博文
python爬取aspx动态页面的基本思想。
|||
最近要统计市里建筑企业的基本信息,人工数个数,真是很伤眼睛啊。再说人工数太low!!
scrapy 还不是肯熟悉框架,还是用最笨的requests 慢慢弄,虽然慢但自由灵活。
以山东省建筑特种作业查询网为例
URL:http://124.128.19.214:81/sztzzy/Login/SelectCert.aspx
目标:通过输入企业名称完成查询,并对数据进行清洗统计。
在chrome中打开页面,开启开发者页面。一共存在6条页面文件。
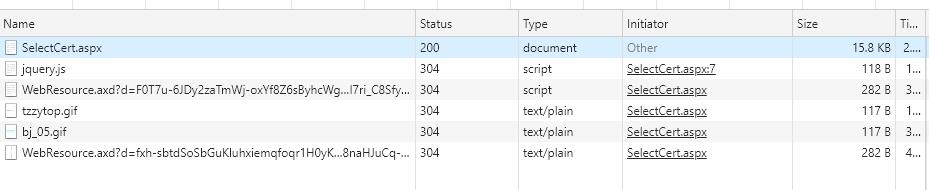
其中后缀gif的两个文件不用看。selectCert.aspx页面中存有查询页面的基本信息。唯一感到不解的是两个web资源的文件是什么,暂时不用管稍后处理。
其中header的基本信息:
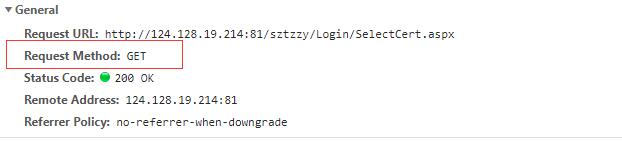
requests 方式采用Get ,返回的status Code 为200 。
其他headers信息:
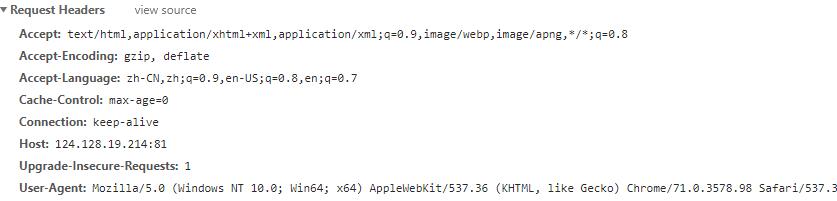
此时选择查询企业

进行查询
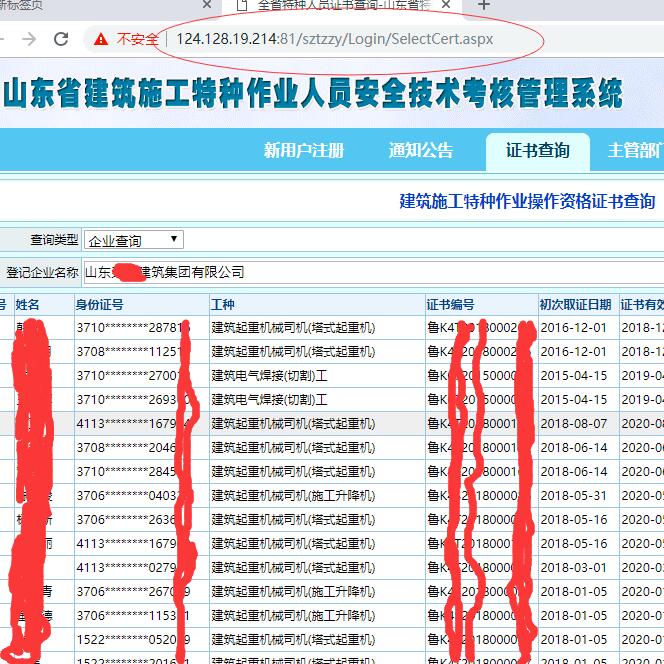
页面出现信息表格,但是网页的URL不会改变。
但是应当注意到开发者模式下多出一个网页文件。
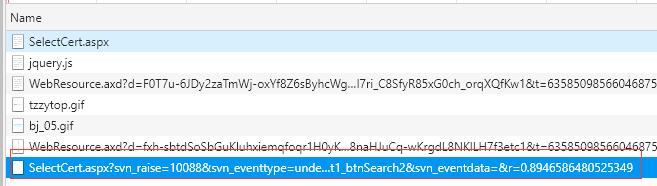
打开网页中基本信息,header信息:

