博文
数据预处理——异常值识别和缺失值填补
||
一、什么是异常值?什么是缺失值?
异常值,又称离群点(outlier),是指数据集中存在不合理的个别值,其数值明显偏离所属样本的其余观测值。一组测定值中与平均值的偏差超过两倍标准差的测定值,与平均值的偏差超过三倍标准差的测定值,称为高度异常的异常值。
缺失值(missing value):现有数据集中某个或某些属性的值是不完全的。【百度百科】
二、异常值的识别和判定方法
【异常值识别】
在异常值处理之前需要对异常值进行识别,一般多采用单变量散点图或者箱线图来达到识别目的。异常值产生最常见的原因是人为输入的错误,如小数点输入错误。
【判别方法】
(1)简单统计分析
对属性值进行描述性统计,从而查看哪些值是不合理的。比如对年龄这个属性进行判别:年龄的区间在[0:120],如果样本中的某条记录的年龄值不在该区间范围内,则表示该记录的年龄属性属于异常值。
(2)3σ原则
当数据服从正态分布时,根据正态分布的定义可知,距离平均值3σ之外的概率为:P(|x-μ|>3σ) <= 0.003 ,这属于极小概率事件。因此,当样本点距离平均值大于3σ,则认定该样本点为高度异常的异常值。
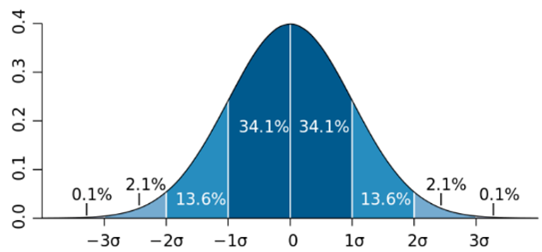
当数据不服从正态分布时,可以通过远离平均距离n倍的标准差来判定,n的取值需要根据经验和实际情况来决定。
(3)箱线图分析
箱线图提供了一个识别异常值的标准,即大于或小于箱线图设定的上下界的数值即为异常值,箱线图如下图所示:

首先,定义下上四分位和下四分位:上四分位设为U,表示的是所有样本中只有1/4的数值大于U。同理,下四分位我们设为L,表示的是所有样本中只有1/4的数值小于L。
那么,上下界又是什么呢?我们设上四分位与下四分位的插值为IQR(Inter Quartile Range),即:IQR=U-L,那么,上界为U+1.5IQR,下界为:L-1.5IQR。超出上下界的值,即为异常值。利用箱线图选取异常值比较客观,在识别异常值方面有一定的优越性。
操作方法:在R中,使用函数dotchart(),boxplot()实现绘制单变量散点图与箱线图;在Python中,使用matplotlib中函数scatter(),boxplot()实现绘制单变量散点图与箱线图。
【异常值处理方法】
在数据预处理时,异常值是否剔除,需视具体情况而定,因为有些异常值可能蕴含着有用的信息。异常值处理常用方法:
删除含有异常值的记录:直接将含有异常值的记录删除。优点:简单易行。缺点:在观测值很少的情况下,会造成样本量不足,可能会改变变量的原有分布,从而造成分析结果的不准确。
视为缺失值:将异常值视为缺失值,利用缺失值处理的方法进行处理。优点:可以利用现有变量的信息,对异常值(缺失值)进行填补。
平均值修正:可以前后两个观测值的平均值修正该异常值。
不处理:直接在具有异常值的数据集上进行挖掘建模。
三、缺失值
【数据缺失的机制】
Little和Rubin(1987)把数据缺失的机制分为三类:
1)完全随机缺失(missing completely at random, MCAR):所缺失的数据是完全随机的,缺失发生的概率既与已观察到的数据无关,也与未观察到的数据无关。这是一种比较理想的情况。
2)随机缺失(missing at random, MAR):数据的缺失不是完全随机的。缺失数据发生的概率与所观察到的变量是有关的,而与未观察到的数据的特征是无关的。这是一个比较严重的问题,在这种情况下,我们需要进一步检查数据收集过程,并尝试了解数据为什么丢失。例如,如果在一项问卷调查中,大多数人没有回答某个问题,他们为什么这么做,是问题不清楚吗?
3)不可忽略的缺失(non-ignorable missing ,NIM),亦称为非随机缺失(not missing at random, NMAR),也有研究者将其称为MNAR(missing not at random)。缺失数据不仅依赖于其它变量,又依赖于变量本身,这种缺失即为不可忽略的缺失。
【缺失值填充方法】
删除是最简单最直接的方法,很多时候也是最有效的方法,这种做法的缺点是可能会导致信息丢失。对于unknown值数量较少的变量可以选择删除。删除有缺失数据的样本,删除有过多缺失数据的特征。
多重插补是从单一插补的基础上衍生而来的。指给每个缺失值都构造m个替代值(m>1),从而产生了m个完全数据集。然后对每个完全数据集采用相同的数据分析方法进行处理,得到m个处理结果,然后综合这些处理结果,基于某个原则,得到最终的目标变量的估计。
多重插补可以分为三个阶段:对目标变量的估计;创建完整数据集;目标变量的确定。其中归关键的阶段为目标变量的估计,该阶段需要确定估计缺失值得方法,即缺失值事以何种方法或者模型被评估出来,该阶段直接影响统计推断得有效性。
Little, R.and Rubin, D.(1987) Statistical Analysis with Missing Data. John Wiley and Sons Publishers, New York.
备注:2020年3月11日,糖果之家“大数据与智能决策”讨论班(Seminar)在线开讲,本次讨论班以“数据预处理”为题,由博士生Tang Lin进行讲解,共有博士生和硕士生16人在线参加。
https://blog.sciencenet.cn/blog-34250-1230737.html
上一篇:非线性+网络:2020研究热点综述
下一篇:基于文本挖掘的新型冠状病毒肺炎诊疗方案演化分析