博文
[转载]R语言制作热图的一个小实例
||| |
热图(heatmap)用不同的颜色和颜色的深浅来展示数据之间的差异,直观、美丽、大方,深受科研工作者的喜爱,尤其是转录组类的文章里,几乎必有一幅热图用来展示差异表达基因。很多工具都可以完成热图的制作,比如我们最常使用的excel;还有一款比较好用的制作热图的工具是CJ大神开发的工具TBtools,在公众号生信札记有比较详细的教程,感兴趣的可以自行搜索相关教程;今天这篇文章主要介绍利用R语言的 pheatmap 包和 ggplot2 包制作热图的简单小例子。pheatmap是R语言中专门用来制作热图的工具包;ggplot2是R语言中最常用的可视化工具包。R语言中还有一个专门用来绘制热图的工具包ComplexHeatmap,功能比pheatmap强大,帮助文档非常详细,感兴趣的可以自行查阅帮助文档,在这篇文章中就不做过多介绍。
1、利用pheatmap制作热图
这部分内容主要来自教程 https://flowingdata.com/2010/01/21/how-to-make-a-heatmap-a-quick-and-easy-solution/。原文用到的数据集:NBA basketball statistics from last season。可是回头再看这篇教程的写作时间已经是2010年了。“上一个赛季(last season)”那岂不是要追溯到2008-2009赛季了?那个时候科比还在,卡特未老,麦迪虽已巅峰不在,干拔跳投却依旧销魂;艾弗森虽然远赴掘金,但那份桀骜与坚持依旧感动着无数球迷;那时候纳什还在太阳,小斯还是劲爆的小霸王,再加上防守悍将马里昂,即使是与拥有GDP的马刺也能大战上六场;那时的姚明带领火箭闯进了季后赛第二轮,并与当年的总冠军湖人队大战了7场 ,同时还上演了王者归来的震撼表演;那时的隆多还在绿军,风城之子才刚刚在芝加哥联合中心球馆绽放...... 那是最好的时代 -- It was the best of times.

哈哈哈……好像有点扯远了,今天的主题是学习R语言制作热图的,不是来怀旧的哈!
1.1 读入数据、查看数据维度、查看变量名称
nba <- read.csv("http://datasets.flowingdata.com/ppg2008.csv", sep=",")
dim(nba)
colnames(nba)
数据集包括21个变量,总共50个样本,各个变量的含义如图二

接下来通过散点图添加标签的方式看一下数据集里都包括哪些人
Name<-gsub(" ","\n",nba$Name)
df<-data.frame(A=sort(rep(1:10,5)),B=rep(1:10,5),Name=Name)
head(df)
library(ggplot2)
ggplot(data=df,aes(x=A,y=B))+geom_point()+
geom_text(aes(label=Name),vjust=1.1)+
xlim(0,11)+ylim(0,10)+theme_bw()+
labs(x="",y="")

韦德、科比、诺维斯基。。。 满眼都是青春的样子呀!
小知识点
gsub()函数用来将球员名字中的空格替换为换行符,第一个位置是要被替换的字符;第二个位置是替换为的字符;第三个位置是要替换的内容。
1.2热图制作
1.2.1数据格式转换
首先对数据简单处理,包括将数据按照场均得分重新排序;行名改为球员的名字;去掉数据中的第一列;然后把最初读入的数据框转化为pheatmap()函数要求的矩阵格式
nba <- nba[order(nba$PTS),]
row.names(nba) <- nba$Name
nba <- nba[,2:20]
nba_matrix <- data.matrix(nba)
1.2.2热图制作
单一函数出图
library(pheatmap)
pheatmap(nba_matrix)

接下来通过参数调整细节,包括去掉行和列的聚类(因为这组数据里没有没有太大的意义,转录组数据的如图聚类通常保留)、对数据按照列进行标准化、去掉图例、改变配色等,还有其他参数调节可以通过help(package=”pheatmap”)函数查阅帮助文档
pheatmap(nba_matrix,cluster_cols = F, cluster_rows = F, col=cm.colors(256), scale="column",
legend = F)

这里遇到的问题:原教程中输出的图片是按照场均得分从大到小由上往下依次排列的,自己重复出来的是由小到大排列,如何更改顺序暂时还不知道如何实现。
2、基于ggplot2绘制热图(数据集同上)
ggplot2绘制热图使用到的函数是geom_tile()函数,简单理解就是根据位置坐标添加色块
2.1 geom_tile()函数简单小例子
library(ggplot2)
library(ggpubr)
p1<-ggplot(data=df,aes(x=A,y=B))+
geom_point()+ggtitle("geom_point()")
p2<-ggplot(data=df,aes(x=A,y=B))+
geom_tile()+ggtitle("geom_tile()")
ggarrange(p1,p2,ncol=2,labels=c("A","B"))

