博文
PostgreSQL9.1 Warm-Standby ---之基于拷贝WAL文件的方法
|||
本教程是PostgreSQL Cluster系列教程的一部分,该系列包括:
PostgreSQL9.1 PITR示例 (该教程主要阐述DBA如何基于WAL日志做备份恢复)
PostgreSQL9.1 Warm-Standby ---之基于拷贝WAL文件的方法 (file-based log shipping)
PostgreSQL9.1 Warm-Standby ---之基于流复制的方法 (streaming replication)
PostgreSQL9.1 Warm-Standby ---之基于同步复制的方法 (Synchronous Replication)
PG9.1+pgpool-II3.1--之Load Balancing (when meeting large amounts of requests)
PG9.1+pgpool-II3.1--之Parallel Query (when meeting large amounts of data)
PostgreSQL9.1 HA --- 之Slony
好了,有了第一个教程,我们终于等来了高可用性(High Availability,HA)的介绍。
说到HA,我们不得不提提Fault Tolerance,为什么这么说呢,这是因为Availablity肯定是和Unavailability对应,那为什么会有Unavailability呢,那是因为有许多Fault,包括硬件的和软件的,所以我们得先从Fault Tolerance说起。
先来看看Fault Tolerance概念,按照传统,看看WIKI上的定义:
Fault-tolerance or graceful degradation is the property that enables a system (often computer-based) to continue operating properly in the event of the failure of (or one or more faults within) some of its components. 哦,简单来说,就是系统有了failure了,还能继续运行。
搞学术的人总想从历史的角度来寻找Fault Tolerance的出处,我们再看看1978年BRIAN RANDELL在其论文“System Structure for Software Fault Tolerance”中的解释:
The concept of “fault-tolerant computing” has existed for a long time. The first book on the subject [10] ([10] W. H. Pierce, Failure-Tolerant Computer Design. New York: Academic, 1965,此处我给补充)was published no less than ten years ago, but the notion of fault tolerance has remained almost exclusively the preserve of the hardware designer. Hardware structures have been developed which can “tolerate” faults, i.e., continue to provide the required facilities despite occasional failures, either transient or permanent, of internal components and modules.
所以我们从上面来看,Fault Tolerance的理念至少在计算机出现的早期(1965年之前)就有了,在硬件设计时是必须考虑的。咱们不扯多了(有兴趣的朋友,可以多写写),接下来的问题是HA和Fault Tolerance又是什么关系?我们再来看看YENNUN HUANG, CHANDRA KINTALA在1995年的论文Software Fault Tolerance in the Application Layer中所写的一段描述:
From a user’s point of view, fault tolerance has two dimensions: availability and data consistency of the application. For example, users of telephone switching systems demand continuous availability whereas bank teller machine customers demand the highest degree of data consistency. Safety critical real-time systems such as nuclear power reactors and flight control systems need highest levels in both availability and data consistency. Most other applications have lower degrees of requirements for fault-tolerance in both dimensions; see Figure 10.1(这里我把这个图截下来,供大家看看)。
