博文
爱犯错的智能体--视觉篇(八):由粗到细、大范围优先的视觉
 精选
精选
||
第一次睁眼的时候,我还在娘胎,仿佛看到了一片红色,然后我又继续睡了;第二次睁眼时,已是出院的时候。我被母亲抱着坐在三轮车上,我看到一位白大褂医生站在一个拱形的门前向我们招手。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
人的记忆是非常奇妙的。可能有些时候记忆是先存储,再被自己重新分析的。也可能完全是错乱不可靠的,但通过不断的心理暗示后,结果自己都信了,如同引文中的一样。未出生的胎儿怎么会看到颜色,又知道颜色是哪种呢?
不过新生儿的视力刚开始时,确实能看到的也就是一片完全模糊不清的世界。原因有两个,一是眼睛的发育虽然已经基本完成,但眼球前后直径仍较短,晶状体的调节功能还没达到最优,视力只有成人的三十分之一,视角只有45度。二是大脑在此时还处在一个刚买回来的电脑主机状态,除了安装了后面会定期自动升级但几乎不会蓝屏的神奇操作系统外,应用程序还很少,硬盘也几乎是空的。因此,大脑还无法及时和准确处理从视觉神经元输送过来的信息,也无法从模糊的视觉信息中生成更清晰的“图像”。一切皆在学习的初级阶段。另外,人类的新生儿刚出生时是没有行动能力的。比如新生儿脖子的力量连头都撑不起,更不用说转动了。新生儿的四肢也根本不能支持其独立行动。这些都使得新生儿在刚出生时,只能看到、听到、学习到有限的信息。
发育到1个月左右时,听觉基本就发育成熟了,但视力仍然处在近视阶段。新生儿能看清物体的距离最多15到30厘米,而能集中注意力观察的时间不超过5秒。3到4个月后,能看清的距离延长到75厘米,平均视力仍仅为0.1。新生儿也能控制自己的头的转动了,所以,可学习的信息量长了不少。据统计,一般到6-8个月后,新生儿的视力才会和大人一样,能基本看清楚。但看到的内容,从已知的文献来看,会如同引子中看到的白大褂一样,只是一些外在轮廓的印象。正常情况下,儿童的视力在5周岁时发育完全,视力达到1.0或以上。
从进化角度来看,如果新生儿是独立在野外成长,这么缓慢的视力发育似乎不符合优胜劣汰原则的。作为对比,小鹿生下来几小时内就得睁开眼睛、学会走路。所幸地是,与小鹿不同,新生儿的父母庇护要强大得多,所以不会立刻走路、眼睛一片花白也没关系。那么,这种拼爹式的视觉发育对人的智能有何益处呢?
当新生儿最初的视力非常弱时,多数情况下能看到的只有物体的整体结构,对细节的抓取和记忆能力则还不具备。同时,大脑的视觉中枢系统在建构的过程中,对相同目标的反复学习和再认识,应该多会以最初模糊知觉形成的认知原型为基础来提升,而不应建立在对先前的经验的全盘否定上。随着视力的提高和大脑发育的继续完善,大脑会逐渐丰富各个认知原型的细节,从而获得对目标粒度更丰富的认识,直至稳定。这一视觉发育过或多或少与认知心理学中常被提及的大范围优先理论相关,也与计算机视觉中常常用到的由粗到细(Coarse-to-fine)框架很相似。
一、异曲同工:由粗到细与大范围优先