2.2 绘图
这部分内容主要来自教程 https://www.r-bloggers.com/ggplot2-quick-heatmap-plotting/
代码
library(plyr)
library(reshape)
library(ggplot2)
nba <- read.csv("http://datasets.flowingdata.com/ppg2008.csv", sep=",")
nba$Name <- with(nba, reorder(Name, PTS))
nba.m <- melt(nba)
nba.m <- ddply(nba.m, .(variable), transform,rescale = rescaler(value))
p<-ggplot(nba.m, aes(variable, Name)) +
geom_tile(aes(fill = rescale), colour = "white") +
scale_fill_gradient(low = "white", high = "steelblue")+
theme_grey(base_size = 9) +
labs(x = "", y = "") +
scale_x_discrete(expand = c(0, 0)) +
scale_y_discrete(expand = c(0, 0)) +
theme(legend.position = "none",axis.ticks = element_blank(),
axis.text.x = element_text(size = base_size *0.8, angle = 330, hjust = 0,
colour = "grey50"))
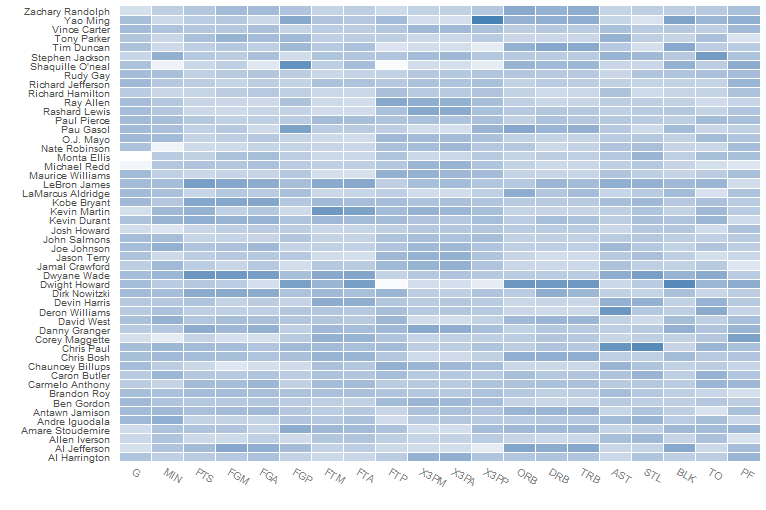
melt()、rescaler()函数来自reshape包
ddply()函数来自plyr包
这三个函数的用法自己还不是非常明白;印象里这两个包已经比较老了,应该是已经有新的包替代了
相对于原教程改动的地方
原文rescaler()函数少了一个字母r
theme_blank()和theme_text()函数已经不再使用,相应的替换为 element_blank() 和element_text()
小知识点
ggplot作图底部通常不贴着x轴,比如柱形图
df<-data.frame(A=sample(1:10,5),
B=LETTERS[1:5])
ggplot(data=df,aes(x=B,y=A))+geom_bar(stat="identity")
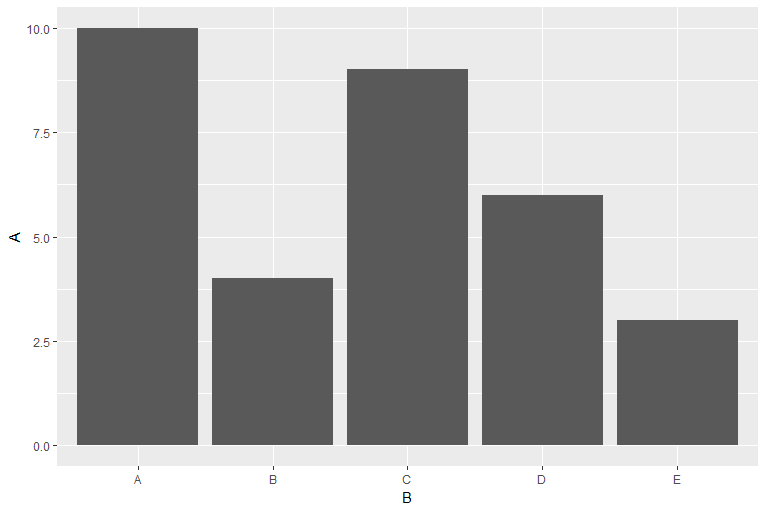
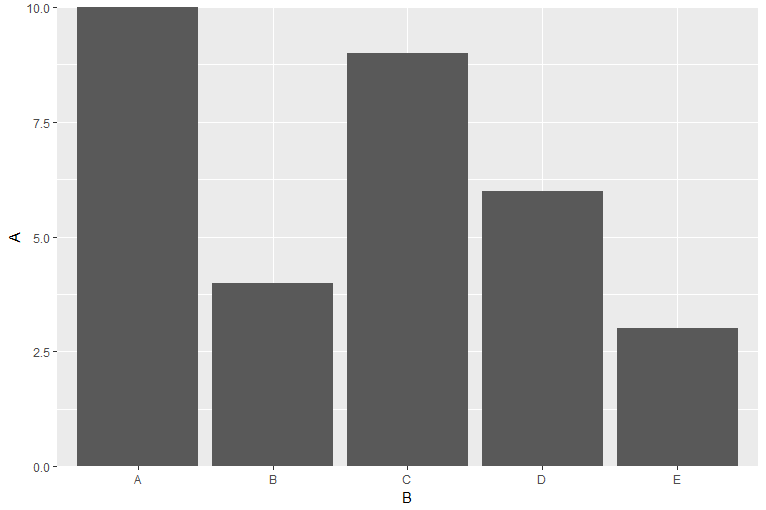
如果希望柱形图贴着x轴,可以使用scale_y_continuous()或者scale_y_discrete()函数
ggplot(data=df,aes(x=B,y=A))+
geom_bar(stat="identity")+
scale_y_continuous(expand=c(0,0))
好啦,今天就到这了啦!祝大家生活愉快,试验顺利!
转自生信草堂公众号,已授权
生信草堂
浙大生信博士团队倾力打造的一个科研人员学习交流的公众微信平台。我们致力于科研社区服务,分享前沿的科技进展,提供生信分析方法,解读经典分析案例,公众数据库的挖掘和临床数据统计分析。在此我们欢迎各位的加入!
加微信bioinformatics88拉您进生信交流群

https://blog.sciencenet.cn/blog-3353749-1168594.html
上一篇:[转载]16S测序分析系列(一)菌属丰度表获取
下一篇:[转载]寻因溯果 — — 浅谈孟德尔随机化及其在GWAS研究中的应用