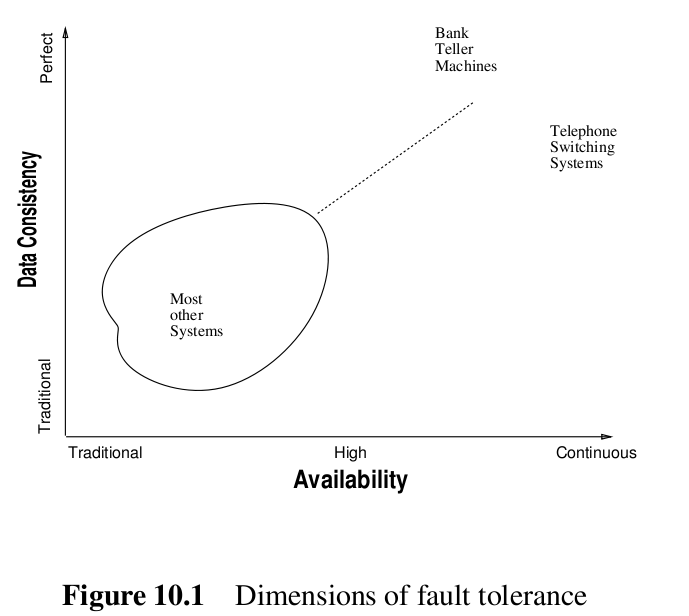
上面的话的意思是从用户的角度来看, fault tolerance有两个方面,一个是可用性(availability),一个是数据一致性(data consistency)。有些应用可能注重高的数据一致性,例如银行柜台机( bank teller machine),有些应用可能注重高的可用性,如电话交换系统(telephone switching system),有的二者都要求高,如核电厂和飞行控制系统(nuclear power reactors , flight control system)。
怎么样,HA和 fault tolerance的关系明白了吧。下面列出一些参考资料,有兴趣的朋友可以继续深入下去。
wiki: High Availability
James A. Katzman,Tandem 16: A Fault-Tolerant Computing System
BRIAN RANDELL,System Structure for Software Fault Tolerance
Jim Grey, High-Availability Computer Systems
Flavin Cristian,Understanding fault-tolerant distributed systems
Mary Baker, Mark Sullivan, The Recovery Box: Using Fast Recovery to Provide High Availability in the UNIX Environment
Hui-I Hsiao,A Performance Study of Three High Availability Data Replication Strategies
http://h20223.www2.hp.com/nonstopcomputing/cache/76385-0-0-0-121.html
好了,我们大体明白了什么是HA之后,那如果我们做HA的话需要做什么呢?根据Jim Grey的High-Availability Computer Systems中描述的:High availability requires systems designed to tolerate faults to detect a fault, report it, mask it, and then continue service while the faulty component is repaired off line. 这就要求我们需要探测一个故障(fault),报告,屏蔽并在离线修复该故障时继续提供有效的服务。
关于fault,我们多说两句,那到底有什么故障呢,哪些故障最容易出现,根据Mary Baker, Mark Sullivan, The Recovery Box: Using Fast Recovery to Provide High Availability in the UNIX Environment,提到的一张表,如下: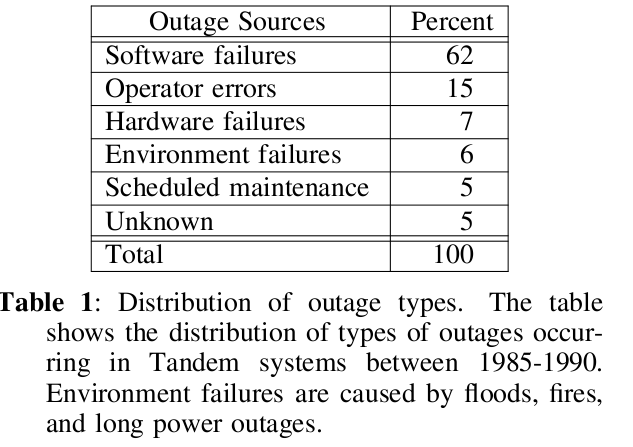
其中谈到In 1990, software errors accounted for 62% of Tandem system failures, while only 7% were caused by hardware. 即软件错误在1990年的Tandem系统中占了62%(有谁能给我一个现在fault发生率的报告?多谢)。虽然我们这里不去过多的探讨硬件具有Fault Tolerance的计算机,但是还是列出一些,如1950–1954 年建的SAPO恐怕是第一台具有Fault Tolerance的计算机,以及让Fault Tolerance深入人心的Tandem Computer(参阅FAULT-TOLERANT COMPUTING,第3页)。
为了简化本文,关于HA的基础就到此为止,下面看看如何使用warm-standby(基于拷贝WAL文件的方法)来实施HA。首先我们来看看warm-standby的含义,根据http://www.postgresql.org/docs/9.1/interactive/high-availability.html,其中的一段话:
Servers that can modify data are called read/write, master or primary servers. Servers that track changes in the master are called standby or slave servers. A standby server that cannot be connected to until it is promoted to a master server is called a warm standby server, and one that can accept connections and serves read-only queries is called a hot standby server.