与近代知觉研究中占统治地位、强调视知觉过程是从局部到整体的初期特征分析的理论不同,“大范围优先”假设强调全局特征的认知要优于局部特征,最早是Navon于1977年提出来的[1, 2] 。直观来说,就是“先看到森林,再看到树”。其观点通过一组认知实验进行了验证。粗略来讲,他将若干小的字母拼成一个大的字母,大小字母可以相同或不同,如图1。通过测试者对大小字母辨别反应时间的判断,他发现在多数情况下,辨识大字母的反应时(Response Time)要短于小字母。尽管在实验细节上,后来的研究形成了诸多的变化和新的发现, 但并没有完全推翻Navon强调的“整体优先”观点。而对此现象的解释,众说纷纭。如有借鉴格式塔心理学的对称性、平行性、封闭性来解释整体认知性质的,而中科院院士、著名认知科学家陈霖也提出了“大范围优先”的拓扑性质初期知觉理论[3]。但因为某些情况下小范围也具有这种性质,目前似乎还没有令大家都满意的答案。
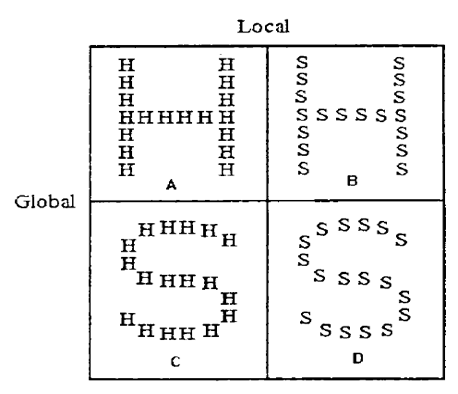
图1 Navon关于大范围优先假设使用的复合刺激图形 [2]
不过,如果从视觉发育的角度来看,这种大范围优先的策略也许多少与人类的视觉发育机理有些关系。因为最初的弱视,人类只能看清楚目标的大致结构或轮廓,因此必须要根据这些结构或轮廓来形成对目标的辨识。试想当人类看到捕食者如豹子的时候,只根据轮廓这一整体特征就能快速辨识豹子,显然更便于人类避免危险。如果等他仔细把豹子的各项局部特征如纹理、脸部特征、毛发长短等分析完成,再决定是否为豹子和要逃跑时,可能已悔之晚矣。另外,如果一开始视力就是非常完善的,一来刚混沌初开的大脑可能会因接受的信息太多,无法处理,导致宕机;二来只看轮廓,大脑分析消耗的计算资源和能量都小,因此形成辨识的时间会短,更有利于生存。因此,大范围优先的策略能帮助形成对目标的快速判断,而不需要大脑进行不必要的、深层次的分析。
无独有偶,计算机视觉或人工智能领域也有着异曲同工之妙的策略。
一是由粗到细的策略。这一策略最早见于90年代初期的人脸检测算法中。那时,CPU刚刚到486的水平,想玩游戏都得拿个容量1.2M的8寸软盘去拷贝,和现在算力和容量都很强大的计算机相比简直就弱爆了。如果人脸图像分辨率稍微高点,就很难做到高效检测。要解决这一问题,Yang和Huang提出了由粗到细的方案[4]。具体来说,就是先把人脸图像大小缩小64倍(长宽各8倍,也称为降采样)。缩小后的图像直接放大回原图大小的效果就是马赛克了。虽然马赛克的图像,人看也不清楚内容是什么,但从图像像素光强的分布来看,可以考虑规则“人脸的中心部位有四个格子(Cell)具有基本一致的强度”。这一规则可以用于初筛潜在的人脸区域。再根据人脸上眼睛和嘴巴的固有关系,可以继续做进一步的筛查。完成候选区域筛查后,再回到原始图像上,从选好的候选区域中根据原始像素来查找真正的人脸。由于降采样这一步将人脸缩小了64倍,且规则的搜索不需要执行复杂的浮点计算。于是,这一由粗到细的人脸检测算法,在当时算力很弱的环境下,也能非常高效地完成人脸检测任务。如果不考虑人类视力发育需要的时间,由粗到细和人的视觉感知中的整体到局部的策略是类似的,也可以看成是一种结构或大范围优先的策略。