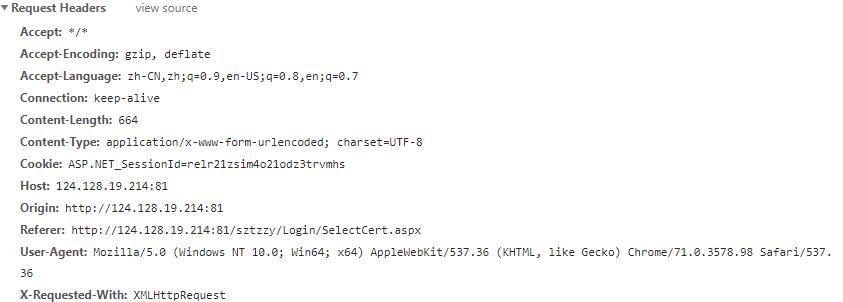
还有新增的Query string parameter

还有新增的form data信息。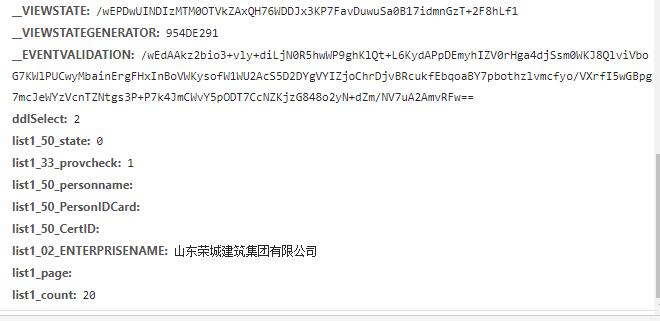
再打开页面预览一下,

这就是html格式unicode编码。到现在知道数据是在哪了,接下来就是搞懂数据传输机制。
首先打开初始页面,读取content,其中大部分内容为设置页面的颜色,按钮的控制等基本内容,同时包含网页和服务器的基本信息。
首先是viewstate信息。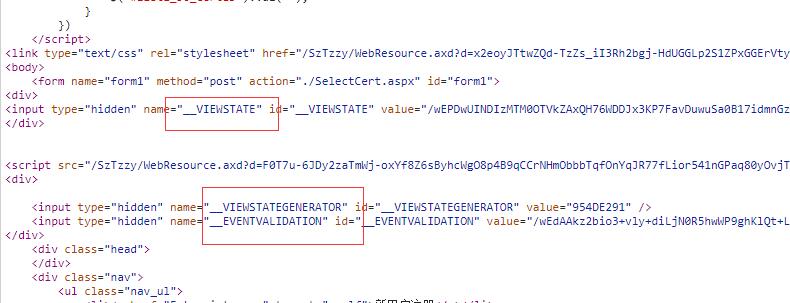
同时继续分析页面代码:
发现得到查询类型方面的下拉菜单控件的信息。
即企业查询时 ddSelect=‘’2“
其他信息如页码信息仍需继续分析,太多了不赘述。
#下面解析post网址问题,因为随着对页面按钮的操作,Post所使用的URL 是动态变化的,但是变化的规律是什么呢?我们则需要分析前面提到的WebResource 页面,通过分析其内部代码,以及网页测试,找到网页URL生成规律。
最后根据get返回的viewstate等信息以及cookie 信息,把页面请求信息,以post的方式发送到指定的URL,返回得到的数据可以通过beautifulSoup进行解析,配合编码转译、正则表达式进行有效信息的提取、读取后面的页码信、最后根据条件生成Framedata数据,方便查询利用。
https://blog.sciencenet.cn/blog-3314854-1156540.html
上一篇:python threading多线程崩溃问题
下一篇:SMOS ZIP(DBL)数据读取方式说明(二)