从中我们知道,warm-standby在系统出现fault的时候,可以提升为master,即可以接受客户端的connect连接,并提供数据库的读写,角色如同一个master一样。而根据25.5的说明(如下),hot-standby则在为archive recovery 或 standby mode时,只能接受可读的query。
Hot Standby is the term used to describe the ability to connect to the server and run read-only queries while the server is in archive recovery or standby mode. This is useful both for replication purposes and for restoring a backup to a desired state with great precision(这一句什么意思?).
尽管,网上还有一些关于cold/warm/hot server的定义,如这和这儿,为保持本文的简易性,此处不再详细分析这些概念上的区别(感兴趣的朋友可以继续深入研究)。
好,那接下来我们看看warm-standby的原理,下面几张图截自Getting ready for PostgreSQL 9.1,第28,29和30页:
正常运行时:
Failover时: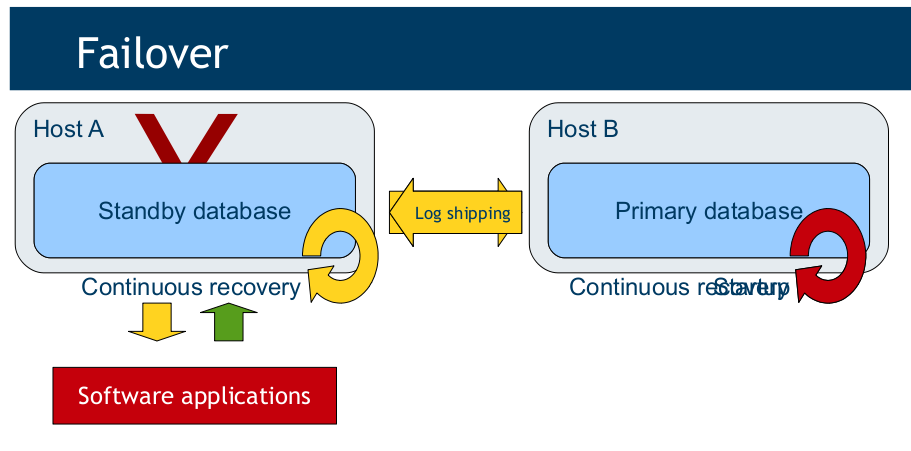
Switchover时: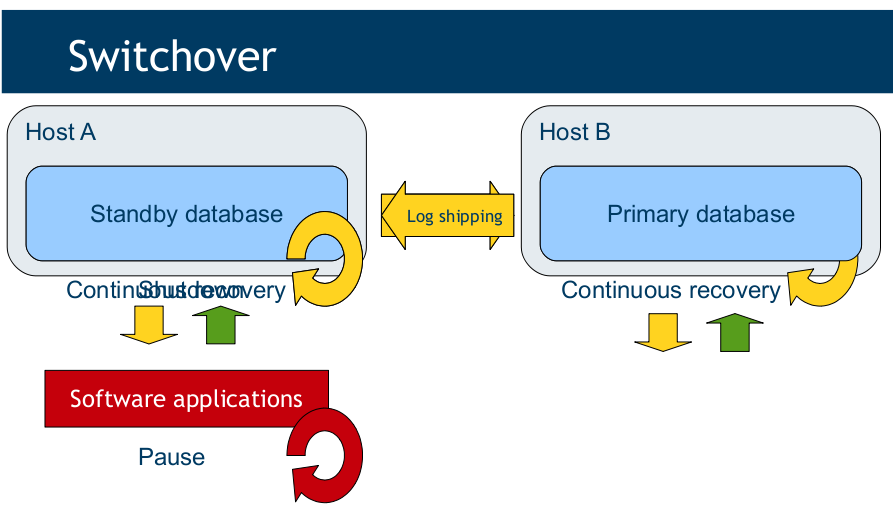
之所以列出这三张图,就是想分析分析,我们需要PostgreSQL配置哪些内容,以支持这三项(正常运行/Failover/Switchover)。首先我们对环境说明一下:
/home/postgres/db/master/pgsql 目录是master数据库的目录,端口为5432
/home/postgres/db/standby/pgsql 目录是一台standy数据库的目录,端口为6432
/home/postgres/archive 是master->standby的WAL日志中转地点
/home/postgres/archive_failover/ 是Switchover阶段standby->master的WAL日志中转地点
/home/postgres/base 是master->standby的基础备份库的目录
/home/postgres/trigger 使用pg_standby的trigger文件存放处
关于上面的第1点,我们在教程一(PostgreSQL9.1 PITR示例)里已经说过如何安装了(但是这里有一点不同的是我们将使用PostgreSQL的扩展模块 pg_standby,所以编译和安装时稍微不同,请参考:15.4. Installation Procedure),并生成了100万条数据,即执行了:
[postgres@localhost ~]$ cd /home/postgres/develop/
[postgres@localhost ~]$ rm -fr postgresql-9.1.2
[postgres@localhost ~]$ tar zxf postgresql-9.1.2.tar.gz
[postgres@localhost ~]$ cd postgresql-9.1.2
[postgres@localhost ~]$ ./configure --prefix=/home/postgres/db/master/pgsql --with-includes=/usr/local/readline/include --with-libraries=/usr/local/readline/lib
[postgres@localhost ~]$ make world
[postgres@localhost ~]$ make install-world
[postgres@localhost ~]$ /home/postgres/db/master/pgsql/bin/initdb -D /home/postgres/db/master/pgsql/data
[postgres@localhost ~]$ /home/postgres/db/master/pgsql/bin/postmaster -D /home/postgres/db/master/pgsql/data
[postgres@localhost ~]$ /home/postgres/db/master/pgsql/bin/createdb mydb
[postgres@localhost ~]$ /home/postgres/db/master/pgsql/bin/psql mydb
mydb=# create table foo(id bigint);
mydb=# insert into foo select * from generate_series(1,1000000);
