博文
tensorflow中一些函数用法总结
||
(1)tf.truncated_normal与tf.random_normal的详细用法
tf.truncated_normal
tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
从截断的正态分布中输出随机值。
生成的值服从具有指定平均值和标准偏差的正态分布,如果生成的值大于平均值2个标准偏差的值则丢弃重新选择。
在正态分布的曲线中,横轴区间(μ-σ,μ+σ)内的面积为68.268949%。
横轴区间(μ-2σ,μ+2σ)内的面积为95.449974%。
横轴区间(μ-3σ,μ+3σ)内的面积为99.730020%。
X落在(μ-3σ,μ+3σ)以外的概率小于千分之三,在实际问题中常认为相应的事件是不会发生的,基本上可以把区间(μ-3σ,μ+3σ)看作是随机变量X实际可能的取值区间,这称之为正态分布的“3σ”原则。
在tf.truncated_normal中如果x的取值在区间(μ-2σ,μ+2σ)之外则重新进行选择。这样保证了生成的值都在均值附近。
参数:
shape: 一维的张量,也是输出的张量。
mean: 正态分布的均值。
stddev: 正态分布的标准差。
dtype: 输出的类型。
seed: 一个整数,当设置之后,每次生成的随机数都一样。
name: 操作的名字。
代码示例:
import tensorflow as tf;
import numpy as np;
import matplotlib.pyplot as plt;
c = tf.truncated_normal(shape=[10,10], mean=0, stddev=1)
with tf.Session() as sess:
print sess.run(c)
输出:
[[ 1.95758033 -0.68666345 -1.83860338 0.78213859 -1.08119416 -1.44530308
0.38035342 0.57904619 -0.57145643 -1.22899497]
[-0.75853795 0.48202974 1.03464043 1.19210851 -0.15739718 0.8506189
1.18259966 -0.99061841 -0.51968449 1.38996458]
[ 1.05636907 -0.02668529 0.64182931 0.4110294 -0.4978295 -0.64912242
1.27779591 -0.01533993 0.47417602 -1.28639436]
[-1.65927458 -0.364887 -0.45535028 0.078814 -0.30295736 1.91779387
-0.66928798 -0.14847915 0.91875714 0.61889237]
[-0.01308221 -0.38468206 1.34700036 0.64531708 1.15899456 1.09932268
1.22457981 -1.1610316 0.59036094 -1.97302651]
[-0.24886213 0.82857937 0.09046989 0.39251322 0.21155456 -0.27749416
0.18883201 0.08812679 -0.32917103 0.20547724]
[ 0.05388507 0.45474565 0.23398806 1.32670367 -0.01957406 0.52013856
-1.13907862 -1.71957874 0.75772947 -1.01719368]
[ 0.27155915 0.05900437 0.81448066 -0.37997526 -0.62020499 -0.88820189
1.53407145 -0.01600445 -0.4236775 -1.68852305]
[ 0.78942037 -1.32458341 -0.91667277 -0.00963761 0.76824385 -0.5405798
-0.73307443 -1.19854116 -0.66179073 0.26329204]
[ 0.59473759 -0.37507254 -1.21623695 -1.30528259 1.18013096 -1.32077384
-0.59241474 -0.28063133 0.12341146 0.48480138]]
tf.random_normal
tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
从正态分布中输出随机值。
参数:
shape: 一维的张量,也是输出的张量。
mean: 正态分布的均值。
stddev: 正态分布的标准差。
dtype: 输出的类型。
seed: 一个整数,当设置之后,每次生成的随机数都一样。
name: 操作的名字。
示例代码:
a = tf.Variable(tf.random_normal([2,2],seed=1))
b = tf.Variable(tf.truncated_normal([2,2],seed=2))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print(sess.run(a))
print(sess.run(b))
输出:
[[-0.81131822 1.48459876]
[ 0.06532937 -2.44270396]]
[[-0.85811085 -0.19662298]
[ 0.13895047 -1.22127688]]
指定seed之后,a的值不变,b的值也不变。
(2)tf.Variable()函数
tf.Variable()函数
详细参考:https://blog.csdn.net/xc_zhou/article/details/85415098,各种随机函数用法总结!
特别注意:tf.initialize_all_variables()和tf.global_variables_initializer()的区别
两者是完全相同的,tensorflow的官方文档中说明tf.initialize_all_variables()将被放弃使用,因此推荐使用tf.global_variables_initializer()!
