博文
语义信息与语义分割
||
(一)语义信息
语义是语言的含义,比如v,这只是一个符号,当告诉你它表示速度,那么v就是有含义的,于是速度便是v的语义,用v表示速度可以认为是一种语言中对速度的表达方式。
同理,“小孩”也只是个符号,赋予了含义才知道它表示什么。大量的中文汉字和词语和他们对应的含义一起形成了中文这种语言,可以说语言就是文字/词语和含义(即语义)构成,就好比公式里的数学符号和对应的物理量。
那么,图像的语义分割(semantic segmentation)就是把图像中属于同一个语义的东西分割出来,当然这个东西就是像素了。比如下图,我们把图中的小孩和摩托车分割出来,这就是语义分割了。可以认为对于图像而言,表达孩子这个语义的不是汉字,而是一部分像素。

图像的语义分为视觉层、对象层和概念层。
视觉层即通常所理解的底层,即颜色、纹理和形状等等,这些特征都被称为底层特征语义;对象层即中间层,通常包含了属性特征等,就是某一对象在某一时刻的状态;概念层是高层,是图像表达出的最接近人类理解的东西。
举例:通俗点说,比如一张图上有沙子,蓝天,海水等,视觉层是一块块的区分,对象层是沙子、蓝天和海水这些,概念层就是海滩,这是这张图表现出的语义。
(二)语义分割
(1)基本概念
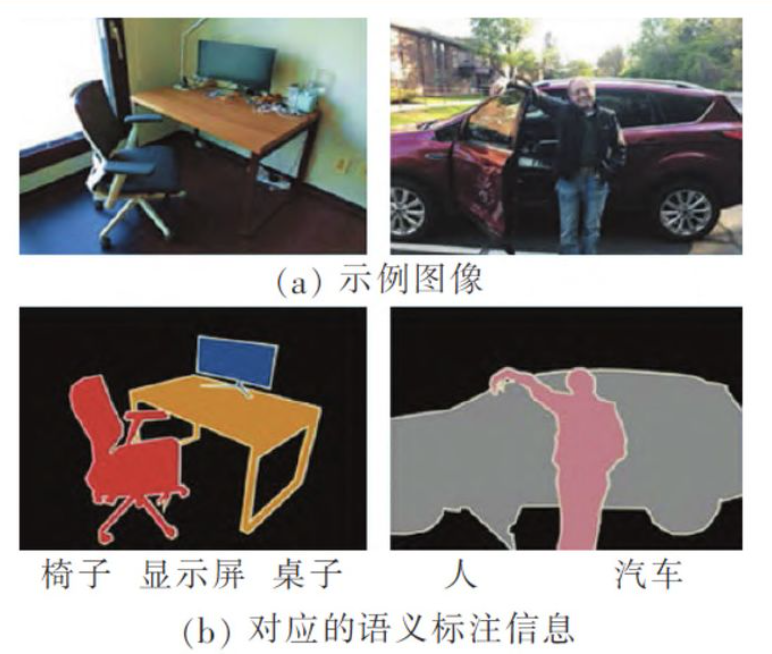
图像语义分割的目标,是将语义标签分配给图像中的每个像素,其中语义标签通常包括不同范围的物体类別(人、狗、公共汽车、自行车)和背景成分(天空、道路、建筑物、山)。
如图所示,语义分割的结果是预测图像中每个像素所对应的类别分割掩码,相比较于图像分类给出的图像级类别別标签和目标检测所预观的物体框,它能更全面地描述图像内容。
语义分割对于不同的神经网络具体要求是不一样的,这里介绍两种常用的神经网络:全卷积神经网络(FCN)是目前语义分割最常用的网络,深度卷积神经网络(CNN)是图像级别语义理解的利器,一般是用于图像分类或者特征抽取,而FCN则是基于CNN实现的像素级别的语义理解,更加适用于图像语义分割、边缘检测等应用场景,但这种网络有一个比较大的缺点,对数据标注要求过高,不仅需要海量图像数据,而目这些还需要提供精确到像素级别的标记信息。
基于弱监督的深度卷积神经网络( DCNNS),弱监督语义分割的目标是利用弱标注而不是像素级标注来学习语义分割模型,语义分割的可能的弱标签如图所示。