关于第2点,类似于第1点,只是端口(我们把默认的端口5432改为6432,以和master区别开来)不同,这里简要列一个安装步骤:
[postgres@localhost ~]$ cd /home/postgres/develop/
[postgres@localhost ~]$ rm -fr postgresql-9.1.2
[postgres@localhost develop]$ tar zxf postgresql-9.1.2.tar.gz
[postgres@localhost develop]$ cd postgresql-9.1.2
[postgres@localhost develop]$ ./configure --prefix=/home/postgres/db/standby/pgsql --with-includes=/usr/local/readline/include --with-libraries=/usr/local/readline/lib --with-pgport=6432
[postgres@localhost ~]$ make world
[postgres@localhost ~]$ make install-world
[postgres@localhost develop]$ /home/postgres/db/standby/pgsql/bin/initdb -D /home/postgres/db/standby/pgsql/data
然后修改postgresql.conf:port = 6432,保存。
[postgres@localhost develop]$ /home/postgres/db/standby/pgsql/bin/postmaster -D /home/postgres/db/standby/pgsql/data
[postgres@localhost develop]$ /home/postgres/db/standby/pgsql/bin/createdb mydb --port=6432
好,最后查看一下是否安装成功:
[postgres@localhost develop] $ /home/postgres/db/standby/pgsql/bin/psql mydb --port=6432
(A)接下来我们就看看正常运行下,如何配置master和standby数据库(注意:写到这里你可以动手操作了):
master的postgresql.conf中三个参数:
wal_level = archive
archive_mode = on
archive_command = 'cp %p /home/postgres/archive/%f'
并参考第一篇PostgreSQL9.1 PITR示例对master做一次基础备份( base backup,基础备份data目录):
mydb=# SELECT pg_start_backup('bak20120218');
[postgres@localhost pgsql]$ cd /home/postgres/db/master/pgsql/
[postgres@localhost pgsql]$ tar czvf /home/postgres/base/base_data.tar.gz data/
mydb=# SELECT pg_stop_backup();
mydb=# select pg_switch_xlog();
由于刚安装的standy数据库此时什么都没有,而master可能已经运行了一段时间,这就需要对standy数据库的data目录使用上面基础备份的data目录覆盖:
[postgres@localhost pgsql]$ cd /home/postgres/db/standby/pgsql/
[postgres@localhost pgsql]$ mv data data_bk
[postgres@localhost pgsql]$ tar -xzvf /home/postgres/base/base_data.tar.gz
[postgres@localhost pgsql]$ rm -r data/pg_xlog/
[postgres@localhost pgsql]$ mkdir -p data/pg_xlog/archive_status
[postgres@localhost pgsql]$ rm data/postmaster.pid
[postgres@localhost pgsql]$ cp /home/postgres/db/standby/pgsql/share/recovery.conf.sample /home/postgres/db/standby/pgsql/data/recovery.conf
[postgres@localhost pgsql]$ cp /home/postgres/db/standby/pgsql/data_bk/postgresql.conf /home/postgres/db/standby/pgsql/data/postgresql.conf
