博文
关于Meta分析,你需要了解的十个技术问题
||
Meta分析,是对以往研究案例进行定量化分析,得到普遍性结论,同时发现新问题,新格局的一项重要统计手段。过去40年,meta分析技术不断进步,在几乎各个学科,尤其是生物学领域得到了前所未有的广泛应用。但是由于不同的科研人员对Meta概念、理论和方法的理解和统计背景各有不同,导致这一方法遭到了一定程度上误用和滥用。2018年3月8日,Nature 杂志专门发表综述文章,呼吁采用标准化流程进行meta分析,对相关科研人员进行高标准的Meta分析技能培训(Gurevitch et al., 2018),以确保研究结果的可靠性。那么我们在开展Meta分析时,应该注意哪些技术问题呢?
著名应用统计学家Nakagawa Shinichi于2017年在BMC biology杂志上撰文,指出了Meta中应注意的十大问题(Nakagawa et al., 2017)。值得一提的是Nakagawa Shinichi大师的另一经典之作是在2013年发表了混合效应模型R2的计算方法(Nakagawa & Schielzeth, 2013),这一方法由于其原理清晰,计算简单已获得广泛认可。 据google scholar 统计,该论文截至目前已被引用5300多次。本文试图简要的对Meta分析中应当注意的十大问题进行介绍,以期对大家有所帮助。
1、文献检索过程是否透明、可重复?
一般文献的搜索过程会以PRISMA(Preferred Reporting Items for Systematic Reviews and Meta-Analyses)图的形式呈现,告诉读者,你以什么为关键词,在哪个数据库里搜索,得到多少篇文献,然后经过层层筛选,最终保留了多少篇文献。PRISMA图的造型一般如下:
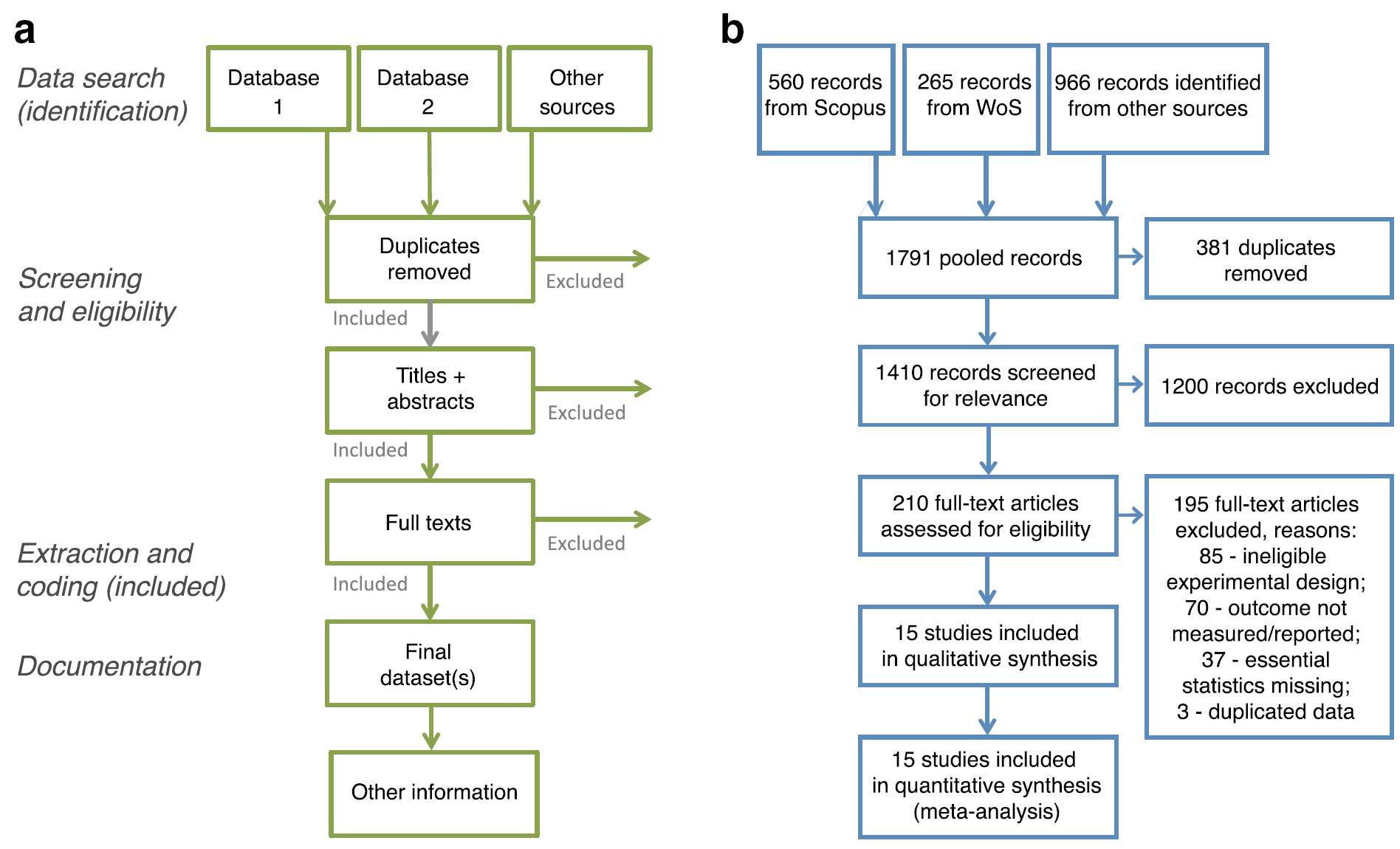
通过这个流程图,读者至少可以从文献检索上,来重现你的结果,从而验证你的结果是否可重复。
2、你的科学问题的类型和采用的效应值是什么?