它包括图像集类标签、物体框、简笔掩码监督和点监督等,由于标注成本低,这些标签比像素级标签更容易收集,因此,相对于FCN更适合用来学习和训练图像语义分割模型。
(2)语义分割的思路
I.传统方法
在深度学习方法流行之前,TextonForest和基于随机森林分类器等语义分割方法是用得比较多的方法。不过在深度卷积网络流行之后,深度学习方法比传统方法提升了很多,所以这里就不详细讲传统方法了。
II.深度学习方法
深度学习方法在语义分割上得到了巨大成功,深度学习方法解决语义分割问题可以概括为几种思路。下面进行详细介绍。
1.Patch classification
最初的深度学习方法应用于图像分割就是Patch classification。Patch classification方法,顾名思义,图像是切成块喂给深度模型的,然后对像素进行分类。使用图像块的主要原因是因为全连接层需要固定大小的图像。
2.全卷积方法
2014年,全卷积网络(FCN)横空出世,FCN将网络全连接层用卷积取代,因此使任意图像大小的输入都变成可能,而且速度比Patch classification方法快很多。
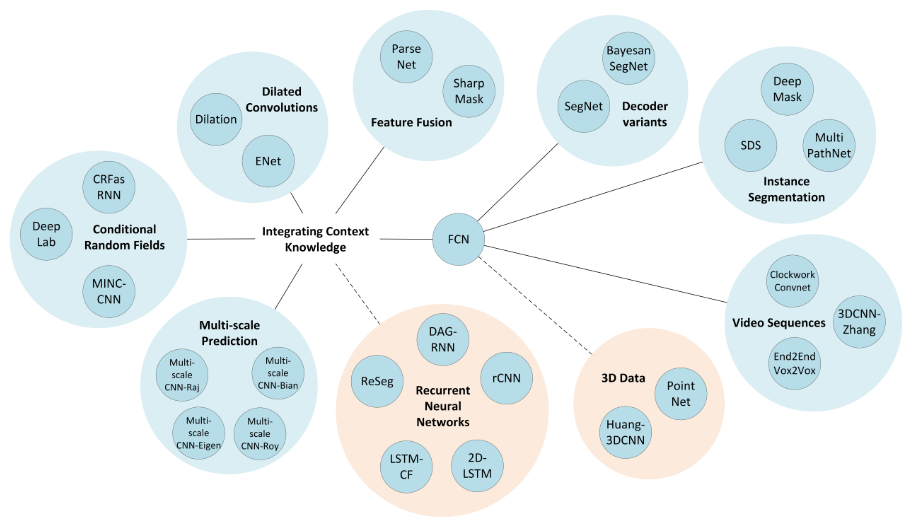
尽管移除了全连接层,但是CNN模型用于语义分割还存在一个问题,就是下采样操作(比如,pooling)。pooling操作可以扩大感受野因而能够很好地整合上下文信息(context中文称为语境或者上下文,通俗的理解就是综合了更多的信息来进行决策),对high-level的任务(比如分类),这是很有效的。但同时,由于pooling下采样操作,使得分辨率降低,因此削弱了位置信息,而语义分割中需要score map和原图对齐,因此需要丰富的位置信息。
3.encoder-decoder架构
Encoder-decoder是基于FCN的架构。encoder由于pooling逐渐减少空间维度,而decoder逐渐恢复空间维度和细节信息。通常从encoder到decoder还有shortcut connetction(捷径连接,也就是跨层连接)。其中U-net就是这种架构很流行的一种,如下图:

4.空洞卷积
Dilated/atrous (空洞卷积)架构,这种结构代替了pooling,一方面它可以保持空间分辨率,另外一方面它由于可以扩大感受野因而可以很好地整合上下文信息。如下图:

5.条件随机场
除了以上思路,还有一种对分割结果进行后处理的方法,那就是条件随机场(Conditional Random Fields (CRFs))后处理用来改善分割效果。DeepLab系列文章基本都采用这种后处理方法,可以较好地改善分割结果,如下图:

【参考】
https://blog.csdn.net/nanhuaibeian/article/details/102784481
https://www.zhihu.com/question/294617103
https://blog.qure.ai/notes/semantic-segmentation-deep-learning-review#dilation
https://zhuanlan.zhihu.com/p/37801090
https://www.programmersought.com/article/31495010590/
Garcia-Garcia A, Orts-Escolano S, Oprea S, et al. A review on deep learning techniques applied to semantic segmentation[J]. arXiv preprint arXiv:1704.06857, 2017.
https://blog.sciencenet.cn/blog-3428464-1281627.html
上一篇:3D-Unet一定优于2D-Unet么?
下一篇:转置卷积(transposed convolution)或反卷积(deconvolution)
全部作者的其他最新博文
- • [转载]太阳同步轨道
- • 膳食指南