然后配置standy让它处于一直接收WAL日志的standby_mode状态,即修改recovery.conf文件(参考:25.2.4 Setting Up a Standby Server):(注意没有使用:restore_command = 'cp /home/postgres/archive/%f %p',当然使用这个命令我测试过也可以,但此处使用了更为强大的postgresql的扩展pg_standby,关于如何使用pg_standby,请参阅F.31. pg_standby)
standby_mode = on
restore_command = '/home/postgres/db/standby/pgsql/bin/pg_standby -d -s 2 -t /home/postgres/trigger/pgsql.trigger.6432 /home/postgres/archive %f %p %r'
recovery_end_command = 'rm -f /home/postgres/trigger/pgsql.trigger.6432'
好,重启standby数据库(之前请先启动master库),看看是否成功:
[postgres@localhost pgsql]$ /home/postgres/db/standby/pgsql/bin/postmaster -D /home/postgres/db/standby/pgsql/data --port=6432
LOG: database system was interrupted; last known up at 2012-02-22 17:35:21 CST
LOG: entering standby mode
Trigger file: /home/postgres/trigger/pgsql.trigger.6432
Waiting for WAL file: 000000010000000000000006
WAL file path: /home/postgres/archive/000000010000000000000006
Restoring to: pg_xlog/RECOVERYXLOG
Sleep interval: 2 seconds
Max wait interval: 0 forever
Command for restore: cp "/home/postgres/archive/000000010000000000000006" "pg_xlog/RECOVERYXLOG"
Keep archive history: 000000000000000000000000 and later
running restore : OK
LOG: restored log file "000000010000000000000006" from archive
LOG: redo starts at 0/6000070
LOG: consistent recovery state reached at 0/7000000
Trigger file: /home/postgres/trigger/pgsql.trigger.6432
Waiting for WAL file: 000000010000000000000007
WAL file path: /home/postgres/archive/000000010000000000000007
Restoring to: pg_xlog/RECOVERYXLOG
Sleep interval: 2 seconds
Max wait interval: 0 forever
Command for restore: cp "/home/postgres/archive/000000010000000000000007" "pg_xlog/RECOVERYXLOG"
Keep archive history: 000000010000000000000006 and later
WAL file not present yet. Checking for trigger file...
WAL file not present yet. Checking for trigger file...
若是,则成功。
当然您可以分别通过如下命令来看master和standby的状态:
看master:
/home/postgres/db/master/pgsql/bin/pg_controldata /home/postgres/db/master/pgsql/data
是否Database cluster state: in production ?
看standby:
/home/postgres/db/standby/pgsql/bin/pg_controldata /home/postgres/db/standby/pgsql/data
是否Database cluster state: in archive recovery?