Meta分析的问题一般有两类:
1)某处理对某指标Y到底有没有影响?(如吃某药到底能否治某病)
2)某变量x与某指标y到底有没有关系(如降雨和生产力之间有无关系)?
所谓效应值,就是反映某处理对某指标Y的影响程度,或者变量X和Y之间的相关程度的指标。针对不同的问题和数据类型,要选取合适的效应值。
效应值通常分为三类:
1)反应处理组和对照组间原始数据均值的标准化差异度:Cohen’s g, Hedges’ g, 或Hedges’ d,或消除量纲后的处理组与对照组差异程度:log response ratio;
2)相关系数,或先把各种统计量(F值,卡方值等)先转化为Fisher’s Z, 然后再将Fisher’s Z转化为相关系数r, 以r作为效应值。
3)某一时间发生率的比值(如病人康复率), 如 Odds ratio, relative risk 等等
3、数据是否存在嵌套或者分层结构?
嵌套或分层通常指某些数据来自于同一个取样小单元,某些小单元嵌套在大的取样单元下,而来自同一个单元的数据往往彼此不独立,这就违反数据分析的前提假设。比如常见的嵌套结构如下:
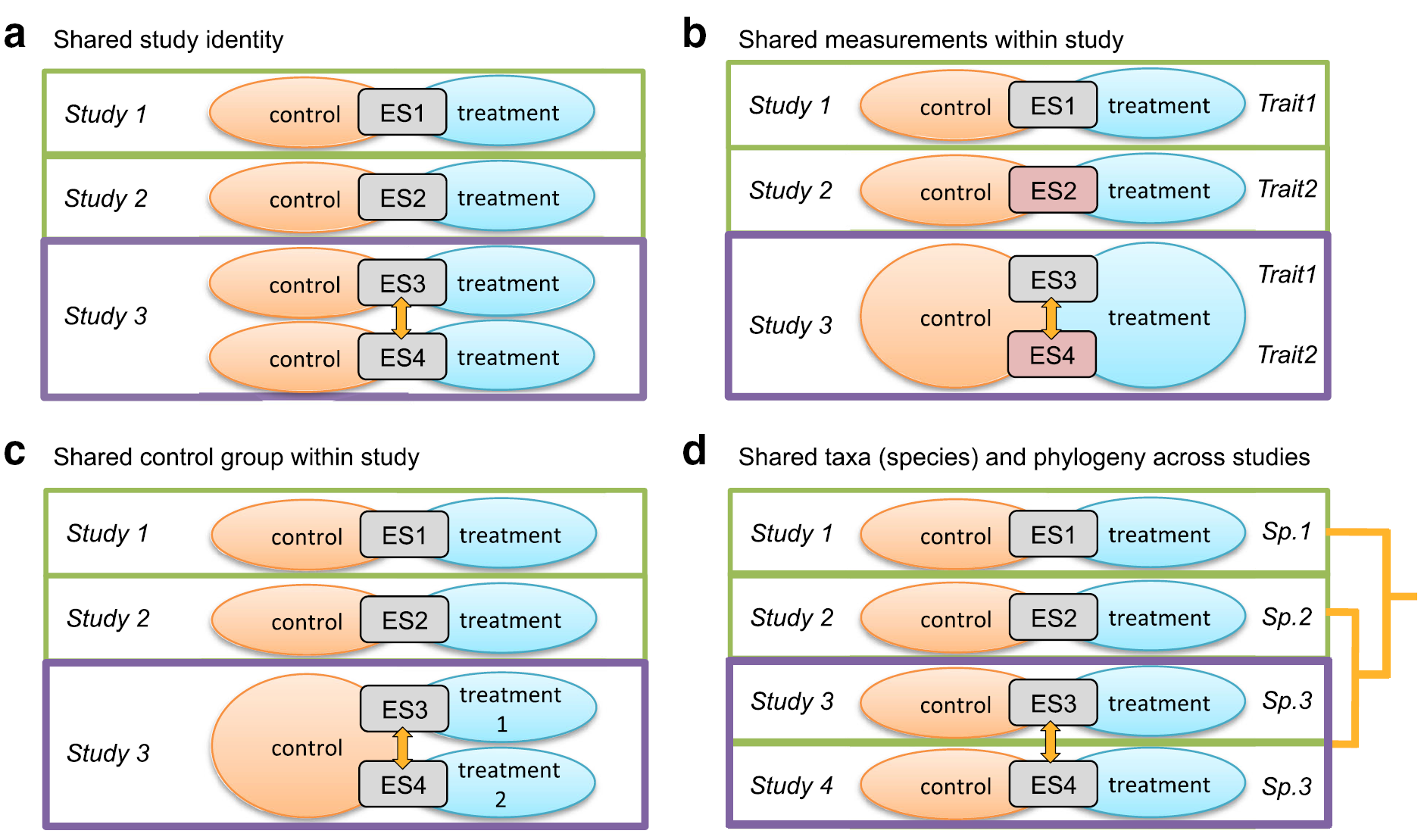 A中,study 3下面嵌套了两个案例研究
A中,study 3下面嵌套了两个案例研究
B中,study3下面两个属性的测量,都来自同一组处理、对照组合
C中,study3同一个对照对应了两个处理
D中,不同的案例涉及的物种之间有不同的亲缘关系
当你的数据存在类似的问题,那么最好要在meta分析模型中进行考虑,采用嵌套(分层)模型进行数据分析,以保证结果的可靠性。
4、选用何种统计模型
仅仅在三四年之前, Meta分析还只有两种模型,即:固定效应模型和随机效应模型(可能有人说还有混合效应模型,但那只不过是随机效应模型中加入了解释变量而已)。但现在,我们可以说,Meta分析有三种模型可供选择:固定效应模型,随机效应模型,嵌套(分层)模型。这三种模型具有较深的理念差异,其核心差异在于是否承认不同的案例研究的结果在理论上会有所不同,如果承认了这种不同,那么其差异来源分别来自哪里。这三种模型的理念差异见下图: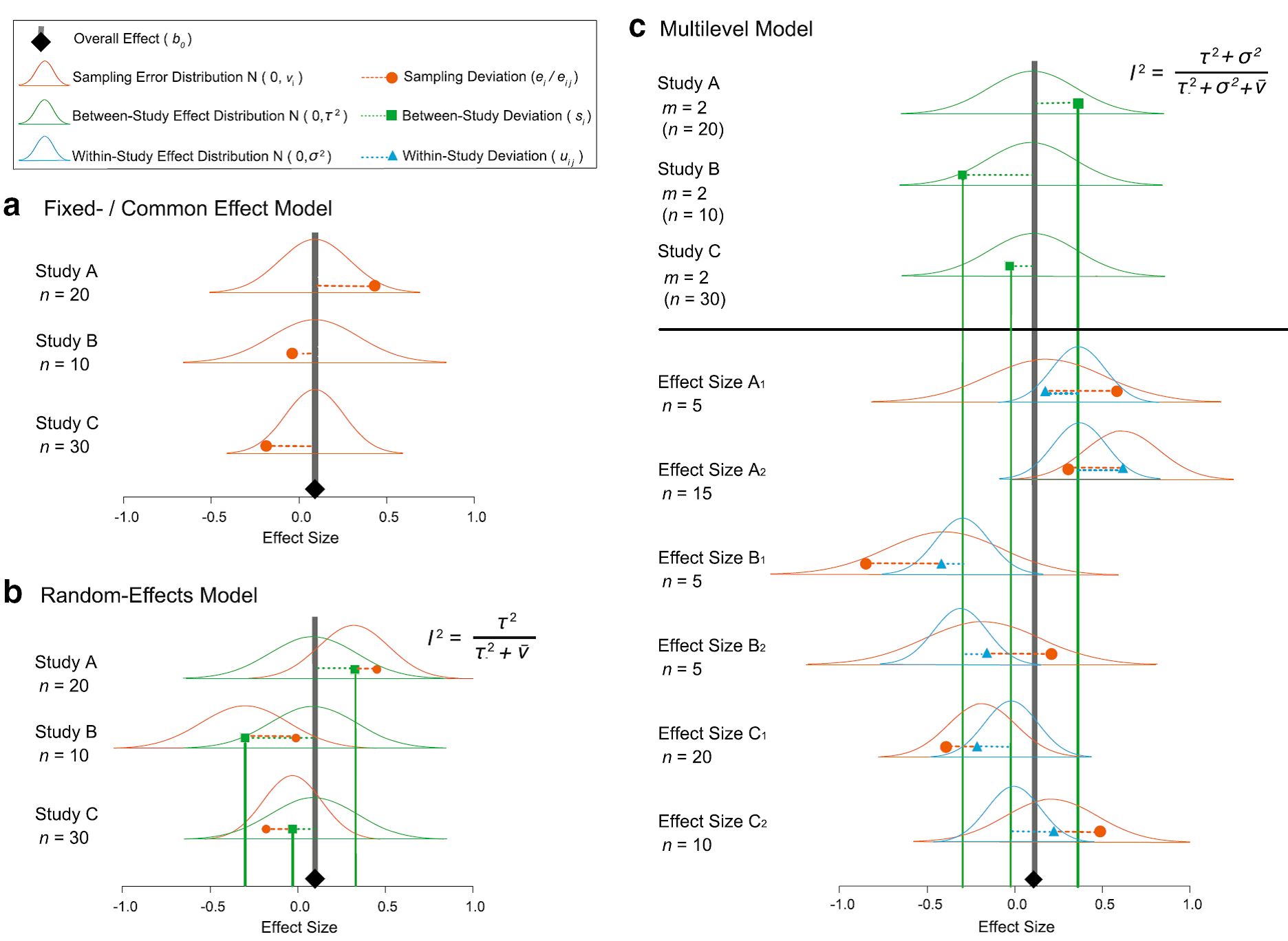
是不是很难看懂?没关系,未来可以听我二傻哥进行世俗化讲解,保证你彻底搞懂!
