率很高、内存开销小、编程语句简洁直观,因此编程容易、编译器实现也容易(现在最新版的C、C++、Fortran编译器基本上都内置OpenMP支持)。不过OpenMP最大的缺点是只能在单台主机上工作,不能用于多台主机间的并行计算!
按照VASP官方的解释,vasp最初的版本不但节点间使用MPI交换信息,节点内的核与核之间,也采用MPI来交换信息,这样核间的信息传输速度就被拉低了,从而影响了总体的并行效率。这样如果采取混编的模式的话,就可以限定核间openMP,节点间mpi了,提高了并行效率,也可以使更大规模的并行计算加速比有所提高。
但是,科音上有位老师做了测试[3]。等到了这样的结论:

也就是混编以后速度并没有提升多少,我也做了一些测试,的确是,混编不混编速度区别很小,有时候还慢些。这是为什么呢?
vaspwiki上有一段话也许可以解释这个疑问[1]:
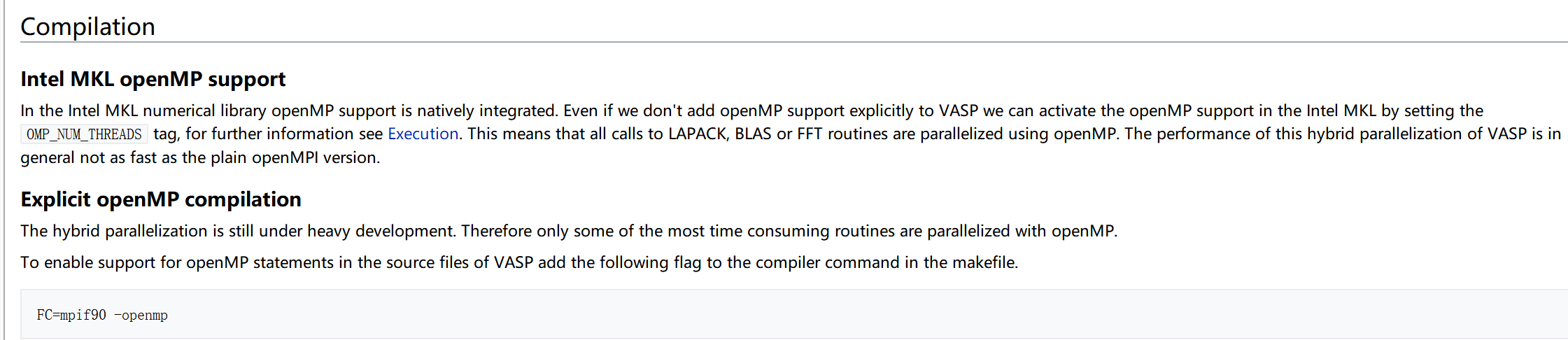
这段话的大体意思是说,如果编译VASP全部使用intel编译器和intel mpi的话,已经内嵌的进行了openmp和mpi的混合并行,所以说,你即使混合编译,没有使用OMP_NUM_THREADS等参数,intel编译器自己已经进行了自动的分配,所以这也就解释了为啥用intel的编译器混编不混编没啥变化。
另外,提供了Explicit的编译方式,不使用intel编译器,而是只使用openMPI来编译VASP,按照官方的说法就是,用intel编译的vasp 一般来说没有使用纯openMPI version的快。
至于快多少,可能还需要等待更多的测试结果。
一些学习体会,不当之处还请批评指正。
[1] https://www.vasp.at/wiki/index.php/Hybrid_openMPI/openMP_parallelization
[2] https://blog.csdn.net/ddreaming/article/details/53319501
[3] http://bbs.keinsci.com/thread-16191-1-1.html
https://blog.sciencenet.cn/blog-478347-1218607.html
上一篇:推荐一个dos仿真器(ConEmu)
下一篇:VESTA 打开CONTCAR显示白板的问题