博文
矩阵乘法的优化
|
矩阵乘法的定义是十分简单的,如果按照数学上的定义,可以写出下面的程序:

从计算机专业的角度来看,上面的代码是幼稚的。主要表现在:B[k][j]读取内存中的数据,是不连续的。在最底层的循环中,随着k不断加1,B[k][j]不断的在内存中跳跃。这会引起缓存命中率低,循环程序不断的把内存转移至缓存,引起效率降低。
在我的台式机上,两个1000阶矩阵相乘,需要用时8.5s(用的编译器是g++ -O3)
充分利用计算机系统的特性可以大幅度提高程序性能,在卡内基梅隆大学的镇校神课《深入理解计算机系统》里面,给出一种方法,仅仅改变循环的次序,就可以大幅度提高性能,代码如下:
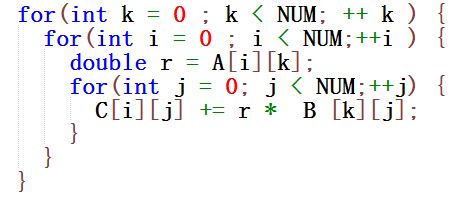
首先,最内层的循环,随着j加1,C[I][J]和B[k][j]都是每次只加1,这符合空间局部性的原理,也就是说,内存每次读取都是一个接着一个的来,没有大幅度跳跃。其次,A[i][k]在中间层循环是跳跃的,但是中间层执行的没有底层那么多,而且我们把A[i][k]赋给了局部变量r,在编译器生成汇编代码的过程中,局部变量r应该由CPU寄存器存储,最底层循环程序读取寄存器的时间几乎可以忽略不计的。
在我的台式机上,同样的两个1000阶矩阵相乘,只需要用时1.57s,是不是很惊人,代码行数几乎完全一样,只改变循环的次序,就有这么大性能差异。
为了进一步提高性能,可以将矩阵分块,每次计算一部分内容。这样计算时,CPU可以把更规整的把部分内存搬到缓存中,提高缓存命中率。下面是我增加分块后的代码:
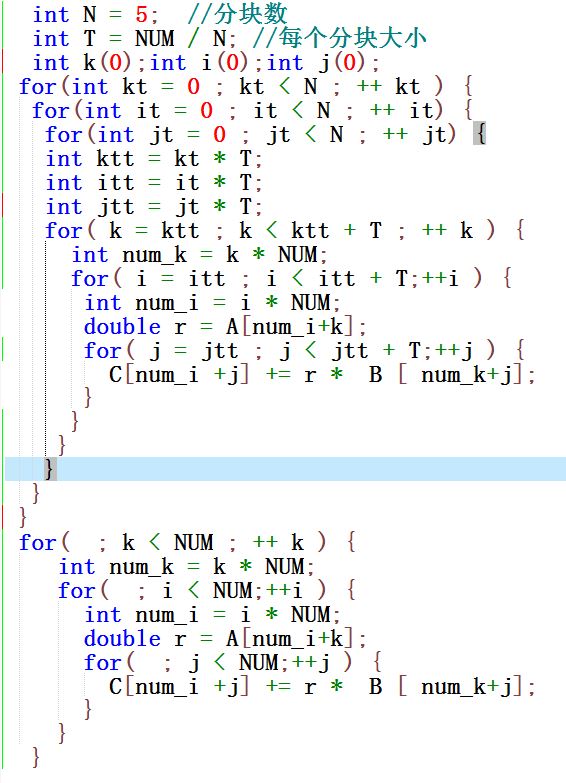
在我的台式机上,同样的两个1000阶矩阵相乘,只需要用时0.73s,相比于最开始的幼稚程序,性能已经提高1个数量级了,但代码行数并没有增加太多。可以得出结论:对于计算机体系结构有所了解的程序员写的程序,与菜鸟程序员相比,性能可能有相当大的差距,虽然工作量可能差不多。
对于矩阵计算,有成熟的库可以使用,完全没必要从头自己写代码。对于高性能的 BLAS实现(线性代数基础计算)来说,其用到的技术远远比本文复杂,需要在分块计算中减少时间复杂度(Strassen算法),需要自动或手动编写大量的汇编程序。在我的台式机上,OpenBLAS执行两个1000阶矩阵相乘,可能只需要用时0.1s.
但不管怎么说,为了写高性能程序,学习计算机系统的知识绝对有益。
https://blog.sciencenet.cn/blog-3316223-1085257.html
上一篇:谈谈信号监控
下一篇:机器学习对继电保护的影响
全部作者的其他最新博文
- • 工程师应该补充的知识
- • 对于控制理论的几个想法
- • 复杂系统与简单界面
- • 工业系统中的日志
- • 现代C++的定位、设计原则与编程范式
- • 哲学与电力系统