博文
读研秘技十六:完备的实验
 精选
精选
||
“你前面吹的牛,都要在这里一一实现。” -- 鲁迅没说过!
实践是检验真理的唯一标准,而对于科学研究来说,如果不是纯理论性的工作,实验就是检验理论与方法是否正确的唯一准绳。它不仅能帮助我们验证方法的性能,还能发现有意义的现象,以提出方法的不足和潜在的改进方向。而对于论文撰写来说,它也是帮助封闭论文整体逻辑的关键一节。
一、有无实验
没有实验的文章有两种。一种是纯理论性的,比如纯数学研究的,其成果只需要通过严格的数学证明即可被认可。还比如人工智能领域中,基于统计理论,目的就是为了证明学习模型与理想模型之间的距离或界的。这两种情况是可以不要实验的。另一种则是明明需要有实验来支持,却根本不做实验。在本应有实验的部分,只是简单的放个算法的操作界面。这种情况,往往是学生只想写篇文章混毕业,需要指导老师进行严格把关、做大的改进才行。
而多数工作呢,往往是理论和实验兼有。评审在审论文时,会顾及两者工作量的平衡。如果理论方面的创新比较大的话,通常情况下,评审对实验方面要求就不会太苛刻。即使文章只有一两个仿真实验,评审也不会因为实验少而拒稿。而如果创新小的话,则作者需要用相对更完整的实验来表明,这个创新是值得发表的。那么,在论文的实验部分,哪些是需要交待清楚的,哪些指标能做为评判标准,哪些又值得仔细分析呢?
二、实验细节交待
科学研究和实验的目的是要保证可重复性,因此各个细节都需要尽量说明清楚。
首先是数据的说明,需要明确实验用的数据或数据集的细节,如数据采集方式、采集时间、采集设备、数据的大小,使用的特征数量。另外, 实验用的数据集是否为公用的,也影响对论文贡献的评估。如在论文中,作者只在自建的数据集上进行了方法的评估,很容易让评审和读者觉得不具有可重复性和可信度。除此以外,数据集的选择也很重要。比如在人脸识别中,在现阶段应该尽可能选用大规模的数据集来进行评估,而非90年曾流行的ORL数据集(40个人,每个人10张人脸照片)。否则,评审从数据集的使用上就可以轻松判断出方法存在问题,导致快速拒稿。
其次是方法的比较说明。各种方法的参数设置情况、软硬件平台是否相同、方法是否为最新的、是否是目前已知文献的最佳性能,都应该交待清楚。如果需要在统一环境进行比较的,需要利用原文在共享网站如Github分享的代码来重新实现。为了提高引用率,多数作者会分享代码。如果找不到代码的,要么直接写信给作者去索取,要么自己按原文的伪代码来重写。
三、评判标准
要评判方法的有效性和效率,各行各业都有各自的一套标准。撰写实验报告时,需要根据自己研究方向的实际情况,以及广泛选择的评判标准来进行实验。尽量不要漏掉相应的评价准则,以避免被评审要求整改,从而延长审稿周期、浪费不必要的时间。
这里不准备枚举所有可能的标准,只讨论几个相对比较常用的标准及可能存在的误区。
1、预测性能是多数方法关心的指标,常用模型预测与真实值之间的差异来衡量,一般越小越好。当预测值是连续值时,可以表现为均方根误差(MSE)或均方绝对值误差(MAE)的形式。当预测值是离散值时,如识别人脸正确与否时,则表示成识别率、准确率或精度。为了检验实验的稳定性,往往需要对实验进行多次重复。重复的策略涉及到通过重新组合数据、重新训练模型等产生的变化 。然后,通过平均各种变化的预测结果来获得均值和围绕均值抖动的方差或标准偏差。均值和方差从统计意义反应了模型的预测精度和稳定性。
除了预测性能准确外,有时候还得提防模型把不对的错判成对的,对的判成错的。这两种错判导致的后果或代价是不同的。举例说,今年新冠病毒采用的核酸检测方法。如果把感染了的人错判成没有感染的,就是假阴性;反之是假阳性。而目前出现了两三次都没有确诊的情况,说明该方法在假阴性的指标上还比较高。另外,这两类误判的代价显然也是不同的。在现阶段,大家更希望能减少假阴性的情况。宁肯多确诊一些,也不要漏过一例。所以,在2020年2月13日,湖北省在采用CT来判断新冠肺炎后,确诊人数当天显著上升,达到14840例(含临床诊断病例13332例)。这就是宁肯假阳性多一些,也要确保没有病毒携带者在外面继续传染他人,疫情能够控制下来。

图1:假阳性(左,你怀孕了) 与假阴性 (右,你没怀孕) 示例
