博文
Online: Encoding Words into Cloud Models, KNOWL-BASED SYST
|||
Encoding Words into Cloud Models from Interval-valued Data via Fuzzy Statistics and Membership Function Fitting
Xiaojun Yang, Liaoliao Yan, Hui Peng, Xiangdong Gao
When constructing the model of a word by collecting interval-valued data from a group of individuals, both interpersonal and intrapersonal uncertainties coexist. Similar to the interval type-2 fuzzy set (IT2 FS) used in the enhanced interval approach (EIA), the Cloud model characterized by only three parameters can manage both uncertainties. Thus, based on the Cloud model, this paper proposes a new representation model for a word from interval-valued data. In our proposed method, firstly, the collected data intervals are preprocessed to remove the bad ones. Secondly, the fuzzy statistical method is used to compute the histogram of the surviving intervals. Then, the generated histogram is fitted by a Gaussian curve function. Finally, the fitted results are mapped into the parameters of a Cloud model to obtain the parametric model for a word. Compared with eight or nine parameters needed by an IT2 FS, only three parameters are needed to represent a Cloud model. Therefore, we develop a much more parsimonious parametric model for a word based on the Cloud model. Generally a simpler representation model with less parameters usually means less computations and memory requirements in applications. Moreover, the comparison experiments with the recent EIA show that, our proposed method can not only obtain much thinner footprints of uncertainty (FOUs) but also capture sufficient uncertainties of words.
Keywords
Computing with words; Cloud model; Enhanced interval approach; Fuzzy statistics; Membership function fitting; Histogram
Framework of the Proposed Method
Step 1: Data collection.
The datasets introduced in “D. Wu, J. M. Mendel, and S. Coupland, “Enhanced Interval Approach for Encoding Words Into Interval Type-2 Fuzzy Sets and Its Convergence Analysis,” IEEE Transactions on Fuzzy Systems, vol. 20, no. 3, pp. 499-513, Jun. 2012” are used in our research.
Step2: Data preprocessing.
1) Bad data processing
2) Outlier processing
3) Tolerance limit processing
4) Reasonable-interval processing
Step3: Fuzzy statistics of data intervals.
The fuzzy statistics is to compute the histogram of the m intervals. (Fig. 4, red solid curve)
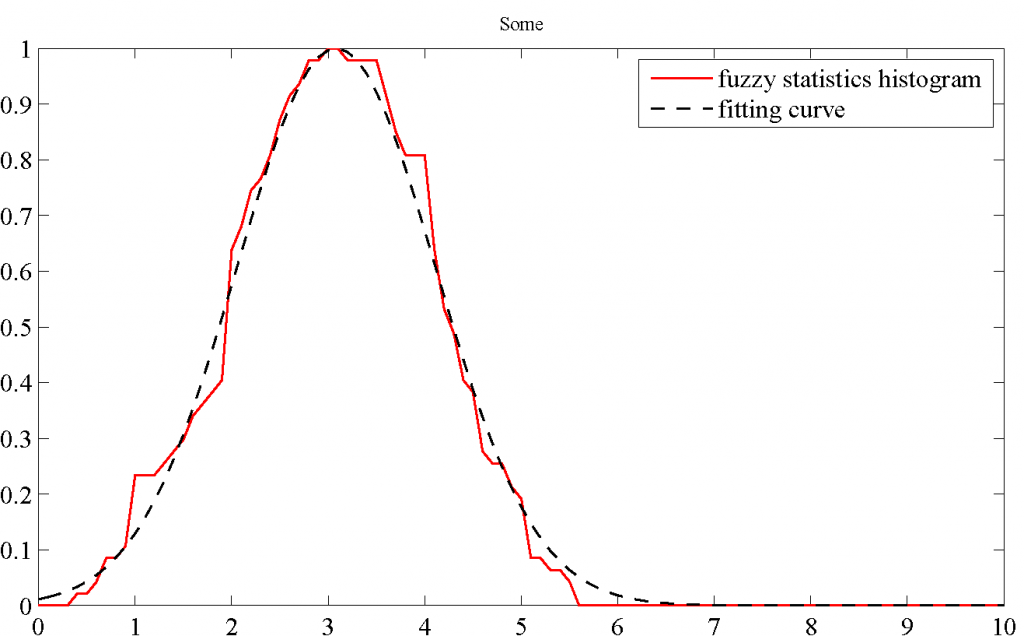
Fig. 4. The fuzzy statistics histogram and fitting curve of the word “Some”.
Step4: MF fitting using Gaussian curve function.
The fuzzy statistical histogram obtained in Step 3 can be considered as the MF of the fuzzy opinions of a word. Nevertheless, in some situations such as in applications of CWW, the obtained fuzzy opinions may be manipulated later in arithmetic operations. In these cases, mathematically explicit and continuous forms of MFs may be a necessity.
In order to develop a more parsimonious parametric model for a word, we fit the fuzzy statistical histogram data (xs, m(xs)) obtained in Step 3 using Gaussian curve function. (Fig. 4, black dashed curve)
Step5: Representation of a word by a Cloud model.
To handle the uncertainties of a word, we choose the Cloud model with the minimum number of parameters that best approximates the data to represent a word, so as to obtain a more parsimonious parametric model for a word. (Fig.5)

Fig. 5. The representation of the word “Some” by a Cloud model.
Experimental Results

Fig. 6. The fuzzy statistics histograms (red curves) and fitted curves (black curves) of all 32 words.

