博文
人脸检测之二:提取特征
|||
在著名英语教材新概念英语第四册里,有一篇关于回声定位的文章,提到:根据回声的模式,不光能定位鱼群,而且可以知道鱼群的种类,比如青鱼,还是鳕鱼。(With experience, and with improved apparatus, it is now possible not only to locate a shoal but to tell if it is herring, cod, or other well-known fish,by the pattern of its echo.)对于深海捕鱼的实际环境,定位鱼群唯一可资利用的信息就是回声信号的pattern,对鱼群的定位和识别,实际上变成对回声模式的定位和识别。对于人脸检测和识别问题,针对人脸图像pattern来进行分析是比较廉价和实用的方法。信号模式作为原始数据,要经过特征提取和特征分类两个步骤才能得到最终结果。对信号提取有代表性的信息,即特征,把pattern从数据空间转换到特征空间进行分类是模式识别一般的工作方式。
对于图像来说,除了提取均值方差等统计学里比较常用的信息之外,更多地还要利用信号处理领域常用的卷积(模板不动就是内积)方法。图像处理教材中关于图像滤波(去噪),差分(边缘提取)等方法,以及DCT变换,傅立叶变换和小波变换等都可以看作是二维卷积方法的具体应用。比如PCA方法中使用的KL变换,就是用若干模板和图像进行内积计算(点乘),每个内积结果可以看作一个特征,它的作用是方便地提取图像的能量成分,优点是全局性好,倾向于图像表达,因为根据这些特征值很容易重建原始图像。想想视频编码所用的和KL变换相似的DCT变换吧,它们的目的在于重建而非识别。另外基于全局的方法需要每个图像点都参与计算,对一个8×8的图像来说,一次内积的计算量为64次乘法和63次加法。
所以,基于局部计算的小波(wavelet)特征的优势就比较明显了:只计算有可能产生分类效果的局部特征,如果用很少的特征能把两类模式区分开,就不必需要全体图像的参与。比如最简单的Haar小波算子,或称模板:{-1,1},它的作用是计算两个图像点的差。如果要计算两个区域的差算子可以是这样:{-1,-1-1,-1,1,1,1,1},它的作用是一个区域的和减去另一个区域的和,对于一个8×8的二维区域也需要64+1次加(减)法,如果这样的特征出现在图像的不同位置,计算量也是很大的。实际上,用积分数组可以很容易的计算。
积分数组是指一个和原始信号相同尺寸的数组,对一维信号来说,它的每个点存储的都是左边的原始信号的和。Matlab中的cumsum()函数作用就是计算积分数组。
>> x=rand(64,1);
>> xc=cumsum(x);
>> plot(x),hold on,plot(xc,'r');
信号x和它的积分数组xc结果如图:
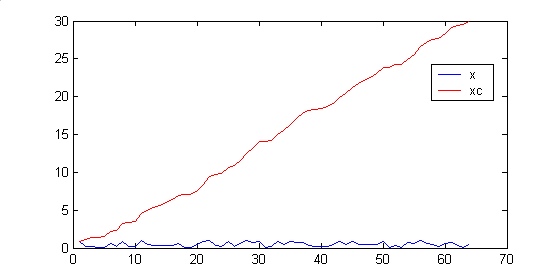
积分数组xc的作用是如果对x中任意一个区间(a,b]求和,只要计算xc上ab两点的差即可。例如计算点15到35点间的和:
>> sum(x(15:35))
ans =
10.7401
>> xc(35)-xc(14)
ans =
10.7401
对于一个2D图像im求积分数组,只要沿着图像x,y方向做两次cumsum:imc=cumsum(cumsum(im1,1),2);
im=rand(64);
imc=cumsum(cumsum(im,1),2);
imshow(im,[]);
imshow(imc,[]);
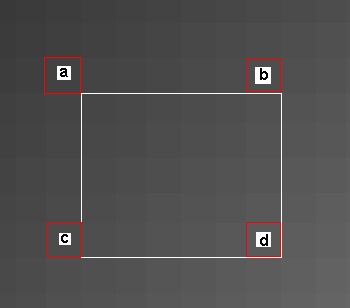
这样要求im中矩形对应的面积的话,只要在imc中计算 a+d-b-c 即可,也就是说任意大小区域的求和,只要3次加法即可实现。在viola-jones的论文中,特征定义为相邻两个(也有3个或4个)区域面积的差,称为Haar-like小波特征,可以用积分数组算法快速求得。对于一个24*24的图像样本,在不同位置计算不同尺寸、方向的Haar-like小波,这样可能的特征的数目在10万数量级。可以用一个程序穷举出文章描述的特征的各种配置(见附件),每种配置包含Haar小波的种类1-5(特征可能有2到4个矩形组成,2个和3个矩形的特征各有水平竖直2种方式),特征矩形左上角在样本中的位置的坐标,特征中单个小方块的长宽,这样每个特征需要5维矢量进行描述。10万个特征种类,我们可以事先计算好,用10万×5的矩阵存储下来。具体方法如下:
>> ft=generate_featuretype(24,[1,2,3,4,5],1,1,[1:24]);
>> size(ft)
ans =
162336 5
显示其中的若干行:
>> ft(2000:2006,:)
ans =
1 5 6 5 1
1 6 6 5 1
1 7 6 5 1
1 8 6 5 1
1 9 6 5 1
1 10 6 5 1
1 11 6 5 1
第1列表示两矩形的水平haar特征,2,3列表示左上角在24×24样本中的坐标,4,5列是一个矩形的尺寸。
实际上根据文章提供的特征描述的启发下,我们可以扩展出更多的类似两个矩形之间面积差的特征来。如果我们不限制两个矩形是“相邻”的话,需要有另外两个数来表示两个矩形之间的相对位置,这样的组合爆炸可以得到更多的特征表达。
上面提到用10万×5的矩阵存储一个表,每行是一个特征的描述,有10万个可能的特征,我们用每个特征的描述在24×24样本上都可以计算出一个特征值。假设我们有正负样本各5千,这样每个样本可以得到10万个特征值;对于单个特征类别每个特征在样本集上计算可以同样得到一个特征矢量。也就是说有这样一个表,可以把所有样本的所有特征值存储起来:

从水平方向看,它的每行对应一个样本;纵向看,它的每列对应一个特征种类在所有样本上的表现,是具有统计意义的。所谓训练,就是要利用这样庞大的2D数据,把那些能将两类样本加以区分出来的特征找出来,也就是说,从上面所说10万特征中,得到一个子集,它们最能体现出两类样本的差别。假设为了保留尽可能多的信息,我们用double型表示每个特征,那么存储量为8*1e9/1024/1024 = 7629.4 MByte,实际上可以先将数据量化,比如表示成8位unsigned char的形式,那么存储量就只有原来的1/8。另外,如果设计的最终分类器是分层结构的(应该是这样的),每层只需要提取很少的几个或几百个有用的特征,那么完全可以减少候选特征的数量;更进一步,样本数目也可以进一步减少(这样做也是有科学依据的,5k个分布均匀的样本可能和w个样本具有相同的代表性),这样上面这个表的水平竖直维数都可以大大减少,从而减少存储量。
相关文献:
[1] Viola-Jones论文 Robust Real-time Object Detection
穷举出特征计算参数配置的程序。在Viola-Jones论文中,第4页注释2提到特征数为45396个,他们的特征位置为样本图像的奇数点,所以只有全部的1/4左右。
https://blog.sciencenet.cn/blog-465130-416791.html
上一篇:人脸检测之一:样本准备
下一篇:人脸检测之三: 贝叶斯公式.概率分布