博文
关于个人科研助理软件Research Flow的设想
|
2018年一月前后,我在为本科毕业论文找课题。因为选的是计算化学,而本专业又是计算机科学这种和化学前沿毫不相干的学科,选题甚是费劲。当然我也可以选择导师的RNA分子力场方向,但好奇心驱使我向着分子间相互作用和分子模拟进发,所以我选定了氢键型晶体。在参考了几篇计算化学尤其是卤键课题的文章后,我意识到还是应该在ACS的Crystal Growth & Design里集中寻找关于氢键型晶体的研究。问题就发生在寻找过程中,并且当时的想法使得我在之后的两年内完成了Research Flow的初步开发。
我设想能有一个应用程序帮助我寻找感兴趣的文章,而我所需要做的只是告诉它我对什么感兴趣。导师说过针对一个方向查阅文献,不光要查大量的文章,还要知道哪些作者经常做这个方向,他们又写了哪些其他文章。这些建议不仅利于我们完成课题调研,更让我在脑海中建立起了类似于知识图谱的图像,完善了对这个应用程序的设想。于是在2018年1月4日,我通过RSS服务在刷手机的时候发现了一篇关于氢键型共晶分子踏板运动研究的论文,并将它定为毕业论文选题。在毕业之后的假期里,我首先开发了一个简易的RSS接收器;在一年之后,苯环双键图案(分子踏板运动的典型发生环境,文章中为偶氮吡啶)成为Research Flow的图标。