从应用的角度来讲,要彻底抛弃固定模型,尽量选用随机效应模型,尤其是嵌套模型。嵌套模型在meta分析中
目前已广泛应用,尤其是在高档次杂志中,这一模型已逐步成为标配。
5、是否计算和报道了反映案例间差异程度的指标?
一般情况下我们需要以下几个指标表明数据的异质性(也就是不同案例间的差异程度)
1)Qt, 数据的整体异质性(当然还需要报道其自由度和P值)
2)Tau2 ,案例间方差 (仅采用随机效应模型或嵌套模型时才有此指标)
3)I2,案例间方差在总方差中所占比重 (仅采用随机效应模型或嵌套模型时才有此指标)
上述指标,各自有各自的意义,这里不再详述。但需要明确的一点是,绝对不可以拿说这些指标作为问题4中模型选择的依据。
模型选择完毕之后,你就能得到下图的结果,即从单个案例研究中得到一个统一性的结论: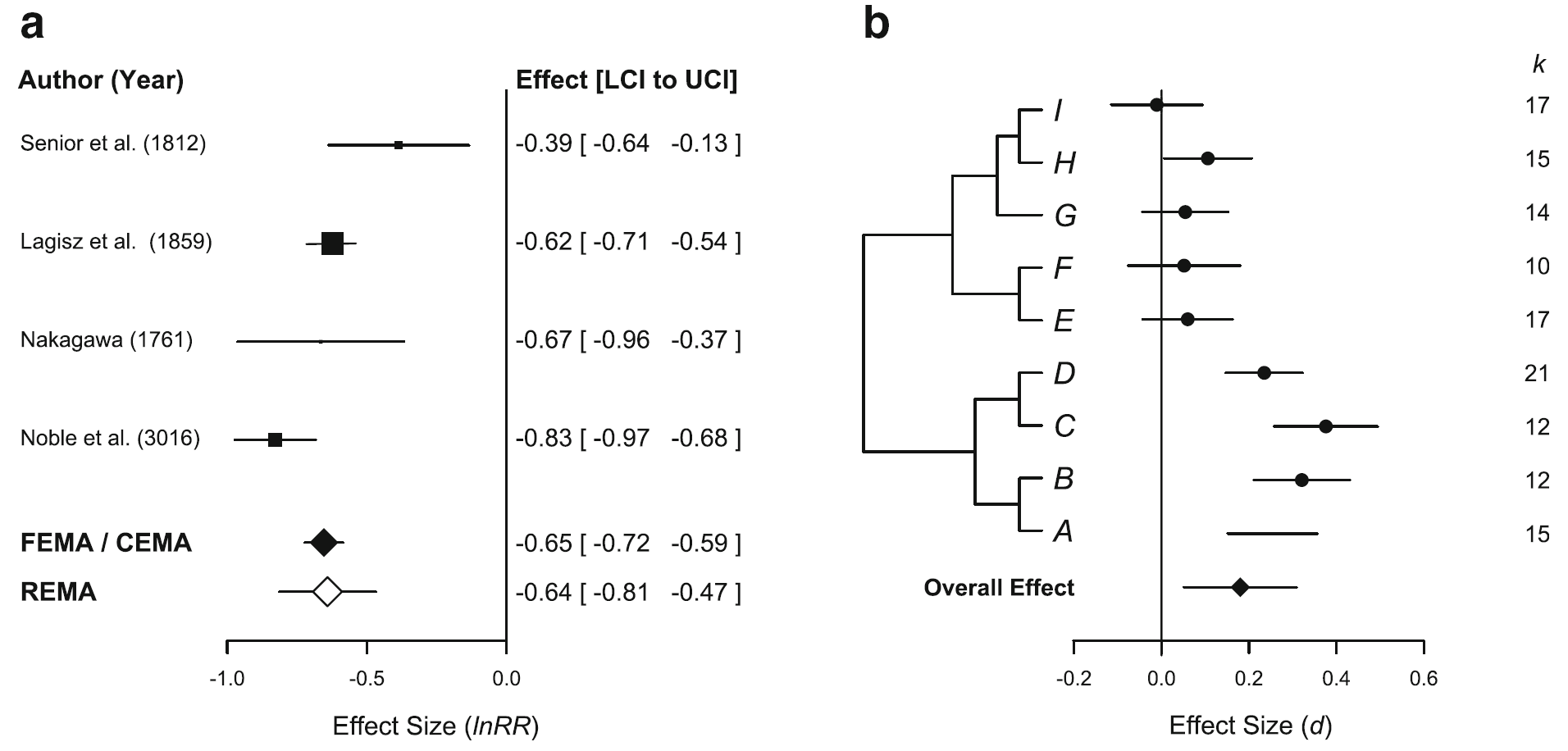
其中a 分别应用了固定和随机两种模型,而b则考虑了物种间的亲缘关系,即采用了嵌套模型。
6、是否对不同案例间差异的来源进行了分析?