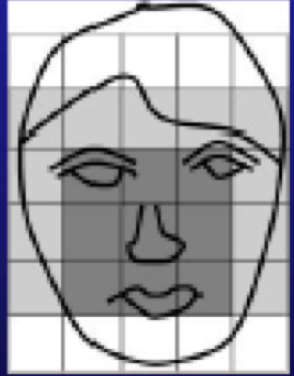
图2: 由粗到细的人脸检测算法;左:子采样效果;右:人脸灰度规则[4]
另一个相关的是金字塔策略。众说周知,金字塔在能量收集上有着神奇的能量。所以,计算机视觉和图像处理领域的科学家们也喜欢在处理计算机视觉任务时,用它能来收集比单幅图像更多的能量信息。比如,在做图像压缩时,大家喜欢把图像缩小一倍,然后再用原图减去缩小后插值放大的图,得到图像的残差信息。再把缩小的图继续缩小一倍,然后与之前缩小的图相减,得到缩小图像的残差信息。迭代下去后,可以得到一组持续缩小的残差图像。因为每次图像都缩小二倍,叠起来看的话,就像是一个金字塔。由于残差的像素灰度或强度值往往比较集中,所以就比较容易找到短的编码来刻画这些频繁出现的值,因而能帮助提高压缩编码的效率[5]。还有将金字塔策略用于高阶特征抽取的,如深度学习之前流行的SIFT(Scale-Invariance Feature Transform)算子[6]和随后改进了速度的SURF(Speeded Up Robust Features)算子[7]。这两种算子都采用不同尺度的高斯(Gaussian)核来模糊图像,以提取不同尺度的特征。SIFT算子是在金字塔式的图像上提取特征,而SURF则把特征提取算子本身做成了金字塔。尽管没有涉及大范围优先的思想,但这两种多尺度的特征提取技术或多或少体现了由粗到细的思想。
即使现在人工智能中很流行的生成式对抗深度网络,也不免俗套地将图像金字塔技术嫁接在该网络上,提出了金字塔生成对抗网,以便能生成更为精细的图像[8]。
这些都表明了由粗到细、整体与局部特征相结合、大范围优先的策略,在人工智能的多数相关应用中是有实际意义的。
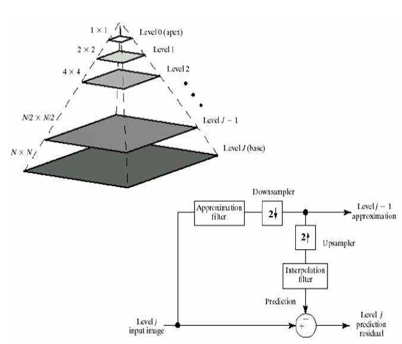
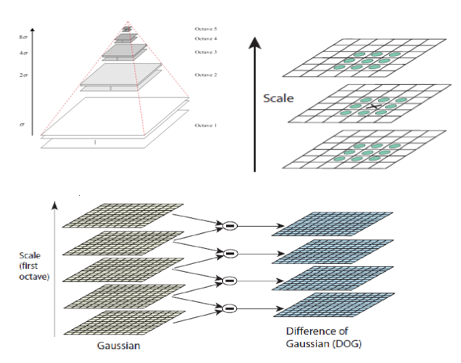
(a) (b)
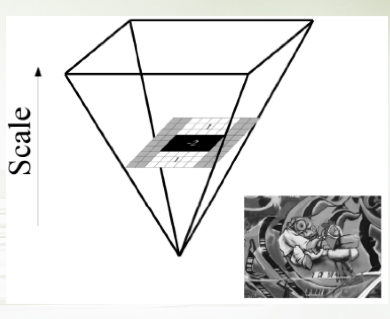
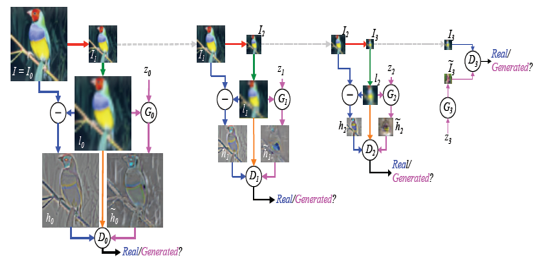
(c) (d)
图3:计算机视觉、图像处理中的金字塔策略;(a):图像压缩[5];(b):SIFT算子[6];(c):SURF算子[7];(d):金字塔生成对抗网[8]
二、由细到粗和模糊的艺术
模糊到清晰是一种由粗到细,体现了大范围优先的思想。但如果反过来,从清晰到模糊,有时候会带来一些奇妙的错觉。人视觉的模糊程度不仅会影响认知,也会影响人对图像内容的评判,如图4左。这张图中有两个人物,爱因斯坦和玛丽莲·梦露。不近视的能看到爱因斯坦,近视的戴眼镜看到的是爱因斯坦,取下眼镜看到的是梦露。而图4右是一幅满是马赛克的图片。近视眼的同学不妨把眼镜取下来,仔细看看,是不是感觉图像变清楚了?


