博文
平地惊雷:AlphaFold2解决了蛋白质结构预测的问题?
 精选
精选
||
平地一声惊雷,Google的AlphaFold2在今年第14届蛋白质结构预测的比赛(CASP14)中对大部分的蛋白实现了原子精度或者接近原子精度的结构预测,把学术界的预测远远甩在后面,不仅仅计算生物学家而且实验结构生物学家也被震惊了。AlphaFold2预测的一个结构甚至帮助结构生物学家发现他们的错误,而另外一些结构,预测与实验的不同很可能是由于结晶导致的表面变化。并且AlphaFold2几个没有预测太好的结构大多是固有无序蛋白,是只有形成多聚体才能有结构的蛋白。想到两年前(CASP13),AlphaFold还只是比学术界好那么一点(预测的结构大体是对的,但细节还不行,见我上次的博客)。而这次比赛,虽然学术界赶上了上次AlphaFold的水平,但AlphaFold2却实现了一个量子的飞跃,似乎彻底解决了这个问题,连颜宁也觉得很多人要失业了。
在刚刚结束的CASP14会议,关于AlphaFold2的具体方法,虽然有一些提示,但还是语焉不详,估计要等下一篇Nature文章发表了之后才能彻底搞清楚。但即使如此,许多在这个领域工作的科研人员(包括我们)都蠢蠢欲动,希望能从这个会议演讲的提示里找到AlphaFold2致胜的杀手锏,估计到第15届,顶尖的课题组就都能赶上AlphaFold2了,避免一家独尊,向Google讨饭吃了。

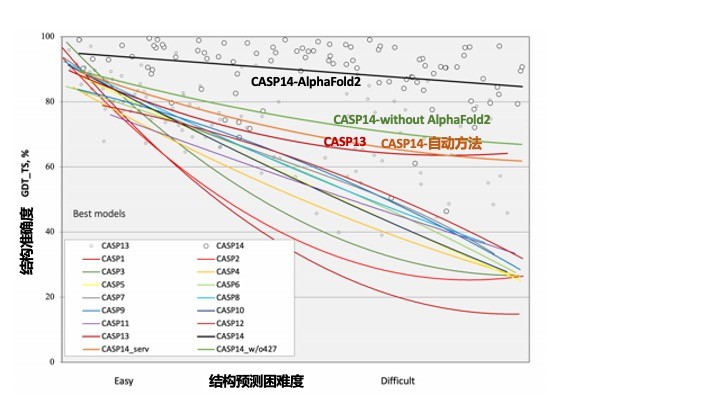
Credit: deepmind. https://deepmind.com/blog/article/alphafold-a-solution-to-a-50-year-old-grand-challenge-in-biology
但是,AlphaFold2真的解决了蛋白质结构预测的问题了吗?这次CASP14的多数蛋白质有较多的同源序列,所以学术界也都能够比较准确地预测蛋白质的大体形状(topology,见上图)。AlphaFold2比其他组更加成功的原因在于能够对同源序列里面的相关突变信息,不仅仅在主链,而且对支链的结构上进行更加深度、可靠地挖掘。为了尽可能找到最多的同源序列,AlphaFold2用了3个序列数据库(UniREF, BFD, 和MGnify),并且为了学到最多的结构信息,AlphaFold2把所有的17万已知结构都放进数据库里面了。有了这些大数据以及超大的训练(用了128个Google自家独有的 TPU,训练了几周,也就是每周68万美金GoogleCloud的计算量),才实现了原子精度的结构预测,所以不是那个大学的课题组能做的事情,但是它无疑做到了结构预测的极限。
但是假如某个蛋白在其他生物体没有同源序列的话,AlphaFold2也就无能为力了。事实上我们课题组的工作发现,用同源序列的话,蛋白质的二级结构预测可以达到86%左右,接近理论的极限,但没有同源序列,只有单序列信息的情况下,二级结构预测只能达到73%,所以单序列结构预测(真正的蛋白质折叠问题)还任重道远着呢!还请基金会继续支持!
https://blog.sciencenet.cn/blog-472757-1260848.html
上一篇:从美国总统选举的大数据预测说起
下一篇:百度的螺旋桨RNA结构预测竞赛,预测的不是RNA结构