这一问题其实最为简单,即使针对同一问题,不同的案例研究结果往往差异很大,那么造成这种差异的原因是什么呢?这时候就需要你结合自己的研究背景,从学术专业角度找出可能影响案例间差异大小的因素。比如某一药物的疗效是否受病人年龄和性别的影响?这一步也往往是meta分析最有意义,最为吸引人的地方。那么如何判定某一因素对效应值的影响是否显著呢,就要用Qm这个指标来判定了。这个问题回答之后,我们的结果通常是: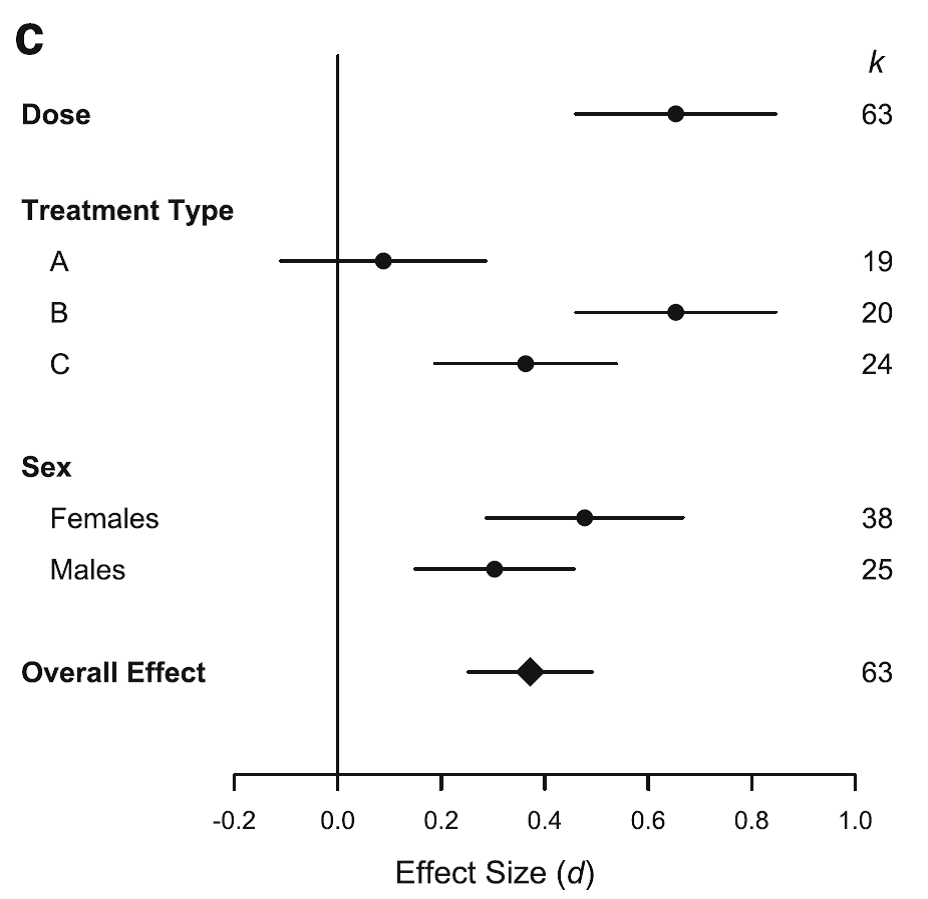
这时候我们就可以告诉读者,某一药物总体上对治疗某种疾病有无效果,且这种治疗效果对于性别不同的患者,以及采用不同给药方式的患者有无不同。后者,往往是单个案例研究所无法回答的问题,这也正是Meta分析的核心魅力所在。
7、结果是否得到了合理的解释以及具有真实的意义,或者仅仅是统计上的“显著”?