在综合考虑预测准确性和假阳性的情况下,还可以分析模型或方法从完全不允许假阳性到完全允许假阳性时,预测准确率的变化情况。理想情况下,在完全没有假阳性时,预测达到100%,此时的预测准确率变化就是从1开始的一条直线,如图2所示。
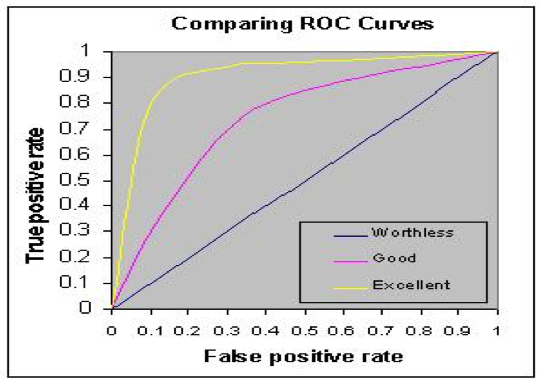
图2:识别率与(纵坐标)假阳性曲线(横坐标)示意图,三条曲线中,黄色的性能最好。
但多数情况,是远离面积为1的直线的某条曲线。通过计算曲线下覆盖的面积(常称为AUC,即area under the curve),我们就能比较不同预测方法在这两者之间平衡的统计性能。其结果,显然是越接近1,越好。除此以外,在预测性能指标上还有很多变种的标准,这里就不再赘述。
当不同方法性能相近时,比如A方法预测性能98.20%,B是98.15%。在差异比较小的情况下,评审专家有时会要求做显著性检验,以便确信这样的改进是显著的,比如p-值检验就是常用的显著性检测方法。但p-值检验依赖于先验信息这一特点,一直以来为不太喜欢贝叶斯学派的频率派所认可 [1]。比如增加实验次数就导致显著性检验发生变化的做法,频率派往往不太认可。极端情况,如某个新冠的新药,在前几次的测试中一直证明不了药物是显著有效的,但经过相同设置的多次临床实验后,就通过显著性检验了。如果碰到负责新药评价的是频率派的,那这个新药的上市路有可能就遥遥无期了。这一争论自贝叶斯派建立至今,已经持续 了250年,比病毒才被发现100年多一点要早得多。孰是孰非,要靠自己来判断。
2、代价 。一个决定的做出总是要付出代价的。时间换空间,空间换时间。一部分时间的牺牲换取另一部分空间的获得,一部分城市的管控换来了其它城市的安全,诸如此类。天下是没有白白掉下来的馅饼。所以,另一个大家想了解的指标是代价。
如果一个方法的预测性能上来了,那么代价是什么是需要报道的。如果是通过过于复杂、收敛极慢的优化获得的,也许这种代价就不一定合适。如果是通过依赖硬件的并行技术来获得提高的,只要价格上承受得起,大家就不会觉得有问题,比如通过广泛的、采用GPU来加速解决问题。另一种是通过大量增加数据量来实现提升。如果数据量可以通过便宜的人工智能标定、或者通过仿真的方式来获得,那么这种代价也是值得的。后两者在现阶段的人工智能研究中屡见不鲜,对深度学习的性能提升起了重要作用。
当然,也有反过来寻找代价的。即研究的原本目标和创新点就是要显著提升计算的速度或降低算法收敛的次数。那么,读者也很想知道,它是否在预测性能或相关指标上付出了代价,而这种代价是否值得。同时,在实验部分,论文也需要澄清算法的计算复杂度或实验上表现出的运算时间是多少,以帮助读者直观了解算法的实际表现。
3、参数的影响
对多数方法来说,创新是在已知方法基础上进行改进得到的。有的时候是A.1、A.2、A.3,有的时候是C=AB,有的时候是A+\lambda_1 B+\lambda+2 C。在复合模块引入较多时,评审和读者往往希望了解,到底哪个模块在性能改进上起到了关键性的作用。作者也应该在论文中做详细分析,找出到底是单个模块的作用,还是组合获得的效果提升。
另外,参数影响的实验摆放位置也需要注意。在撰写时,不妨把方法能获得的最好性能、以及与其他方法的比较首先报道出来。这样能给评审一个好的第一印象,知道该方法具有能与其他方法媲美甚至超越的性能。然后,在实验的随后部分,再逐层次地去做参数影响的分析,如执行深度学习流行的、通过分解模块看效果的消融实验。
4、主观评价标准。
除了定量评估的方法外,还有定性的评判在很多研究中也是必需的。如图像放缩的应用中,到底放缩后的图像是否和原图内容保持一致、失真是什么原因造成的(见图3);或如图像超分辨率的应用,放大后的图片在哪些位置比之前马赛克的图片更清楚、为什么?这都依赖于主观的定性评价。

图3:图像放缩的方法比较。左一:原图;其他为不同方法放缩的效果 [2]
比较普遍的做法是做用户调查(user study)。但这一调查在选择用户的时候和让用户评价的时候,应最大化其客观性。否则,找几个实验室的同学随便标一标,那如何能保证用户调查的结果是可信的呢?其次,用户的数量也不能少,否则不具备统计意义。