当然您可以继续在master里插入一些新的数据,以检验看看standby的服务端是不是几乎同时在用WAL日志恢复。
(B)接下来进入Failover阶段情况下如何配置,在Failover时,master由于某种原因down掉,您可以通过发出下述指令来关闭(根据德哥的经验,见这里,千万不要用-m immediate来数据库):
[postgres@localhost pgsql]$ /home/postgres/db/master/pgsql/bin/pg_ctl stop -m fast -D /home/postgres/db/master/pgsql/data
确定master关机后,然后我们需要首先在提升standby为master之前做一些准备,即修改standby的postgresql.conf中三个参数(一定要注意我们新增了archive_failover目录),此时配置的目的是让后面Switchover阶段时,原来的master可以使用新master的日志:
wal_level = archive
archive_mode = on
archive_command = 'cp %p /home/postgres/archive_failover/%f'
然后准备提升standby为master,即:
在trigger目录下创建pgsql.trigger.6432文件,文件内容为空(当然也可以写smart),[postgres@localhost pgsql]$ cat > pgsql.trigger.6432
[postgres@localhost pgsql]$ /home/postgres/db/standby/pgsql/bin/pg_ctl promote -D /home/postgres/db/standby/pgsql/data (注意: promote命令发出后,可能要等一会(十几秒钟)才能让standby切换成master)
然后重新启动新的master库(即原来的promote之后的standby库),以让postgresql.conf生效。
然后维护master库,把fault修正后,进入下一阶段。
(C)Switchover阶段,这个时候原来的master需要重新启动为standby模式,此时配置原来的master和原来的standby一样。步骤为:
把新master做一次基础备份(基础备份data目录):
[postgres@localhost pgsql]$ /home/postgres/db/standby/pgsql/bin/createdb mydb --port=6432
mydb=# SELECT pg_start_backup('bak20120220');
[postgres@localhost pgsql]$ cd /home/postgres/db/standby/pgsql/
[postgres@localhost pgsql]$ tar czvf /home/postgres/base/base_data_switchover.tar.gz data/
mydb=# SELECT pg_stop_backup();
mydb=# select pg_switch_xlog();
然后拷贝到老master那里:
[postgres@localhost pgsql]$ cd /home/postgres/db/master/pgsql/
[postgres@localhost pgsql]$ mv data data_bk
[postgres@localhost pgsql]$ tar -xzvf /home/postgres/base/base_data_switchover.tar.gz
[postgres@localhost pgsql]$ rm -r data/pg_xlog/
[postgres@localhost pgsql]$ mkdir -p data/pg_xlog/archive_status
[postgres@localhost pgsql]$ rm data/postmaster.pid
[postgres@localhost pgsql]$ cp /home/postgres/db/master/pgsql/data_bk/postgresql.conf /home/postgres/db/master/pgsql/data/postgresql.conf
然后把postgresql.conf下面的几行都注释掉:
#wal_level = archive
#archive_mode = on
#archive_command = 'cp %p /home/postgres/archive_failover/%f'
并为原有的master新建recovery.conf文件,内容和原来的standby的recovery.conf文件类似(只是使用不同的/home/postgres/archive_failover/目录,trigger也变为/home/postgres/trigger/pgsql.trigger.5432):
standby_mode = on
restore_command = '/home/postgres/db/master/pgsql/bin/pg_standby -d -s 2 -t /home/postgres/trigger/pgsql.trigger.5432 /home/postgres/archive_failover %f %p %r'
recovery_end_command = 'rm -f /home/postgres/trigger/pgsql.trigger.5432'
然后启动原master,此时以standby模式运行:
[postgres@localhost develop]$ /home/postgres/db/master/pgsql/bin/postmaster -D /home/postgres/db/master/pgsql/data
查看是否一切正常。即你在新的master里做DML如插入新数据操作时,在新的standby里是否看到在用日志恢复。
(D)如果有必要,我们再来一次主库和备库角色切换的操作(推荐,但此处不再演示)。即关闭新主库,激活老主库。
写到这里你可能还有一些疑问,应用服务器有什么机制可以探测master down掉?有没自动化工具来对Failover和Switchover阶段自动执行?PostgreSQL9.1的25.3. Failover中只是简单的说明了一下,本身不是很详细,本文不再讨论,有兴趣的朋友可以专门写写。
至此完毕。
参考:
[1] PostgreSQL 9.1 Allow standby recovery to switch to a new timeline automatically
[2] Postgresql 9.0 Replication - Step by Step ,看不到该文的,请看转载
[3] http://blog.chinaunix.net/link.php?url=http://www.pgcon.org%2F2008%2Fschedule%2Fevents%2F76.en.html
[4] Instagram 架构分析笔记
加我私人微信,交流技术。

https://blog.sciencenet.cn/blog-419883-539178.html
上一篇:PostgreSQL9.1 PITR示例
下一篇:PostgreSQL9.1 Warm-Standby ---之基于流复制的方法