这个其实是所有统计中的共性问题,需要你进行深入思考,比如下图: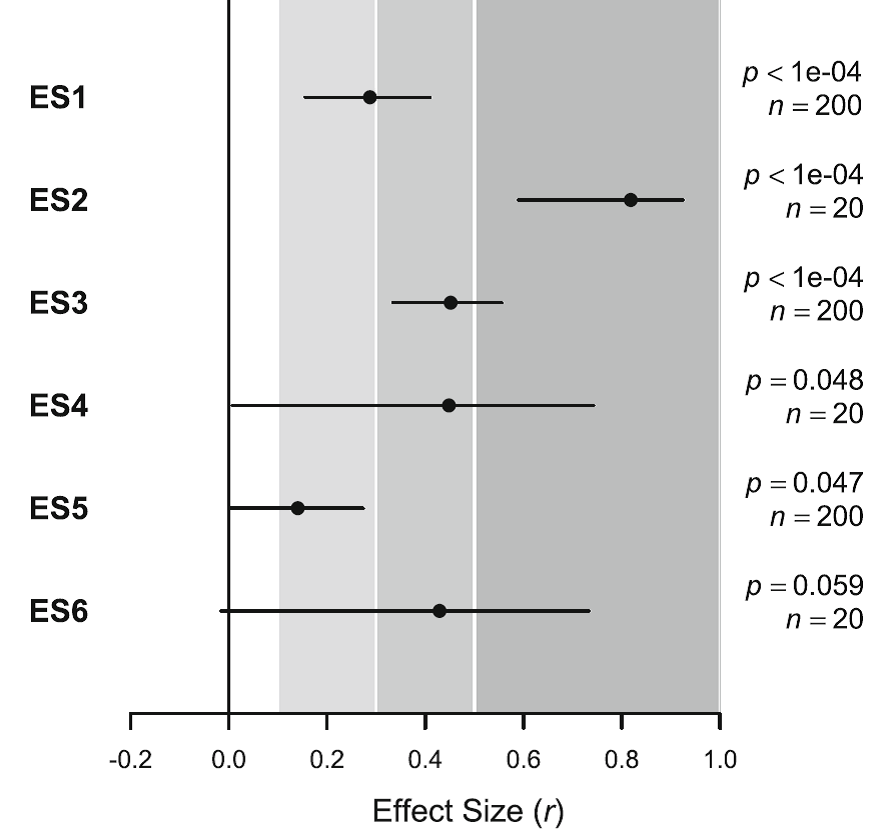
效应值ES5和ES6从统计上来讲,一个显著(P=0.047),一个不显著(P=0.059),但二者的现实意义有本质的差别么?这需要我们各自认真思考。考虑作用大小的意义,而不仅仅是沉迷于对P<0.05的狂热追求,恐怕是当前所有科研人员急需纠正的共性问题。
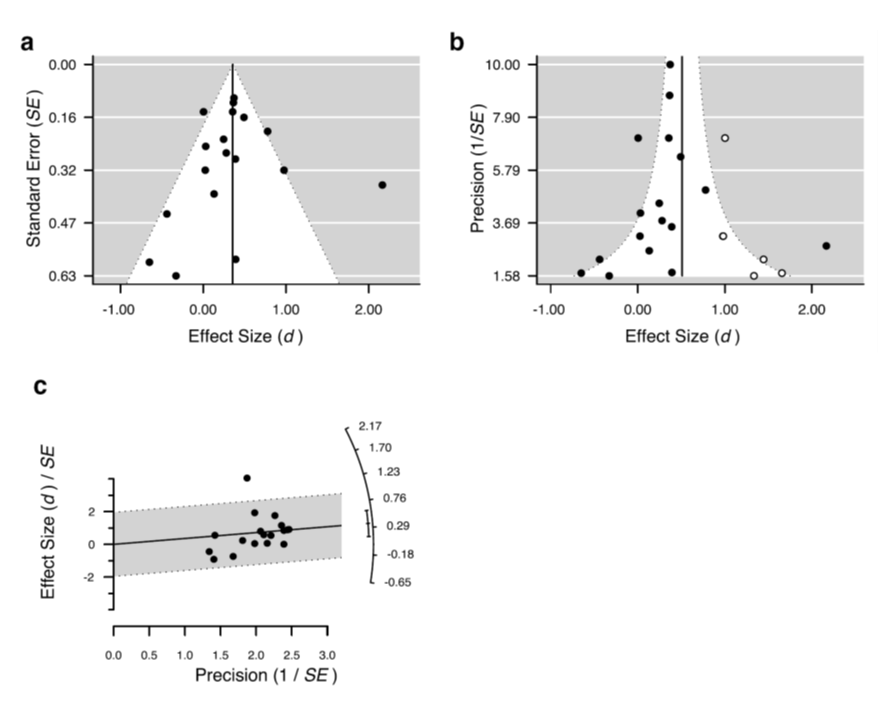
8、 是否考虑了发表偏爱性对结果的影响?
