博文
美国工程院院士Dimitri P. Bertsekas: 基于特征的聚合与深度强化学习
|
近日, 美国工程院院士、麻省理工学院(MIT)教授Dimitri P. Bertsekas在IEEE/CAA Journal of Automatica Sinica发表了综述“Feature-Based Aggregation and Deep Reinforcement Learning: A Survey and Some New Implementations”。在这篇31页的综述中,Bertsekas教授介绍策略迭代的发展,总结近似策略迭代方法相关问题,回顾了基于神经网络的近似策略迭代的核心思想。
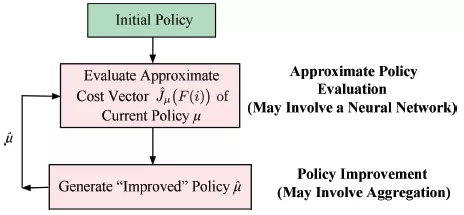
Bertsekas教授讨论了有限状态下马尔可夫决策问题近似解的策略迭代,特别是基于特征的聚合及其与深度强化学习的联系,提出将深度神经网络的特征提取能力与聚合提供的非线性近似可能性相结合的方法。文中归纳了基于聚合的近似动态规划与深度强化学习方法,引入初始问题状态的特征,构建了一个聚合马尔可夫决策问题,使其满足状态与特征相关条件,并讨论该类型聚合的性质和可能实现。提出了策略改进方法的新思路:将基于特征的聚合与利用深度神经网络等的特征构建相结合。由于聚合的动态规划特性及非线性基于特征结构的使用,相比基于神经网络的强化学习提供的特征线性函数,聚合后的特征非线性函数可使策略的代价函数得到更精确近似,从而产生更有效的策略。
文章结构
1. Introduction
1.1 Alternative Approximate Policy Iteration Methods
1.2 Terminology
2. Approximate Policy Iteration: An Overview
2.1 Direct and Indirect Approximation
2.2 Indirect Methods Based on Projected Equations
2.3 Indirect Methods Based on Aggregation
2.4 Implementation Issues
3. Approximate Policy Iteration Based on Neural Networks
4. Feature-Based Aggregation Framework
4.1 The Aggregate Problem
4.2 Solving the Aggregate Problem with Simulation-Based Methods
4.3 Feature Formation by Using Scoring Functions
4.4 Using Heuristics to Generate Features - Deterministic Optimization and Rollout
4.5 Stochastic Shortest Path Problems - Illustrative Examples
4.6 Multistep Aggregation
5. Policy Iteration with Feature-Based Aggregation and a Neural Network
6. Concluding Remarks
引用格式
D. P. Bertsekas, “Feature-based aggregation and deep reinforcement learning: asurvey and some new implementations,”IEEE/CAA J. Autom. Sinica,vol. 6, no. 1, pp. 1-31, Jan. 2019.
� �
�
Dimitri P. Bertsekas, 麻省理工学院(MIT)工程与计算机科学系教授,美国工程院院士,研究领域涵盖优化、控制、大规模计算和数据通信网络等,h-index为90,出版专著16部,其中一些被用作麻省理工学院课程的教科书。获INFORMS杰出研究奖(运筹与计算机科学交叉领域,1997年),希腊国家运筹学奖(2000年),美国控制协会 John R. Ragazzini教育学奖(2001年)。
注:论文介绍由JAS编辑整理摘译,如有疏漏欢迎指正
![]() Feature-based aggregation and deep reinforcement learning asurvey and some new i.pdf
Feature-based aggregation and deep reinforcement learning asurvey and some new i.pdf
网站:
http://ieeexplore.ieee.org/xpl/RecentIssue.jsp?punumber=6570654
www.ieee-jas.org
Blog: http://blog.sciencenet.cn/?3291369
Twitter: IEEE/CAA Press
Facebook: Ieee/Caa Press
投稿:https://mc03.manuscriptcentral.com/ieee-jas
Email: jas@ia.ac.cn
Tel: 010-82544459,010-82544746
微信:JAS自动化学报英文版

https://blog.sciencenet.cn/blog-3291369-1140955.html
上一篇:《自动化学报》44卷9期网刊已经发布, 敬请关注, 谢谢
下一篇:控制系统可诊断性的内涵与研究综述