作用:返回一个op,作用是初始化所有的全局变量
别名:tf.initializers.global_variables()
对tf.global_variables_initializer()的具体解释:在一个session中运行过tf.global_variables_initializer()后,变量才会持有赋给它们的初始化的值(在我们之前定义过的tf.Variable(tf.zeros(…)), tf.Variable(tf.random_normal(…))中)
在TensorFlow的世界里,变量的定义和初始化是分开的,所有关于图变量的赋值和计算都要通过tf.Session的run来进行。将所有图变量进行集体初始化时应该使用tf.global_variables_initializer。
tf.initialize_all_variables()和tf.global_variables_initializer()的区别
(3)tf.nn.conv2d用法详解
tf.nn.conv2d()函数
我们已经知道这个函数是用于做二维卷积的,但是他容易和tf.layers.conv2d()混淆。
def conv2d(input, # 张量输入
filter, # 卷积核参数
strides, # 步长参数
padding, # 卷积方式
use_cudnn_on_gpu=None, # 是否是gpu加速
data_format=None, # 数据格式,与步长参数配合,决定移动方式
name=None): # 名字,用于tensorboard图形显示时使用
参数解说:
**input : ** 输入的要做卷积的图片,要求为一个张量,shape为 [ batch, in_height, in_weight, in_channel ],其中batch为图片的数量,in_height 为图片高度,in_weight 为图片宽度,in_channel 为图片的通道数,灰度图该值为1,彩色图为3。(也可以用其它值,但是具体含义不是很理解)
filter: 卷积核,要求也是一个张量,shape为 [ filter_height, filter_weight, in_channel, out_channels ],其中 filter_height 为卷积核高度,filter_weight 为卷积核宽度,in_channel 是图像通道数 ,和 input 的 in_channel 要保持一致,out_channel 是卷积核数量。
strides: 卷积时在图像每一维的步长,这是一个一维的向量,[ 1, strides, strides, 1],第一位和最后一位固定必须是1
padding: string类型,值为“SAME” 和 “VALID”,表示的是卷积的形式,是否考虑边界。"SAME"是考虑边界,不足的时候用0去填充周围,"VALID"则不考虑
use_cudnn_on_gpu: bool类型,是否使用cudnn加速,默认为true
重点注意具体说明:
步长:卷积核相对图片滑动,然后进行卷积,提取特征。细想,问题有两个,怎么相对? 滑动多少? 那么步长(strides)来帮你解决问题。步长(strides)就是移动方式,图片(张量以下我们以图片代替方便理解,即二维数据)数据有通道数,有长宽,卷积核是先按宽度方向按指定步长移动,还是按高度方向?,还是按通道方向?接下来我们看结构图:
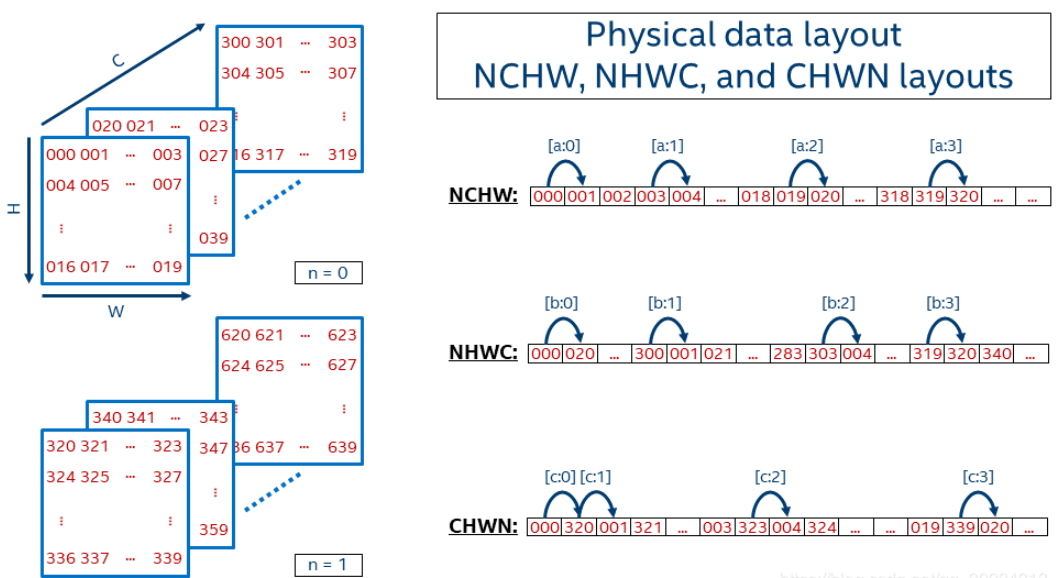
移动方式一: 第一个元素是000,第二个元素是沿着w方向的,即001,这样下去002 003,再接着呢就是沿着H方向,即004 005 006 007…这样到09后,沿C方向,轮到了020,之后021 022 …一直到319,然后再沿N方向。————这种方式叫:NCHW 。(注意顺序,N是n,是数量,C是channel, H是height, W是width)
移动方式二:第一个元素是000,第二个沿C方向,即020,040, 060…一直到300,之后沿W方向,001 021 041 061…301…到了303后,沿H方向,即004 024 .。最后到了319,变成N方向,320,340…————这种方式叫:NHWC。
所以dataformat参数的取值有两种,NCHW ,NHWC,默认是NHWC。
那么,与此dataformat配合的strides如何取值呢?