这是标准Meta分析中必须要考虑的问题,因为发表偏爱性,是个无法回避的问题,各领域都存在。事实上,影响因子越高的期刊,发表偏爱性(即对结果显著性强的案例的偏爱性发表)越大,见下图: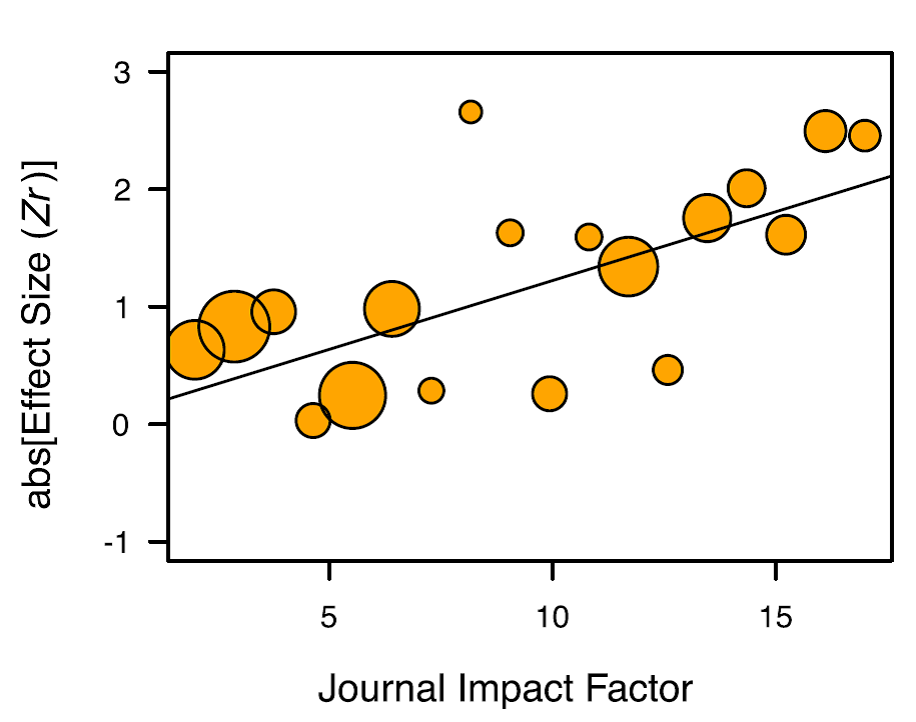
但值得庆幸的时,由于各路科学家对于这一问题的越来越重视,发表偏爱性在时间上,有降低的趋势: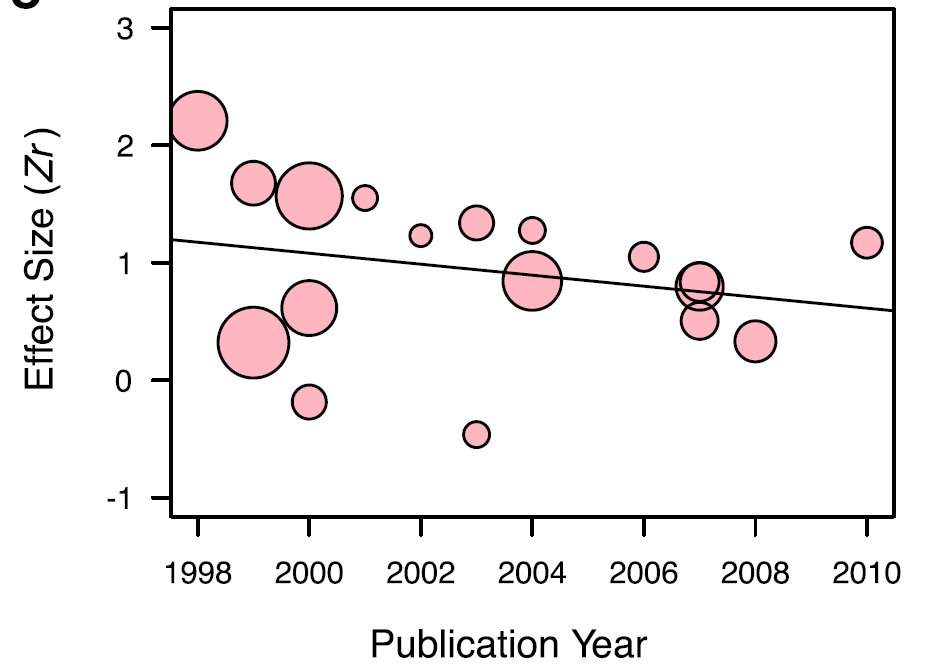
目前,衡量发表偏爱性有几大常用指标
⦁ 失安全系数(是否大于某一临界值为依据)
⦁ 漏斗(烟囱)图(以其是否对称为依据)
⦁ 雷达图等
那么一旦发现了你的结果具有了收到了明显的发表偏爱性的影响,结果就彻底失去意义了么?别慌,还可以用剪补法进行校正。实在不行,大方承认这一缺陷,在讨论中指出即可。漏斗图和雷达图常如下图所示:
9、 个别研究案例是否影响结果的可靠性?
