博文
Random Ferns 做人脸检测的实验
|||
在一个人脸检测器的24x24训练样本上随机生成采样位置,生成S=5个采样点对。
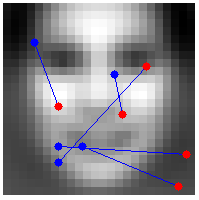
如图所示,线段两端表示采样对,把蓝红位置像素值进行比较,蓝色位置像素比红色大,则用1表示,否则表示为0。这样5个点对得到的0/1值,可以用一个5-bit二进制数表示。这样每个样本就可以表示为0~31的整数,作为一个特征值。这样的特征计算非常简单,只有比较大小和移位操作。如果有5000个人脸样本,就可以统计样本直方图,作为人脸样本类(Cp)的条件概率。非人脸样本类(Cn)的条件概率也可以在负样本训练集上计算出来。下图是S=5时,M=3次采样实验的采样位置和对应的正负样本直方图:

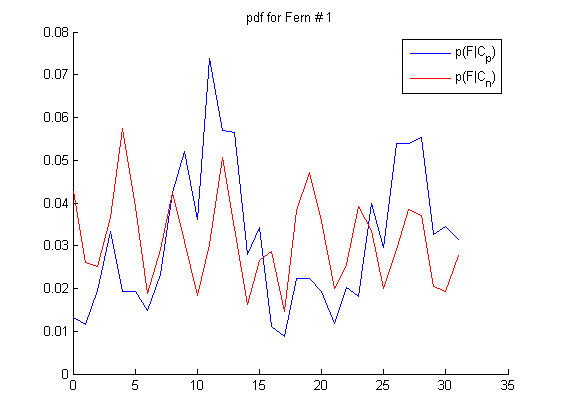
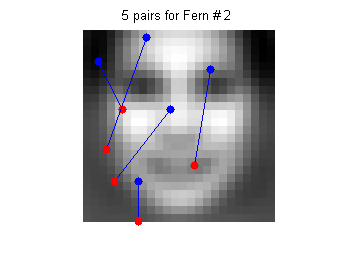
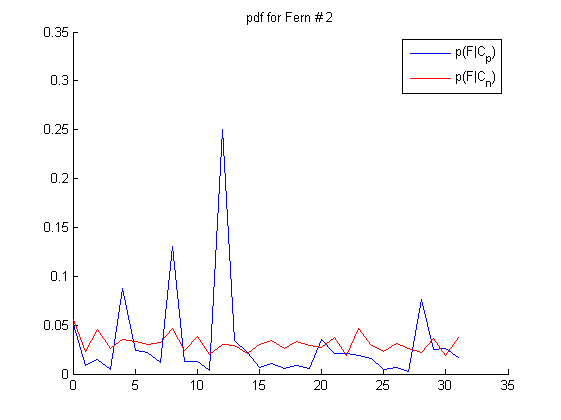
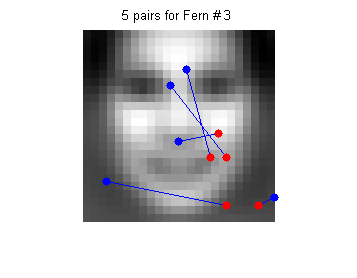
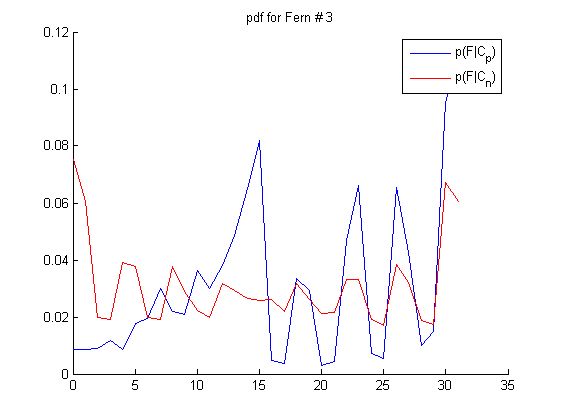