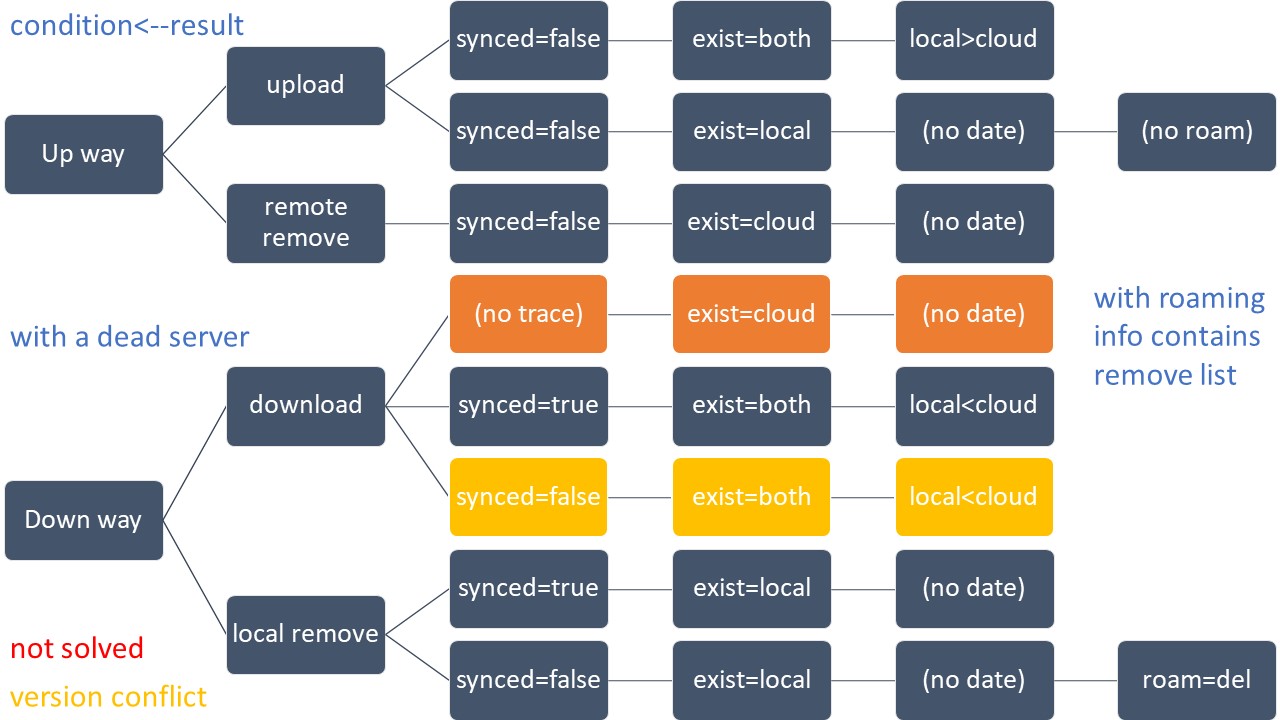
其实在软件开发早期,我很少真正的去做论文搜索器的工作,而是把大量的时间花费在后台应用层。主要解决了三个课题,OneDrive同步算法、Sqlite数据库操作,强实体关系。这三个课题非常恶心,尤其是第一个。因为当你把所有逻辑和上传下载等操作一一对应之后,发现程序无法判断是否应该上传本地文件还是删除本地文件,这源于你根本无法获取OneDrive文件的更新记录,而这个记录是要在所有可能的设备上都能访问到的。当然问题肯定解决了,而且非常巧妙。数据库主要是表设计,好在全是强实体,关系由程序处理,就是改BUG,功能模块衔接等操作比较麻烦。强实体关系由用户操作(软件的宗旨是尽可能减少人类操作,而把任务交给机器)代替原先设想的Flow数据结构。除此之外,还自主解决了应用内消息机制、通知管理、数据存取、各种用户操作业务逻辑等问题。总之独立软件开发要解决很多问题,有些要靠技术,有些要靠设计,很是浪费时间。
从今年一月到二月下旬这段时间,是Research Flow开发的关键时期。因为我知道要完全完成这个应用,这个假期肯定不够用,况且我不能因为疫情的原因在家写代码荒废学业。所以我尽可能先把人类操作的那部分完成,即这个软件已经可以用了,但是不好用。不好用是因为它目前还不是机器人,而且各种功能并不是连接的很紧密。下面我介绍一下各个功能和设想。