即敏感性分析,也就是加入或者去掉某一项案例研究时,你的结果是否会发生较大改变?目前累计法和抛出法可以完美的回答这一问题。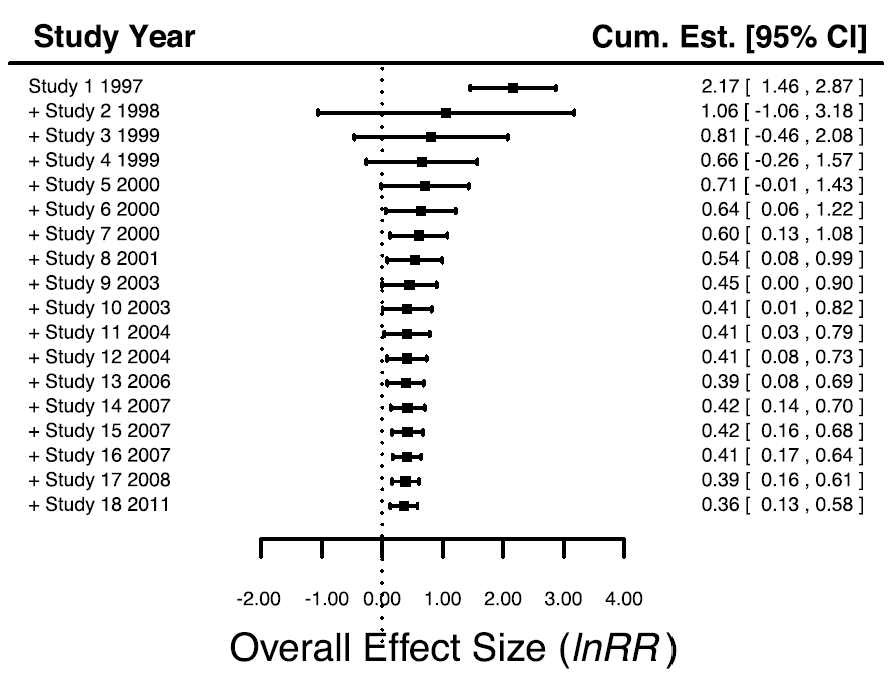
敏感性分析案例—累计图
10、是否认真总结了现在,同时合理展望了未来?
这是一个套路化问题,需要你在论文中结合自己的研究结果,总结下自己的研究对这一领域的贡献,同时指出未来的研究方向。其实,还有最后一个问题值得思考,你这篇Meta分析论文该投Nature呢,还是Science呢?
当然上述问题的回答,只是从理念上让你清楚Meta分析中的一些技术上的要求,要真正掌握Meta分析的每一步过程和软件实现,其实还有很多细节和问题需要解决。欢迎大家关注公众号“二傻统计”,为您提供专业可靠的高质量Meta分析培训和咨询服务。
如果大家意犹未尽,欢迎参加我的Meta分析培训班,现场听二傻哥对Meta分析进行通俗化讲解!最近一期Meta分析培训将于2020年8月1日-2日以线上直播的形式举办,课程详情及报名方式请登陆网址或识别以下二维码查看:
http://bjupclouddata.com/sy

R语言统计制图与地图制作专题培训,2020年8月15日-16日,
树木年轮学培训,2020年8月8日-9日
土壤动物的分类鉴定与研究方法培训,2020年8月29日-30日,
以上培训课程详情及报名方式请登陆网址或识别以下二维码查看:
http://bjupclouddata.com/sy

参考文献:
Gurevitch, J., Koricheva, J., Nakagawa, S. & Stewart, G. (2018) Meta-analysis and the science of research synthesis. Nature, 555, 175.
Nakagawa, S. & Schielzeth, H. (2013) A general and simple method for obtaining R2 from generalized linear mixed-effects models. Methods in Ecology and Evolution, 4, 133-142.
Nakagawa, S., Noble, D.W.A., Senior, A.M. & Lagisz, M. (2017) Meta-evaluation of meta-analysis: ten appraisal questions for biologists. In: BMC biology, p. 18
https://blog.sciencenet.cn/blog-3442043-1243037.html
上一篇:多因素回归分析中,如何比较不同因素对因变量Y的影响大小?(附案例及R代码)
下一篇:一种简单易行的方差分解方法