接下来的步骤和王琳之前博客介绍的人脸检测问题就一样了,以上M个特征的条件概率可以看成是独立的,样本的后验概率近似表达成M个pdf的乘积形式(Semi-Naive Bayes),P(c+|F1,F2,..FM)= P(F1,|c+)* P(F2,|c+)…P(FM,|c+)。对于人脸这样的两类问题,可以事先存储条件概率的对数似然比,这样实时检测的时候通过查表和求和就可以求出样本的置信度了。
如果把一个特征S个bit的0/1判断看作是决策树的节点,一个特征F可以看成是一个随机决策树。和决策树不同的是,它的每一层只对应一种属性的判决,就是说每层决策节点只有一个问题。2007年的CVPR论文[1]把它称为Ferns。一个具有S层的Fern只有S个属性,每个叶子节点存放样本类的条件概率;而一个决策树的每层的每个节点都对应一个不同的决策属性,叶子节点存放的往往是类别的后验概率。就像多个随机树可以组成随机森林(Random Forests)一样,多个随机Fern可以组合成Random Ferns。
样本随机采样点对,即特征的个数由单个Fern的属性数S和Fern的个数M决定,如果乘积S*M固定,则特征值的计算量就基本固定了。下面的实验是测试在S*M固定的情况下,不同配置的S和M组成的Random Ferns分类器的分类能力。S*M=128时,S分别为S=[4,6,8,12,16]的时候对应的后验概率。人脸和非人脸样本个数分别为4916和7872。
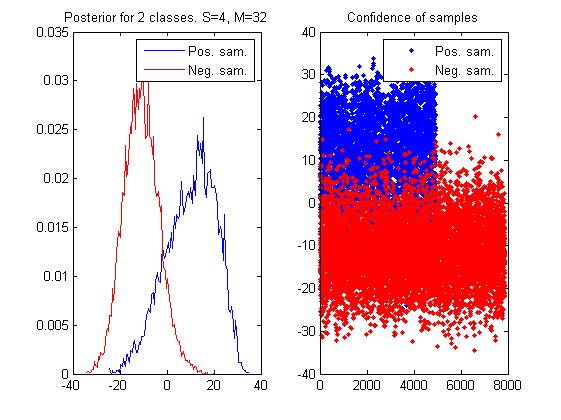