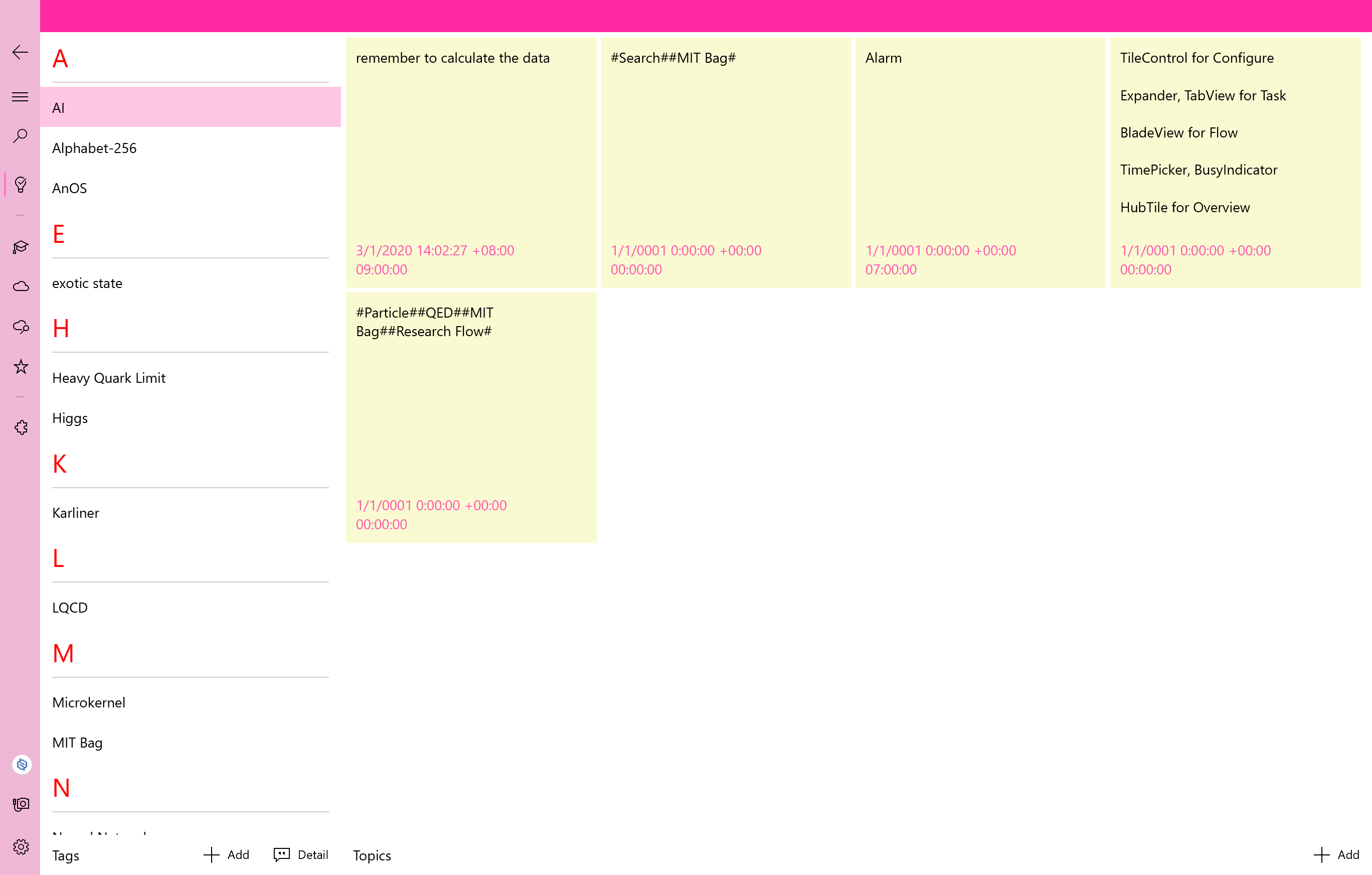
Tag & Topic,这应该是首页了,因为在Task开发好之前Overview页面暂时无法推出。左边的是用户输入的或者应用自己找到的标签,编辑方法类似于微博那样,#Tag#。这些标签表明当前用户对那些领域感兴趣。如果你点击某个标签,会汇总这个标签存在于哪些数据,一目了然。当然在机器人完成前Tag只是个摆设。右边是Topic,定义很灵活,可以是笔记、闹钟、提醒。在未来的设想中,Topic是获取用户需求的窗口。用户只需要在Topic中以一定格式编辑文本,就可以提交任务让机器去完成。而Chat窗口则是整个应用的门户,包含Topic。
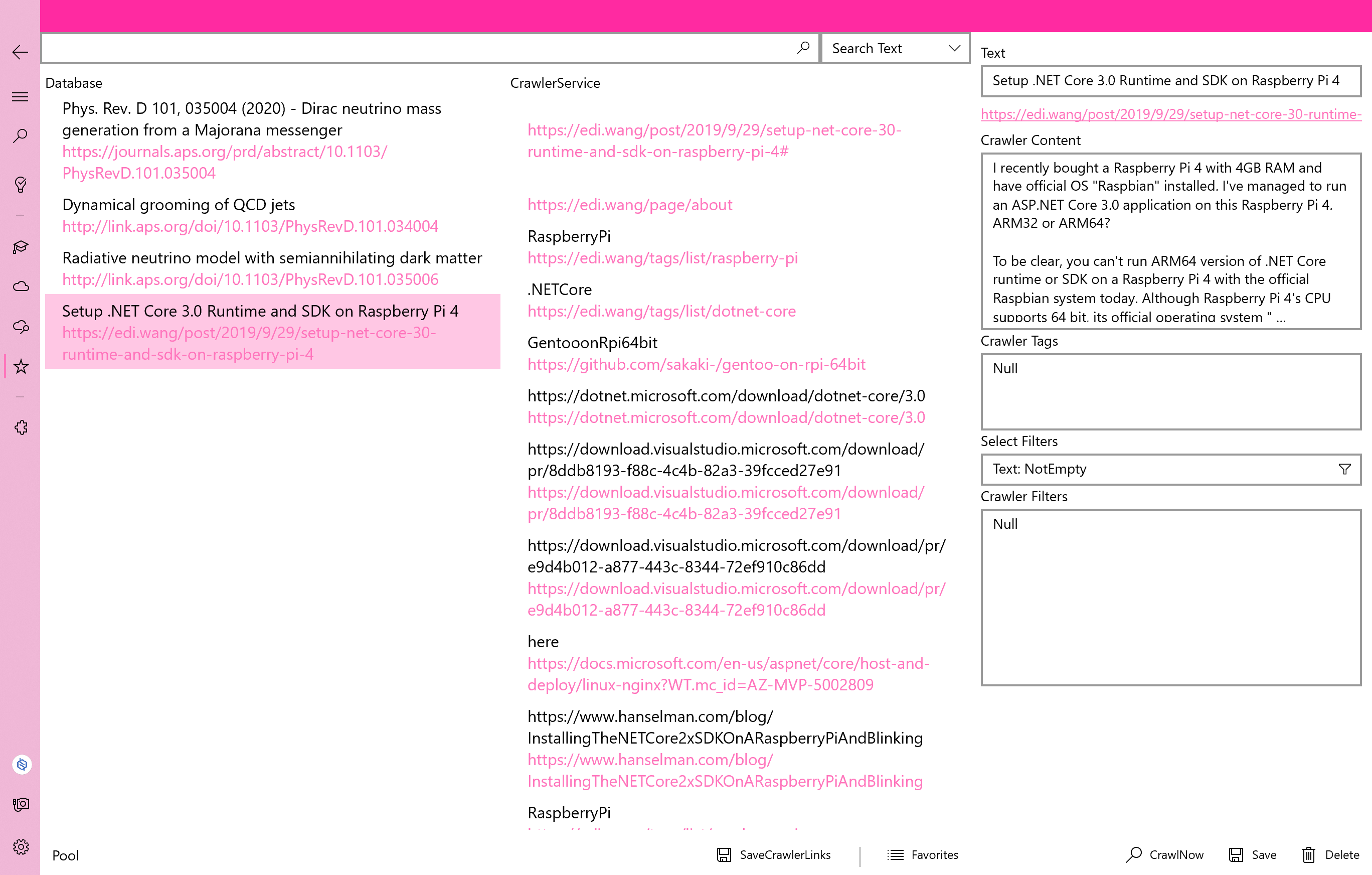
论文管理。我不打算做PDF阅读器,因为我做的没别人的好,所以在这个页面你只能预览PDF的前十页。它的功能是告诉你,你有哪些论文需要关注。这些论文可能是你导入的PDF或者是应用帮你下载的,也可能只是一个网页链接,这些都不重要。重要的是你可以在这里标明从这篇论文中学到的东西,方便以后翻阅论文或者在自己的论文里写reference的时候知道为什么cite。It works for me. 我需要这个功能,尤其是有很多文献需要参考的时候它对我很重要。