Fig. 7. The resulting Cloud models of all 32 words.

Fig. 10. The area (light-colored shaded area) and error (dark shaded areas) of the word “A lot”. The sum of dark shaded areas is defined as the error of an FOU. (a) The result of EIA, (b) the result of our proposed method.

Fig. 11. The areas and errors of the IT2 FS FOUs for all 32 words obtained by the EIA.

Fig. 12. The areas and errors of the Cloud model FOUs for all 32 words obtained by our proposed method.
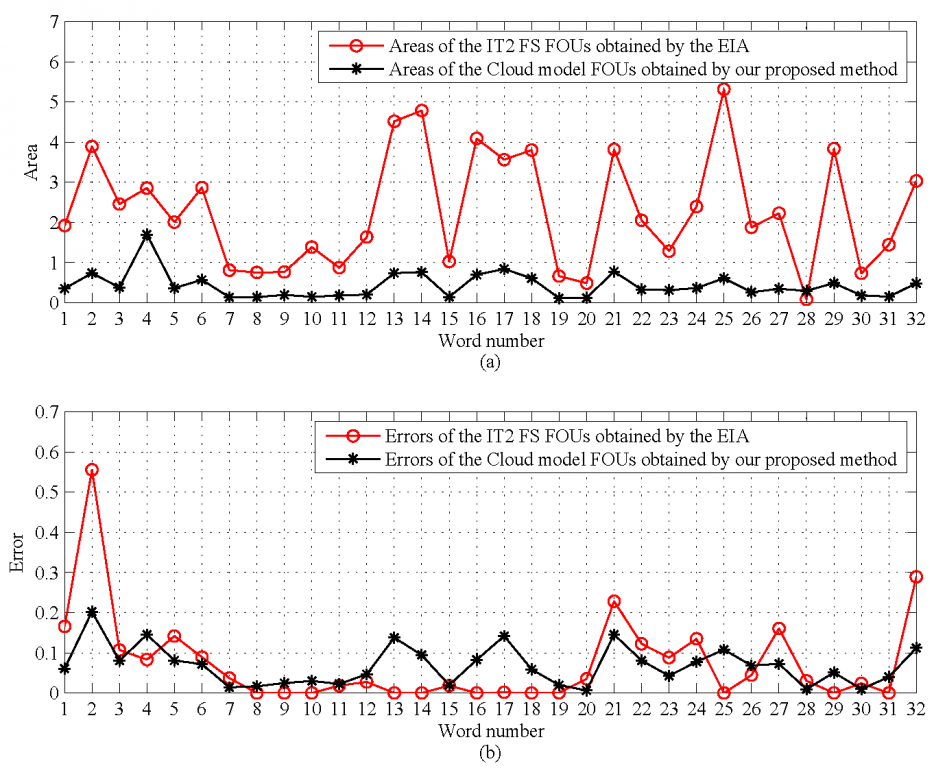
Fig. 13. The visualized comparisons of the areas and errors between the EIA and our proposed method for all 32 words. (a) The areas, (b) the errors.
Discussions and Conclusion
Based on the Cloud model, we have developed a more parsimonious parametric model for a word from interval data. From the experimental results, we have observed that the proposed method can result in much thinner FOUs.
1) The representation of a Cloud model FOU is simpler than that of an IT2 FS FOU. It only needs three parameters to define a Cloud model FOU, whereas an IT2 FS FOU needs eight or nine parameters. “Generally a MF shape with simpler representation is preferred, especially when the parameters of the MF need to be optimized, because simpler representation usually means faster convergence”. Therefore, we should obtain a parsimonious parametric model with the minimum number of parameters that best approximates the data for a word.
2) The Cloud model FOUs are much thinner than the IT2 FS FOUs. Thinner FOUs may represent a more desirable tradeoff between uncertainty and accuracy, and thinner FOUs can be used to better distinguish close words . Experimental results show that the Cloud model FOUs for words are not only much thinner but also can capture sufficient uncertainties. The reason may be that, we approximate the fuzzy statistical histograms of the words using the Cloud models directly in our proposed method, while in the IA and EIA, each person’s data interval is assumed to be uniformly distributed but later a symmetrical triangle T1 MF, a left-shoulder T1 MF, or a right-shoulder T1 MF is used to approximate a uniformly distributed data interval.
Constructing the models of words is the first step in the CWW paradigm. In this paper we have proposed a method of encoding words into Cloud models from interval-valued data usingfuzzy statistics and MFfitting. Similar to the IT2 FS, the Cloud model is able to represent both interpersonal and intrapersonal uncertainties about collecting word data from a group of individuals. Based on the Cloud model, we have developed a more parsimonious parametric model for a word. The experimental results show that our proposed method can not only result in much thinner FOUs but also capture sufficient uncertainties of words. Thus, the Cloud model may be a suitable model for a word, and this may explore another efficient way in the CWW and the representation of human knowledge and perceptions.
Future researches will be concerned with constructing the system of CWW using Cloud models.
Access this article:
Knowledge-Based Systems, Available online 19 October 2013
http://www.sciencedirect.com/science/article/pii/S0950705113003250#f0020
http://dx.doi.org/10.1016/j.knosys.2013.10.014
https://blog.sciencenet.cn/blog-431053-735217.html
上一篇:一篇论文被Knowledge-Based Systems录用(附详细投稿历程)
下一篇:Elsevier 提供50天的免费下载