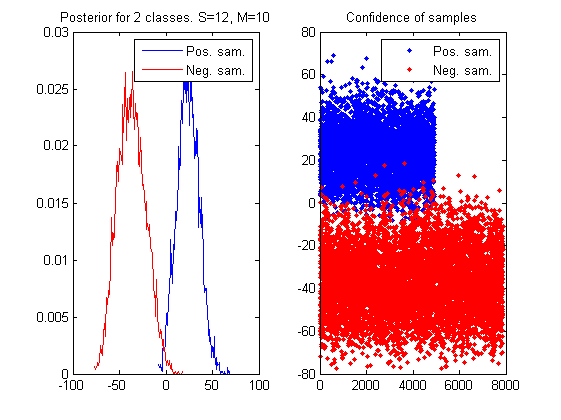

如上图所示当S增大时,两类的输出置信度直方图逐渐分开,当S=16,M=8时,两类样本完全分开了。
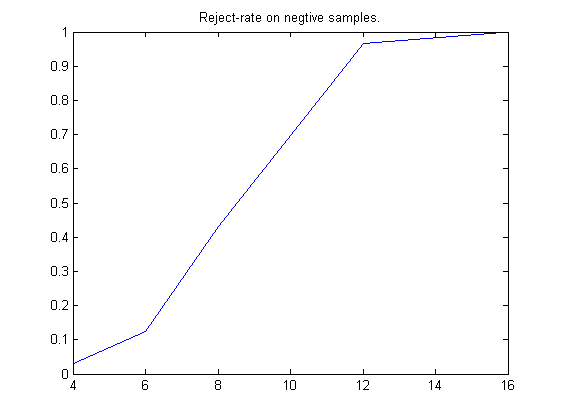
如果用Random Ferns构造Cascade Classifier分类器(目标检测器)时,希望每个Layer的分类器对在保持尽可能高的Recall能力的同时,负样本的拒绝能力也足够大。上面的实验我们把拒绝阈值设置为置信度最小的正样本输出:
[cot,idp]= sort(confp);
th = cot(1);
在负样本集上计算小于它的比率:
R_rate = sum(confn<th)/numn;
得到S=[4,6,8,12,16]时对应的拒绝率分别为[0.0288, 0.1250, 0.4323,0.9668, 0.9999]。
之所以更多的属性节点S可以得到更好的分类效果,究其原因是尽管每个图像的采样点位置的个数2*S*M是基本固定的,但是每个Fern的直方图宽度却是由N=2^S决定的。尽管上面的实验S*M=128是固定值,但是S分别为[4,6,8,12,16]时,Fern的个数M分别为[32,21,16,10,8],对应的直方图存储量(bin的个数)N*M分别是[512,1344, 4096, 40960,524288]。对于后两种情况在统计每个Fern的样本直方图的时候,bin的个数可能远远大于训练样本的个数,从而变得相当稀疏,只有少量bin的值不为0。从这个例子也可以看出,不能指望少量的训练结果参数获得好的效果。另一方面,虽然Fern特征采样的计算量一样,更多的组合N可以获得更多对分类有用的信息(更多的知识)。
当使用Fern作为分类特征时,图像采样点对是随机的,所以可以假设每个Fern之间是统计独立的。也可以通过利用RealBoost的方法,通过改变样本权重来构造更加统计不相关的Ferns。Ferns不光用在分类问题,最近也经常用于回归问题,比如基于Random Ferns的Face alignment [2],和常见的基于随机森林回归方法一样,每个特征直方图的Bin里不光记录个数还记录这个样本回归相关的shape偏移量。
利用比较像素相对大小的方法组合特征除了计算简单之外,它还具有对光照不敏感的特性。在早年Viola-Jones的人脸检测分类器中,为了消除光照的影响,对检测窗口进行灰度方差归一化处理时要使用除法。而Fern特征则不用担心这个问题。
Random Ferns中每个Fern和Fern中的属性都是随机选择的,如果每次从大量随机特征中选择最好的,可以组成Random Forest特征,比如LBF。基于Ferns和LBF的人脸检测和Alignment可以参考近两年的文章[3,4,5]。
相关文献:
[1]. Fast Keypoint Recognition inTen Lines of Code. M Ozuysal,P Fua,V Lepetit
[2]. Face Alignment by ExplicitShape Regression. Xudong Cao Yichen Wei Fang Wen Jian Sun.
(https://github.com/soundsilence/FaceAlignment)
[3].One Millisecond Face Alignment with an Ensemble of Regression Trees.Vahid Kazemi and Josephine Sullivan
[4].Face Alignment at 3000 FPS via Regressing Local Binary Features.Shaoqing Ren, Xudong Cao, Yichen Wei, and Jian Sun.
[5]. Joint Cascade Face Detection and Alignment Dong Chen, Shaoqing Ren,Yichen Wei, Xudong Cao, and Jian Sun
4-11 更新
用上述方法训练了一个6层cascade的人脸检测器,每层都是FERN的组合。对于在matlab上用不到一个小时训练出来的中间结果,还不算太差。不同图像尺度上的输出用不同的颜色表示,没有经过去噪合并等后处理:


再来一张:

https://blog.sciencenet.cn/blog-465130-964430.html
上一篇:Kinect的RGB图像和红外图像的分辨率
下一篇:meshlab查看360度全景图像