要达到这些要求,最合理的办法是进行双盲研究。比如新冠病毒的药物有效性测试,就需要用双盲来评估。首先要将病人随机分成若干组,一组不给药,只给安慰剂;另外几组则服用不同剂量的抗新冠病毒的药物。在临床试验过程中,受试者和参与试验的医生都不清楚服用的究竟是安慰剂还是正在测试的药物。按网上公开的报告来看,在两周时间后,再进行数据收集汇总分析,以确定药物是否有效,以及如果药物有效的话,剂量是多大。如果测试组与对照组相比,核酸检测呈阴性的比例显著增加或者病毒载量显然降低了,那就从临床试验上证明了此药的有效性,其它网络传言都不足为信。
类似地,在计算机视觉的图像放缩研究中,目标是为了保证任意放缩时,图像或视频里的重要目标如主持人身材不变胖或变瘦。当存在不同方法来获得图像缩放结果时,就需要引入主观评价的客观分析。具体的做法是,随机从不同算法获得的放缩图结果中随机抽取一定数量的图像对(可参考图3)。在不告知哪张图是哪个算法生成的前提下,让测试者评判好坏。这一过程可以通过网上有偿匿名填问卷的形式完成,比如利用Amazon Mechanical Turk平台。通过这种方法来分析,就能让主观评价的指标尽可能客观化。
四、洞察
实验章节的目的不仅需要验证算法的优越性,也需要作者能从实验结果中分析出一些有意义有价值的知识。一方面,这些知识能帮助论文形成逻辑上的自证。比如在论文介绍部分提到过的其它方法的不足,以及本论文提出方法的创新点,是否通过实验反映出来了。如果没有,那么需要回到之前的章节,重新调整论文的论调,保持逻辑上无漏洞,去除可能夸大宣传自己方法的内容。
另一方面,从这些知识中,也可能挖掘出新线索、发现新的问题或不足。新的线索可以为自己或感兴趣的读者提供潜在的研究方向。而存在的问题,如能合情合理的解释清楚,是能让评审或读者增加对论文的可信度。需要注意的是,在实验部分,如果只讲好的,对不足完全避开不谈时,有时也会让评审对方法的有效性产生怀疑。因为对于大多数应用性研究来说,终结者的算法并不存在,总有这样那样的问题存在。只要对问题的分析得合情合理,作者不必担心评审会以此来拒稿。
总之,实验的目的是要把评审和读者想知道的、置疑的都尽可能完整呈现。如果可以给出一些有新意义的解释和分析,那就是锦上添花。另外,也要注意,对实验的表述要尽可能客观,即使是主观评价也应想办法客观化。
一旦实验做到充分、可信、逻辑上能自洽且能与前文一致,那么就把论文的最重要一块完成了, 剩下的就是结论的撰写与参考文献的整理了。这两块还有哪些需要注意的呢?下回分解 !
张军平
2020年2月12日
参考文献:
1. Bradley Efron. Bayes’ Theorem in the 21st Century. Science, 340(7), 1177-1178, 2013.
2. Siqiang Luo, Junping Zhang, Qian Zhang and Xiaoru Yuan. Multi-Operator Image Retargeting with Automatic Integration of Direct and Indirect Seam Carving. Image and Vision Computing, vol. 30, 655-667, 2012.
延续阅读:
13. 读研秘技十三:引人入胜的开场白
12. 读研秘技十二:重灾区的论文摘要
11. 读研秘技十一:论文的选题与选题目
7. 读研秘技七:高徒出名师

张军平,复旦大学计算机科学技术学院,教授、博士生导师,中国自动化学会混合智能专委会副主任。主要研究方向包括人工智能、机器学习、图像处理、生物认证及智能交通。至今发表论文近100篇,其中IEEE Transactions系列21篇,包括IEEE TPAMI, TNNLS, ToC, TITS, TAC, TIP等。学术谷歌引用3600余次,ESI高被引一篇,H指数30。
出版科普著作《爱犯错的智能体》,曾连续24次推荐至科学网头条,曾五次进入京东科普读物新书榜前三名。关于人工智能发展趋势的观点曾被《国家治理》周刊、《瞭望》、《科技日报》、《中国科学报》等媒体多次报道。连载的《读研秘技》至今被科学网推荐头条14次。
https://blog.sciencenet.cn/blog-3389532-1218111.html
上一篇:读研秘技十五:创新 -- 从亨廷顿舞蹈病说起
下一篇:读研秘技十七:虎头蛇尾与画蛇添足的结论