图4 左:爱因斯坦/玛丽莲·梦露;右:马赛克图像(网图)
这都是因为取下眼镜后,人的大脑会对视觉系统输入的信息进行自动平滑。平滑后的图像就没有原马赛克图像那么明显的边缘,结果视觉上反而会觉得更清楚了。
这种平滑不仅能让人类视觉产生“清晰”的错觉,有的时候它还能帮助提升目标识别的性能。举例来说,根据行人走路姿势来识别行人身份的研究。我们曾经发现,当把行人步态轮廓图缩小4倍再放大时,其识别效果反而会比直接在原图上好。后来我也和几个朋友交流过,他们发现在人脸识别中也存在类似的现象。为什么把图像缩小再放大后,会帮助提升性能呢?我们给出的一种解释是,原始步态或人脸图像包含的噪声相对较多,缩小再放大需要经过一个插值平滑过程。有可能这个平滑过程帮助去除了图像中影响判别的噪声,因此导致识别性能提升了。但我们也只是猜想,最终也没有谁认真从理论上去分析过真正的原因。
除此以外,模糊的视觉能让人从不同的视角去看世界,它对艺术也是有重要贡献。据说法国印象派开创先河的领袖式人物莫奈是近视眼,于是画出来的油画都比较模糊。虽然模糊,却有不同的效果。如果摘下眼镜看他们的画,如印象派发展史上有领导地位的人物之一、法国画家皮埃尔-奥古斯特·雷诺阿于1876年创作的《煎饼磨坊的舞会》(图5),就能从平面图像中感受到强烈的立体感。有人戏称,印象派是专属近视眼的独特风景。

图5 《煎饼磨坊的舞会》
不难看出,视觉的发育是个有趣的过程。他影响了人的视知觉系统,影响了人在不断认识、学习和记忆事物的策略,甚至于大脑视觉中枢对原型的存储方式。他与认知心理学关心的大范围优先性可能也存在某种关联。理解视觉的发育,也许就能更好地理解人工智能了。
参考文献:
1. Navon D. Forest Before Trees: The Precedence of Global Features in Visual Perception. Cognitive Psychology, 1977, 9(3): 353-383.
2. 韩世辉, 陈霖. 整体性质和局部性质的关系 -- 大范围优先性. 心理学动态, 1996, 4(1): 36-41.
3. Chen L. Topological Structure in Visual Perception. Science, 1982, 218(12):699-700.
4. Yang G., Huang T. Human face detection in a complex background. In Pattern Recognition, 27(1):53 – 63 (1994).
5. Gonzalez R. C., Woods E. R., Digital Image Processing (Third Edition). 2017. 电子工业出版社
6. Lowe D.G. Distinctive Image Features from Scale-Invariant Keypoints. International Journal of Computer Vision, 2004, 60(2): 91-110.
7. Bay H., Tuytelaars T., Van Gool L. SURF: Speeded Up Robust Features. ECCV 2006.
8. Denton E., Chintala S., Szlam A., Fergus R. Deep Generative Image Models Using a Laplacian Pyramid of Adversarial Networks (LAPGAN). NIPS 2015.
9. Zhang J., Pu J., Chen C., Fleischer R. Low-resolution Gait Recognition. IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cybernetics, 40(4): 986-996, 2010.
张军平
2018年9月30日星期日
�
延伸阅读:

张军平 ,复旦大学计算机科学技术学院,教授、博士生导师,中国自动化学会混合智能专委会副主任。主要研究方向包括人工智能、机器学习、图像处理、生物认证及智能交通。至今发表论文近100篇,其中IEEE Transactions系列18篇,包括IEEE TPAMI, TNNLS, ToC, TITS, TAC等。学术谷歌引用2700余次,ESI高被引一篇,H指数27.
https://blog.sciencenet.cn/blog-3389532-1137917.html
上一篇:爱犯错的智能体 -- 视觉篇(七):眼中的黎曼流形
下一篇:慢养的诺奖:自由而无用