所以我不清楚其他用户是否也同样看好它,这一点我没做调研。当然功能肯定不止如此,只是还未完成。论文可以定义Tag,可以让机器去分析,可以让爬虫去爬,可以做统计,看看谁写了哪些文章,又引用了谁的文章。树结构数据库就是干这事的,这些在今后都能完成。但它比起下面三个功能,只是个独立功能。

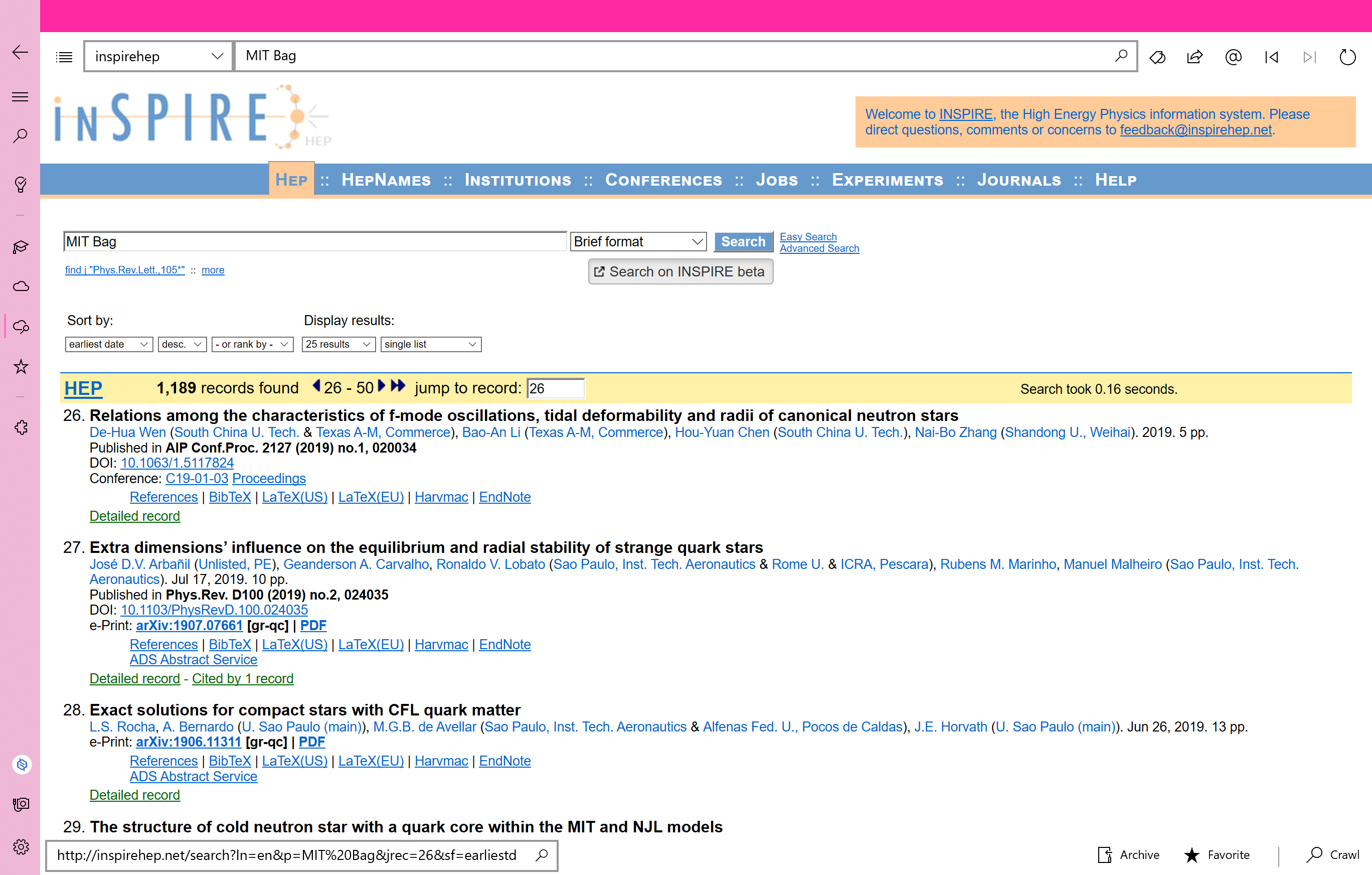
RSS功能我前面已经说了,是灵感之源。好在它很灵活,比如你要按照时间来订阅某个搜索词,就拿ACS来说吧。你在ACS网站上搜索Hydrogen Bond,又按照时间来排序,你会找到一个RSS的图标,此时这个feeds里的内容就是按照时间顺序排列的搜索结果。把这个feeds链接添加到应用里,就能获取最新的搜索结果,某种意义上是让机器按照你的需求搜索(当初我就是这么干的)。Feed的数据是按照Xml来存储的,我选择原封不动的保存XmlNode,因为我可能随时会查看期刊文献的doi号和作者等信息,既然这些信息都在Xml里,就用Xml的方式解析数据。点开某个feed后,会出现三个按钮:浏览网页、添加收藏、添加论文。应用内置了WebView,可以查看网页,也可以在查看的同时用爬虫搜索网页内容。添加收藏实际上是直接添加到了爬虫数据库,但还是有一个专门的列表来显示收藏,这在Crawler页面中可以找到。添加论文就是把Xml中和应用有关的信息添加到上一个页面的表单里。我看有些产品能够从PDF文件中提取信息,这个我可以试一下。

