来源:选自Google Cloud 作者:Kaz Sato
https://www.sohu.com/a/251830032_458015
机器之心编译 参与:思源、刘晓坤
很多读者可能分不清楚 CPU、GPU 和 TPU 之间的区别,因此 Google Cloud 将在这篇博客中简要介绍它们之间的区别,并讨论为什么 TPU 能加速深度学习。

张量处理单元(TPU)是一种定制化的 ASIC 芯片,它由谷歌从头设计,并专门用于机器学习工作负载。TPU 为谷歌的主要产品提供了计算支持,包括翻译、照片、搜索助理和 Gmail 等。Cloud TPU 将 TPU 作为可扩展的云计算资源,并为所有在 Google Cloud 上运行尖端 ML 模型的开发者与数据科学家提供计算资源。在 Google Next’18 中,我们宣布 TPU v2 现在已经得到用户的广泛使用,包括那些免费试用用户,而 TPU v3 目前已经发布了内部测试版。

第三代 Cloud TPU

如上为 tpudemo.com 截图,该网站 PPT 解释了 TPU 的特性与定义。在本文中,我们将关注 TPU 某些特定的属性。
神经网络如何运算
在我们对比 CPU、GPU 和 TPU 之前,我们可以先了解到底机器学习或神经网络需要什么样的计算。如下所示,假设我们使用单层神经网络识别手写数字。

如果图像为 28×28 像素的灰度图,那么它可以转化为包含 784 个元素的向量。神经元会接收所有 784 个值,并将它们与参数值(上图红线)相乘,因此才能识别为「8」。其中参数值的作用类似于用「滤波器」从数据中抽取特征,因而能计算输入图像与「8」之间的相似性:
然后,TPU 从内存加载数据。当每个乘法被执行后,其结果将被传递到下一个乘法器,同时执行加法。因此结果将是所有数据和参数乘积的和。在大量计算和数据传递的整个过程中,不需要执行任何的内存访问。

这就是为什么 TPU 可以在神经网络运算上达到高计算吞吐量,同时能耗和物理空间都很小。
好处:成本降低至 1/5
因此使用 TPU 架构的好处就是:降低成本。以下是截至 2018 年 8 月(写这篇文章的时候)Cloud TPU v2 的使用价格。
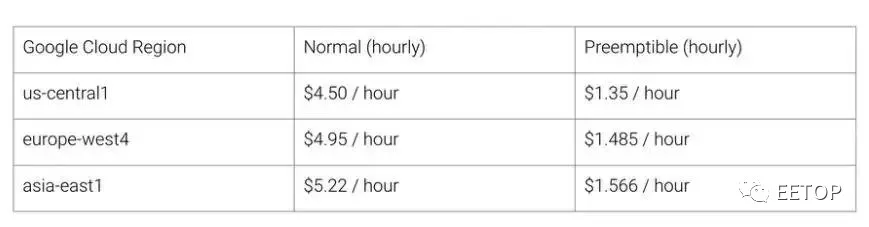
Cloud TPU v2 的价格,截至 2018 年 8 月。
斯坦福大学发布了深度学习和推理的基准套装 DAWNBench。你可以在上面找到不同的任务、模型、计算平台以及各自的基准结果的组合。
DAWNBench:https://dawn.cs.stanford.edu/benchmark/
在 DAWNBench 比赛于 2018 年 4 月结束的时候,非 TPU 处理器的最低训练成本是 72.40 美元(使用现场实例训练 ResNet-50 达到 93% 准确率)。而使用 Cloud TPU v2 抢占式计价,你可以在 12.87 美元的价格完成相同的训练结果。这仅相当于非 TPU 的不到 1/5 的成本。这正是神经网络领域特定架构的威力之所在。