当dataformat是默认的NHWC时,strides=[batch, height, width, channels]
当dataformat是NCHW时,strides=[batch, channels, height, width]
那么,是不是有个疑问,为什么两个顺序不一样?这不科学嘛!
其实你认真看,strides的顺序是dataformat数据顺序是一致的,你看NHWC -> [b(n), h, w, c]->[batch,height,wight, channel]。通常我们都没有更改默认设置,所以strides是[batch, height, width, channels],所以当你找到定义函数文档有这样的说明
Must have strides[0] = strides[3] = 1. For the most common case of the same
horizontal and vertices strides, strides = [1, stride, stride, 1].
(4)tf.nn.max_pool用法详解
tf.nn.max_pool()函数
tf.nn.max_pool(value, ksize, strides, padding, name=None)
参数value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch, height, width, channels]这样的shape
参数ksize:池化窗口的大小,取一个四维向量,一般是[1, height, width, 1],因为我们不想在batch和channels上做池化,所以这两个维度设为了1
参数strides:和卷积类似,窗口在每一个维度上滑动的步长,一般也是[1, stride,stride, 1]
参数padding:和卷积类似,可以取'VALID' 或者'SAME'
返回一个Tensor,类型不变,shape仍然是[batch, height, width, channels]这种形式
示例代码:
假设有这样一张图,双通道:
第一个通道 第二个通道
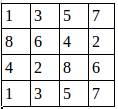
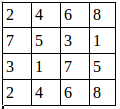
用程序去做最大值池化:
import tensorflow as tf
a=tf.constant([
[[1.0,2.0,3.0,4.0],
[5.0,6.0,7.0,8.0],
[8.0,7.0,6.0,5.0],
[4.0,3.0,2.0,1.0]],
[[4.0,3.0,2.0,1.0],
[8.0,7.0,6.0,5.0],
[1.0,2.0,3.0,4.0],
[5.0,6.0,7.0,8.0]]
])
a=tf.reshape(a,[1,4,4,2])
pooling=tf.nn.max_pool(a,[1,2,2,1],[1,1,1,1],padding='VALID')
with tf.Session() as sess:
print("image:")
image=sess.run(a)
print (image)
print("reslut:")
result=sess.run(pooling)
print (result)
print ("最终结果:\n",result.transpose(0,3,1,2)) #正确输出需要转换坐标轴,更改多维坐标轴的顺序,有(N,H,W,C)变为(N,C,H,W)
这里步长为1,窗口大小2×2,输出结果:
image:
[[[[ 1. 2.]
[ 3. 4.]
[ 5. 6.]
[ 7. 8.]]
[[ 8. 7.]
[ 6. 5.]
[ 4. 3.]
[ 2. 1.]]
[[ 4. 3.]
[ 2. 1.]
[ 8. 7.]
[ 6. 5.]]
[[ 1. 2.]
[ 3. 4.]
[ 5. 6.]
[ 7. 8.]]]]
reslut:
[[[[ 8. 7.]
[ 6. 6.]
[ 7. 8.]]
[[ 8. 7.]
[ 8. 7.]
[ 8. 7.]]
[[ 4. 4.]
[ 8. 7.]
[ 8. 8.]]]]
最终结果:
[[[[8. 6. 7.]
[8. 8. 8.]
[4. 8. 8.]]
[[7. 6. 8.]
[7. 7. 7.]
[4. 7. 8.]]]]
池化后的图就是:
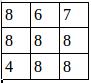
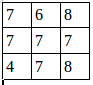
我们还可以改变步长:
pooling=tf.nn.max_pool(a,[1,2,2,1],[1,2,2,1],padding='VALID')
最后的result就变成:
reslut:
[[[[ 8. 7.]
[ 7. 8.]]
[[ 4. 4.]
[ 8. 8.]]]]
可以参见此例的辅助理解这个例子:https://blog.csdn.net/m0_37586991/article/details/84575325,但是,在矩阵初始化时,与原矩阵不同,这个无法理解!目前尚不清楚!
点滴分享,福泽你我!Add oil!
【参考】
https://www.jb51.net/article/135888.htm
https://blog.csdn.net/qq_30934313/article/details/86626050
https://blog.csdn.net/mao_xiao_feng/article/details/53453926
https://blog.sciencenet.cn/blog-3428464-1248526.html
上一篇:[转载]Python中的_, __, __xx__ 区别
下一篇:ROC曲线
全部作者的其他最新博文
- • [转载]太阳同步轨道
- • 膳食指南