我想做两个搜索引擎,一个是像Chrome浏览器那样通过分析链接来判断用户用了哪些外部搜索引擎,另一个是我自己做一个。应用应该是内置了arxiv和ACS的搜索链接,用户也可以在浏览网页的时候注意一下,当前的搜索结果网站链接里是否有你的搜索词,把它换成QUEST再添加到搜索引擎列表里,就可以为你和应用所用了。我相信Chrome也是这么干的,只不过我这个是用户自己改,麻烦一点。当然这时你就可以用这些引擎了,在这个应用里,但我的设想是应用根据用户需求,自己在后台慢慢搜索,通过Windows 10的ToastNotification告知用户,当前有令人满意的搜索结果,或者直接存入爬虫数据库。需要注意的一点是,WebView页面提供了第一层爬虫,你可以找到pdf下载链接,只需点击(再加上校园网)就能下载。你也可以把第一层爬虫的结果导入Crawler页面,存入数据库或继续爬。
我所说的自己做一个搜索引擎就是构建自己的爬虫数据库。我不知道搜索引擎是怎么做出来的,我这纯粹是猜的,想想一个轻量级的应该可以这么做吧。这一部分是最需要机器人来完成的,成千上万个链接不可能由人来判断当前爬哪个,下次爬哪个,爬几层,只能由Task根据用户需求判断。等数据库扩充到一定程度,我是说个性化到一定程度,你就可以在上面的搜索框中开始搜索了。或者你还是可以偷懒,等着应用发来一条通知,说有不错的网站,建议你看看。
最后一个功能是完全的独立功能,可能此类功能以后还要添加。如果你用的是Surface设备,可以用Surface Pen在这里做笔记。当然你可以说OneNote很好,WhiteBoard很好,我无可辩驳。但是它已经够用了,而且作为Research Flow的一个功能,它的Note文件是由OneDrive同步的。我自己呢,是用OneNote做课堂笔记,因为它无限大,但有时候做些简单推导,或者开组会记录点零散的东西,都是用它。

综上所述,我已经完成了科研助理软件的部分开发,让它真正成为助理还需要时间。这段时间内我也在反省,一个科研工作者到底需要什么样的助理软件,如何才能真正让机器用闲散的时间整理并完成人的工作,并和人的工作节奏达成一致。我不去往人工智能和机器学习等方面去想,因为我觉得这不是重点。重点是我得先完成Task,重点是我自己也得搞清楚如何科研。也有很多软件产品做了我的功能,不知道科学网的“小柯机器人”算不算,还有readcube,acs官方都做得很好。但是我想做的是扩充再精简,借鉴其他软件的功能,扩充到我的软件里,再将它个性化,由用户定义自己的数据。
https://blog.sciencenet.cn/blog-3429375-1222326.html